语音识别在微机器人控制系统中的应用
时间:12-14
来源:互联网
点击:
本文基于毫米级全方位无回转半径移动机器人课题。微系统配置示意图如图1所示。主要由主机Host(配有图像采集卡)、两个CCD摄像头(其中一个为显微摄像头)、微移动装配平台、微机器人本体和系统控制电路板等组成。计算机和摄像机组用于观察微机器人的方位,控制系统控制微机器人的移动。
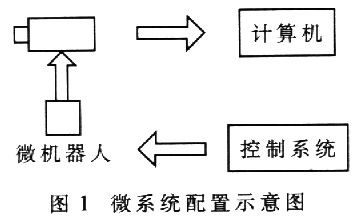
本文在系统控制电路中嵌入式实现语音识别算法,通过语音控制微机器人。
微机器人控制系统的资源有限,控制方法比较复杂,并且需要有较高的实时性,因此本文采用的语音识别算法必须简单、识别率高、占用系统资源少。
HMM(隐马尔可夫模型)的适应性强、识别率高,是当前语音识别的主流算法。使用基于HMM非特定人的语音识别算法虽然借助模板匹配减小了识别所需的资源,但是前期的模板储存工作需要大量的计算和存储空间,因此移植到嵌入式系统还有一定的难度,所以很多嵌入式应用平台的训练部分仍在PC机上实现。
为了使训练和识别都在嵌入式系统上实现,本文给出了一种基于K均值分段HMM模型的实时学习语音识别算法,不仅解决了上述问题,而且做到了智能化,实现了真正意义上的自动语音识别。
1 增量K均值分段HMM的算法及实现
由于语音识别过程中非特定的因素较多,为了提高识别的准确率,针对本系统的特点,采用动态改变识别参数的方法提高系统的识别率。
训练算法是HMM中运算量最大、最复杂的部分,训练算法的输出是即将存储的模型。目前的语音识别系统大都使用贝斯曼参数的HMM模型,采取最大似然度算法。这些算法通常是批处理函数,所有的训练数据要在识别之前训练好并存储。因此很多嵌入式系统因为资源有限不能达到高识别率和实时输出。
本系统采用了自适应增量K均值分段算法。在每次输入新的语句时都连续地计算而不对前面的数据进行存储,这可以节约大量的时间和成本。输入语句时由系统的识别结果判断输入语句的序号,并对此语句的参数动态地修改,真正做到了实时学习。
K均值分段算法是基于最佳状态序列的理论,因此可以采用Viterbi算法得到最佳状态序列,从而方便地在线修改系统参数,使训练的速度大大提高。
为了达到本系统所需要的功能,对通常的K均值算法作了一定的改进。在系统无人监管的情况下,Viterbi解码计算出最大相似度的语音模型,根据这个假设计算分段K均值算法的输入参数,对此模型进行参数重估。首先按照HMM模型的状态数进行等间隔分段,每个间隔的数据段作为某一状态的训练数据,计算模型的初始参数λ=f(a,A,B)。采用Viterbi的最佳状态序列搜索,得到当前最佳状态序列参数和重估参数θ,其中概率密度函数P(X,S|θ)代替了最大似然度算法中的P(X,θ),在不同的马尔科夫状态和重估之间跳转。基于K均值算法的参数重估流程如下:

为了使参数能更快地收敛,在每帧观察语音最佳状态序列的计算结束后,加入一个重估过程,以求更快地响应速度。

可以看到,增量K均值算法的特点为:在每次计算完观察值最佳状态序列后,插入一个重估过程。随时调整参数以识别下一个句子。
由于采用混合高斯密度函数作为输出概率分布可以达到较好的识别效果,因此本文采用M的混合度对数据进行训练。
对λ重估,并比较收敛性,最终得到HMM模型参数训练结果。
可见,用K均值法在线修改时,一次数据输入会有多次重估过程,这使系统使用最近的模型估计后续语句的最佳状态序列成为可能。但是对于在线修改参数要求,快速收敛是很重要的。为了得到更好的Viterbi序列,最佳状态序列使用了渐增的算法模型,即快速收敛算法。
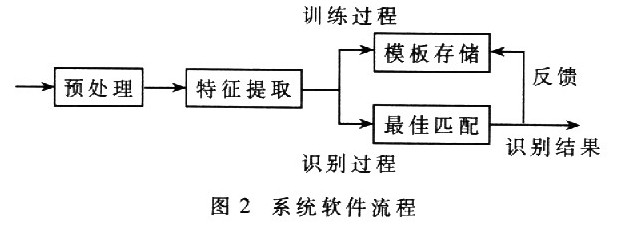
语音识别的具体实现过程为:数字语音信号通过预处理和特征向量的提取,用户通过按键选择学习或者识别模式;如果程序进入训练过程,即用户选择进行新词条的学习,则用分段K均值法对数据进行训练得到模板;如果进入识别模式,则从Flash中调出声音特征向量,进行HMM算法识别。在识别出结果后,立即将识别结果作为正确结果与前一次的状态做比较,得到本词条更好的模板,同时通过LED数字显示和语音输出结果。系统软件流程如图2所示。
对采集到的语音进行16kHz、12位量化,并对数字语音信号进行预加重:

