基于网络编码的多信源组播通信系统,包括源代码,原理图等
便调试和后续的进一步研究。
2.4系统实现的整体设计方案说明
2.4.1 系统拓扑图及说明
如图2.4-1所示,是拟采用的组播通信网络的拓扑图:
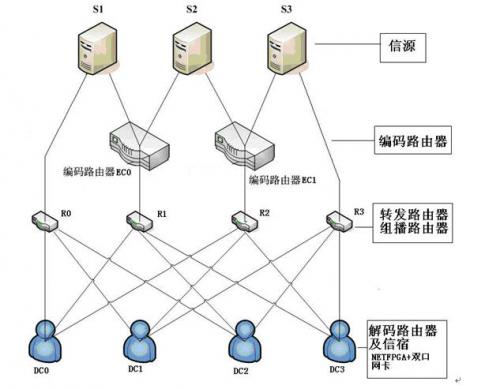
图2.4-1基于网络编码组播的网络拓扑图
说明:为了易于在工程上实现,将网络编码路由器分为编码路由器EC(Encoding router)和解码路由器DC(Decoding router),分别专门负责编码和解码。具体讲,如图1所示,信源S1,S2,S3发送数据包,编码路由器EC0和EC1负责将接收到的数据包以随机的系数进行线性编码后发送给组播路由器R,注意,这里的组播路由器更准确地说是转发路由器,因为它的功能只是将收到的数据包转发到其三个输出端口,而没有IGMP(组播管理)和相应的组播路由功能。当然,我们也可以直接在EC上实现转发的功能,增加R的原因是考虑到NetFPGA端口数量的限制(每块NetFPGA只有4个端口)。解码路由器DC接收编码的数据并解码,并将它发送给下游的信宿主机,在这里,由于PC数量的限制,我们使用双口网卡可以将解码路由器和信宿放到同一台主机上,这对网络性能的测试和实现没有任何影响。
2.4.2编码策略与方案
作为一种编码结构的提出,我们将编码只限于不同信源数据包之间,暂不考虑信源包内部编码。相同信源的数据包之间分"代",以便在解码时区分信息先后顺序[32]。不同信源的包之间不区分代的概念。
定义:为了讨论的方便性和简洁性,我们将信源S1的第1代记为S(1,1),信源S2的第3代记为S(2,3),……依此类推。依据包头和缓存,每个信源的代的编号从0开始,至1023结束,即信源n的最大的代编号为S(n,1023)
在编码路由器EC上对不同信源的IP数据包进行编码,编码系数矢量随机选择,编码方法是线性编码。例如,在上图中的编码路由器EC0,设两个链路的输入的全局编码向量为:in(e)= 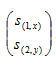 ,
,
由于只有两个信源之间的编码有且只有一条边输出,则本地编码向量为(α β),依据文章[33]的公式:
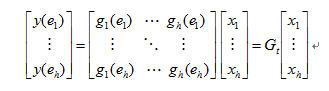
则输出out(e)=(α β) =αS(1,x)+βS(2,y)。编码后的数据以NCP(network coding protocol)包头封装,然后再封装在IP数据报中,如图2.4-2所示:
=αS(1,x)+βS(2,y)。编码后的数据以NCP(network coding protocol)包头封装,然后再封装在IP数据报中,如图2.4-2所示:
![]()
![]()

图2.4-2:编码后数据的封装格式
为减小相应的编码负担和提高编码效率,我们只对网络中的IP数据报中的有效载荷进行编码(已经编码过的数据包可以再进行编码),不对ARP等其他数据包编码。在编码路由器中,我们为不同的输入通道开辟不同的FIFO以进行顺序存取和编码,编码流程如图2.4-3所示:
图2.4-3:数据包的编码流程
2.4.3随机系数的选择
根据相关资料可知,随即编码系数矢量的选择可以从Galois Field中进行选择,依据论文[33][34],我们选择域为GF256,即 ,此时可以解码的概率为1-=0.996,这个概率可以满足大多数的应用需求。
,此时可以解码的概率为1-=0.996,这个概率可以满足大多数的应用需求。
2.4.4 NCP数据包头的格式
为了能够在解码路由器上进行解码,我们需要在被编码的有效载荷前增加NCP数据包头[35],根据我们的方案,其包头格式如图2.4-4:
| 版本 4位 | 首部长度 4位 | 总长度 16位) | 标志 2位 | 保留 6位 | |||||||||
| 第1个包信源号 | 第2个包信源号 | …… | …… |
|
|
| 第8个包信源号 | ||||||
| 第1个包的填充长度(10位) | 编码系数矢量1 (8位) | 代的编号(10位) | 编码次数 (4位) | ||||||||||
| 第2个包的填充长度 | 编码系数矢量2 | 代的编号 | 编码次数 | ||||||||||
| ……………… | …… | …… |
| ||||||||||
| 第n个包的填充长度 | 编码系数n | 代的编号 | 编码次数 | ||||||||||
| 编码后的有效载荷 | |||||||||||||
0 3 7 23 25 31
图2.4-4:NCP数据包的包头格式
先将包头各个字段的含义说明如下:
①版本:NCP数据包格式的版本,为了后续开发研究和以前版本的区分,第一个
- 一种基于电力线的家庭以太网络实现方法(10-10)
- 基于DSP和FPGA的机器人声控系统设计与实现 (04-16)
- 面向大众市场的千兆位级收发器(05-04)
- 利用以太网硬件在环路实现高带宽DSP仿真(05-04)
- 采用软处理器IP规避器件过时的挑战(05-04)
- WCDMA系统基带处理的DSP FPGA实现方案(01-02)