藏在系统核心芯片中的DRAM控制器
时间:12-10
来源:互联网
点击:
作者:Altera公司总编辑Ron Wilson
DRAM控制器藏在您的系统核心芯片系统(SoC)中——可能有两个,甚至是四个。有一些精心制作的逻辑小模块,用于连接SoC内部和外部DRAM,它们并没有引起系统设计人员的注意。它们有可能造成很大的问题,浪费带宽,占用太多的能耗,甚至导致数据被破坏。
DRAM控制器能否正常工作会使得系统有很大的不同,有的系统能够满足其设计要求,而有的系统则运行缓慢,过热,甚至失败。不论哪种情况,最终是由系统设计团队承担责任,他们一般很少掌握控制器的信息。
成功还是失败都源自我们要求DRAM控制器所做的工作。模块不仅仅是一个接口。在高级系统设计中,DRAM控制器必须很好的处理SoC体系结构复杂而又难以预测的存储器申请,以及一侧的系统软件申请,还有另一侧DRAM芯片设计复杂的时序和约束要求。能否处理好这些关系会在多个方面影响DRAM吞吐量:这很容易在系统性能上体现出来。
为解释这些问题——以及系统设计人员能够对此做什么,我们需要回答三个主要问题。首先,我们应检查DRAM芯片提出的要求。然后,需要讨论SoC体系结构对存储器访问模式的影响,第三,研究一个高级DRAM控制器的结构和功能。通过这三部分,我们得出系统设计的一些结论。
DRAM需要什么
系统规划对外部存储器的要求是确定性随机访问:任何时候来自任何位置的任意字,具有固定延时。但是,确定性随机访问恰恰是现代DDR3 DRAM所不能提供的。
相反,DRAM提供任何您需要的字,但是具有复杂的时序约束,因此,很难知道数据究竟什么时候出现。 图1中“简化的”状态转换图简单解释了为什么会这么复杂。这种复杂度也意味着,命令到达DRAM芯片的顺序会对时序以及带宽有很大的影响。要理解这一点,我们需要深入了解DDR3 DRAM。
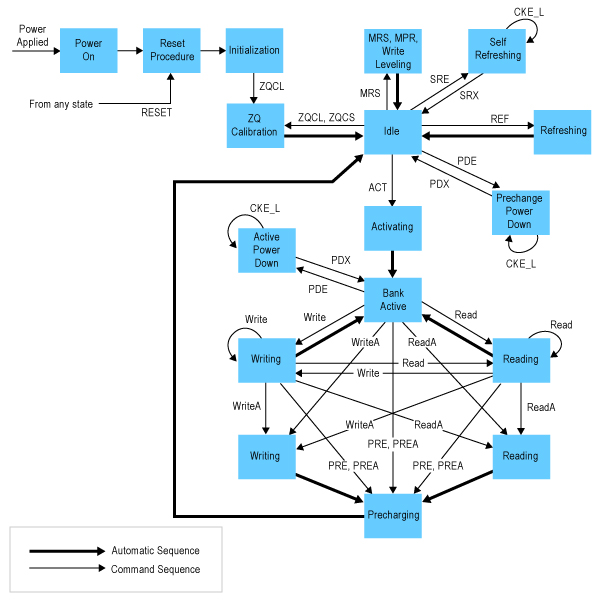
图1.DDR DRAM芯片“简化的”状态图显示了控制器设计人员所面临的复杂问题。
DRAM芯片将数据存储在电容阵列中。当您读写数据时,您并不会直接访问阵列。而是在读写之前,您激活阵列中的某一行。激活命令使得DRAM读取该行中的所有列的所有比特,将其送入传感放大器块,它实际上用作该行的本地寄存器文件。然后,您可以对传感放大器上的数据发出读写命令。通过这种方式,能够非常快的读写已经激活的行:一般是三到五个时钟来开始一次突发传送,然后,在突发期间传送每个字节需要一个时钟。例如,这种时序安排使得DDR3 DRAM非常适合L2高速缓存数据交换。
但是,如果您不使用已经激活的行,那么会非常复杂。改变行时,即使是一个字节,您也必须对当前行去激活,然后激活一个新行。这一过程需要确定已经在一段时间内激活了当前行。由于读取DRAM单元是破坏性的,因此需要最小延时:您激活了一行后,DRAM实际上是将最新到达传感放大器上的数据复制回比特单元阵列中,然后刷新行。您可以在此期间读写当前行,但是,要确定在您改变行之前完成了这一过程。
即使满足了这一要求,也还有其他问题。您必须对阵列预充电。预充电命令使得传感放大器中的数据无效,提升阵列和传感放大器输入之间导线上的电压,使得电压值位于逻辑0和逻辑1电平之间。这种准备是必要的,比特单元电容上很小的电荷都会传送到导线上,以某种方式提示传感放大器。
对导线进行预充电之后,您必须向新行发送一个激活命令,等待操作完成,然后,您最终可以发送一个读操作新命令。加上所有涉及到的延时后,即,读取字节序列的最差情况,每一字节都来自不同的行,这要比读取来自一个新行连续位置相同数量字节的时间慢十倍。
这种不同还只是部分问题。如图2 所示,DDR DRAM有多个块:与比特单元无关的阵列。DDR3 DRAM中有八个块,每一块都有自己排列成行的传感放大器。因此,原理上,您可以通过激活每一个块中的一行,读写较长的突发,然后,对每一激活后的行进行读写操作——实际上是对块进行间插操作。唯一增加的延时是连接每一块的传感放大器和芯片内部总线的缓冲的切换时间。这一延时要比对相同块中一个新行进行预充电和激活的时间短得多。
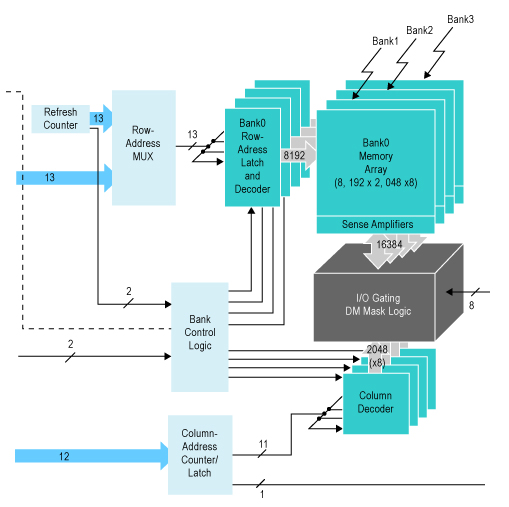
图2.一个典型的DDR DRAM结构图。一个DDR3器件会有8个块,而不是4个。
