
2.3 时钟树的手动优化
工具自动的时钟树综合总是会有一些skew没有满足设计要求,工具自动插入的一些buffer也不一定都合理,一般情况下,encounter自动综合产生的时钟树是不满足要求的,在经过了时序分析后要进行必要的修复优化。总的原则就是想办法平衡各线路的延时,一般的优化途径有以下一些:
(1)在时钟信号源(Clock Source)处手动添加驱动能力很大的drive cell,因为时钟树一般扇出很大,负载很大,所以在时钟源点处需要驱动能力大的门单元,更大驱动能力的门单元可以明显减少延时。
(2)替换(Re_sizing)驱动能力不一样的单元,尤其是buffer单元。时钟树综合完成后,经过仔细的时序分析后,根据时序分析结果报告,分析Skew违规原因,找出导致Skew违规的路径,根据延时情况来替换一些驱动能力不同的单元,如buffer等,使其延时情况与其他时钟信号线相平衡,从而达到减小Skew的目的。
(3)添加buffer。互连线的延时与连线长度的平方成正比,所以插入buffer可以将长的关键路径分成较小的连线,可以有效地减小互连线的延时。插入的buffer的驱动能力的大小靠经验估计,插入后做时序分析,然后再做re_sizing,直到满足延时要求。

经过eneounter自动时钟树综合后,查看其CTS时序报告,如图4所示,发现时钟elk_pad的最大偏移值达到了152.4 ps,这样与目标值还有很大差距。经过timing Debug跟踪时钟信号,如图5所示,从中找出一些Skew较大的线路,如从fft4442_inst/CT/M3_R_reg/Q到fft4442 _inst/PEII/pc42_in4_reg_76_/RN的延时太长,达到了27.035 ns,因为这样的线路与其他信号线的延时相差比较大,它们之间的Skew就很容易违规,必须减小它们的延时来减小Skew。
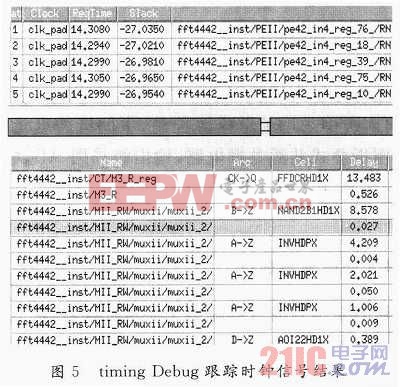
再进一步查看该线路,发现有些单元,如FFDCRHD1X延时达到13.483 ns,HAND281HD1X延时达到8.578ns,INVHDPX也达到了4.209ns,而且该线路还插入了不少BUFHD1X,由于此类buffer的驱动能力太小,从而导致了该线路的延时过大。于是,采用第二类修复办法:替换(r-e_sizing)驱动能力不一样的buffer。于是调用Interactive ECO功能,手动将延时太长的单元FFDCRHD1X、HAND2B1HD1X等的尺寸替换为更大的,从而加强其驱动能力,并将部分BUFHD1X替换成BUFHD4X等,再做了PostCTS optimization后,再进行时序分析,这样经过几轮反复的修复,降低了一些线路的延时,终于将时钟CLK的Skew降到了93.3ps,如图6所示,满足了设计要求。从eneounter的CTS报告中可以看出,加上有针对性的手动修复之后,对Skew的减小有明显效果。

3 结语
随着集成电路设计尺寸的减小和芯片运行频率的提高,时钟偏移已经成为影响ASIC芯片性能的关键因素。本文以对FFT处理器芯片的时钟树综合为例,分析了时钟偏移的产生机理及影响,从布局阶段就开始关注时序的优化,进行了一系列的优化设置。经过时序分析证明,采取工具自动综合和手动修复相结合的办法,容易满足设计要求,不仅可以提高综合效率,还可以保证优化的有效性。 |