L选择为320个点,用短时平均能量和平均过零率判断起始点,去除不必要的信息。
对数据进行FFT运算,得到能量谱,通过24通道的带通滤波输出X(k),然后再通过DCT运算,提取12个MFCC系数和一阶二阶对数能量,提取38个参数可以使系统识别率得到提高。
为了进行连接词识别,需要由训练数据得到单个词条的模型。方法为:首先从连接词中分离出每个孤立的词条,然后再进行孤立词条的模型训练。对于本系统不定长词条的情况,每个词条需要有一套初始的模型参数,然后按照分层构筑的HMM算法将所有词串分成孤立的词条。对每个词条进行参数的重估,判断是否收敛。如果差异小于某个域值就判断为收敛;否则将得到的参数作为新的初始参数再进行重估,直到收敛。
本文在系统控制电路中嵌入式实现语音识别算法,通过语音控制微机器人。
微机器人控制系统的资源有限,控制方法比较复杂,并且需要有较高的实时性,因此本文采用的语音识别算法必须简单、识别率高、占用系统资源少。
HMM(隐马尔可夫模型)的适应性强、识别率高,是当前语音识别的主流算法。使用基于HMM非特定人的语音识别算法虽然借助模板匹配减小了识别所需的资源,但是前期的模板储存工作需要大量的计算和存储空间,因此移植到嵌入式系统还有一定的难度,所以很多嵌入式应用平台的训练部分仍在PC机上实现。
为了使训练和识别都在嵌入式系统上实现,本文给出了一种基于K均值分段HMM模型的实时学习语音识别算法,不仅解决了上述问题,而且做到了智能化,实现了真正意义上的自动语音识别。
1 增量K均值分段HMM的算法及实现
由于语音识别过程中非特定的因素较多,为了提高识别的准确率,针对本系统的特点,采用动态改变识别参数的方法提高系统的识别率。
训练算法是HMM中运算量最大、最复杂的部分,训练算法的输出是即将存储的模型。目前的语音识别系统大都使用贝斯曼参数的HMM模型,采取最大似然度算法。这些算法通常是批处理函数,所有的训练数据要在识别之前训练好并存储。因此很多嵌入式系统因为资源有限不能达到高识别率和实时输出。
本系统采用了自适应增量K均值分段算法。在每次输入新的语句时都连续地计算而不对前面的数据进行存储,这可以节约大量的时间和成本。输入语句时由系统的识别结果判断输入语句的序号,并对此语句的参数动态地修改,真正做到了实时学习。
K均值分段算法是基于最佳状态序列的理论,因此可以采用Viterbi算法得到最佳状态序列,从而方便地在线修改系统参数,使训练的速度大大提高。
为了达到本系统所需要的功能,对通常的K均值算法作了一定的改进。在系统无人监管的情况下,Viterbi解码计算出最大相似度的语音模型,根据这个假设计算分段K均值算法的输入参数,对此模型进行参数重估。首先按照HMM模型的状态数进行等间隔分段,每个间隔的数据段作为某一状态的训练数据,计算模型的初始参数λ=f(a,A,B)。采用Viterbi的最佳状态序列搜索,得到当前最佳状态序列参数和重估参数θ,其中概率密度函数P(X,S|θ)代替了最大似然度算法中的P(X,θ),在不同的马尔科夫状态和重估之间跳转。基于K均值算法的参数重估流程如下:
为了使参数能更快地收敛,在每帧观察语音最佳状态序列的计算结束后,加入一个重估过程,以求更快地响应速度。
可以看到,增量K均值算法的特点为:在每次计算完观察值最佳状态序列后,插入一个重估过程。随时调整参数以识别下一个句子。
由于采用混合高斯密度函数作为输出概率分布可以达到较好的识别效果,因此本文采用M的混合度对数据进行训练。
对λ重估,并比较收敛性,最终得到HMM模型参数训练结果。
可见,用K均值法在线修改时,一次数据输入会有多次重估过程,这使系统使用最近的模型估计后续语句的最佳状态序列成为可能。但是对于在线修改参数要求,快速收敛是很重要的。为了得到更好的Viterbi序列,最佳状态序列使用了渐增的算法模型,即快速收敛算法。
语音识别的具体实现过程为:数字语音信号通过预处理和特征向量的提取,用户通过按键选择学习或者识别模式;如果程序进入训练过程,即用户选择进行新词条的学习,则用分段K均值法对数据进行训练得到模板;如果进入识别模式,则从Flash中调出声音特征向量,进行HMM算法识别。在识别出结果后,立即将识别结果作为正确结果与前一次的状态做比较,得到本词条更好的模板,同时通过LED数字显示和语音输出结果。系统软件流程如图2所示。
对采集到的语音进行16kHz、12位量化,并对数字语音信号进行预加重:
L选择为320个点,用短时平均能量和平均过零率判断起始点,去除不必要的信息。
对数据进行FFT运算,得到能量谱,通过24通道的带通滤波输出X(k),然后再通过DCT运算,提取12个MFCC系数和一阶二阶对数能量,提取38个参数可以使系统识别率得到提高。
为了进行连接词识别,需要由训练数据得到单个词条的模型。方法为:首先从连接词中分离出每个孤立的词条,然后再进行孤立词条的模型训练。对于本系统不定长词条的情况,每个词条需要有一套初始的模型参数,然后按照分层构筑的HMM算法将所有词串分成孤立的词条。对每个词条进行参数的重估,判断是否收敛。如果差异小于某个域值就判断为收敛;否则将得到的参数作为新的初始参数再进行重估,直到收敛。
- 基于MSP430的自主式移动机器人设计与实现(06-12)
- 如何制作一个最简单的机器人(02-23)
- 机器人技术的新进展(02-23)
- CAN总线技术在工业码垛机器人控制系统中的应用研究(06-27)
- 制作机器人常用传感器盘点(02-23)
- 基于LabVIEW构建智能的移动机器人及无人驾驶车(10-27)