这就是原理。实际中,您可以对块进行间插处理,但是有一个限制,不是基于DRAM逻辑,而是芯片能够承受的热量。这种限制可以通过著名的“滚动四块访问窗口”,即,tRAW来表达:您一次能够有四个激活块的最长时间。这一规则实际上有例外,只要您从一个块转向下一块之前,在一个块上保持一定的时间,那么,您可以有连续激活的8个块。但是您应该知道:这比较复杂。
DRAM控制器藏在您的系统核心芯片系统(SoC)中——可能有两个,甚至是四个。有一些精心制作的逻辑小模块,用于连接SoC内部和外部DRAM,它们并没有引起系统设计人员的注意。它们有可能造成很大的问题,浪费带宽,占用太多的能耗,甚至导致数据被破坏。
DRAM控制器能否正常工作会使得系统有很大的不同,有的系统能够满足其设计要求,而有的系统则运行缓慢,过热,甚至失败。不论哪种情况,最终是由系统设计团队承担责任,他们一般很少掌握控制器的信息。
成功还是失败都源自我们要求DRAM控制器所做的工作。模块不仅仅是一个接口。在高级系统设计中,DRAM控制器必须很好的处理SoC体系结构复杂而又难以预测的存储器申请,以及一侧的系统软件申请,还有另一侧DRAM芯片设计复杂的时序和约束要求。能否处理好这些关系会在多个方面影响DRAM吞吐量:这很容易在系统性能上体现出来。
为解释这些问题——以及系统设计人员能够对此做什么,我们需要回答三个主要问题。首先,我们应检查DRAM芯片提出的要求。然后,需要讨论SoC体系结构对存储器访问模式的影响,第三,研究一个高级DRAM控制器的结构和功能。通过这三部分,我们得出系统设计的一些结论。
DRAM需要什么
系统规划对外部存储器的要求是确定性随机访问:任何时候来自任何位置的任意字,具有固定延时。但是,确定性随机访问恰恰是现代DDR3 DRAM所不能提供的。
相反,DRAM提供任何您需要的字,但是具有复杂的时序约束,因此,很难知道数据究竟什么时候出现。 图1中“简化的”状态转换图简单解释了为什么会这么复杂。这种复杂度也意味着,命令到达DRAM芯片的顺序会对时序以及带宽有很大的影响。要理解这一点,我们需要深入了解DDR3 DRAM。
图1.DDR DRAM芯片“简化的”状态图显示了控制器设计人员所面临的复杂问题。
DRAM芯片将数据存储在电容阵列中。当您读写数据时,您并不会直接访问阵列。而是在读写之前,您激活阵列中的某一行。激活命令使得DRAM读取该行中的所有列的所有比特,将其送入传感放大器块,它实际上用作该行的本地寄存器文件。然后,您可以对传感放大器上的数据发出读写命令。通过这种方式,能够非常快的读写已经激活的行:一般是三到五个时钟来开始一次突发传送,然后,在突发期间传送每个字节需要一个时钟。例如,这种时序安排使得DDR3 DRAM非常适合L2高速缓存数据交换。
但是,如果您不使用已经激活的行,那么会非常复杂。改变行时,即使是一个字节,您也必须对当前行去激活,然后激活一个新行。这一过程需要确定已经在一段时间内激活了当前行。由于读取DRAM单元是破坏性的,因此需要最小延时:您激活了一行后,DRAM实际上是将最新到达传感放大器上的数据复制回比特单元阵列中,然后刷新行。您可以在此期间读写当前行,但是,要确定在您改变行之前完成了这一过程。
即使满足了这一要求,也还有其他问题。您必须对阵列预充电。预充电命令使得传感放大器中的数据无效,提升阵列和传感放大器输入之间导线上的电压,使得电压值位于逻辑0和逻辑1电平之间。这种准备是必要的,比特单元电容上很小的电荷都会传送到导线上,以某种方式提示传感放大器。
对导线进行预充电之后,您必须向新行发送一个激活命令,等待操作完成,然后,您最终可以发送一个读操作新命令。加上所有涉及到的延时后,即,读取字节序列的最差情况,每一字节都来自不同的行,这要比读取来自一个新行连续位置相同数量字节的时间慢十倍。
这种不同还只是部分问题。如图2 所示,DDR DRAM有多个块:与比特单元无关的阵列。DDR3 DRAM中有八个块,每一块都有自己排列成行的传感放大器。因此,原理上,您可以通过激活每一个块中的一行,读写较长的突发,然后,对每一激活后的行进行读写操作——实际上是对块进行间插操作。唯一增加的延时是连接每一块的传感放大器和芯片内部总线的缓冲的切换时间。这一延时要比对相同块中一个新行进行预充电和激活的时间短得多。
图2.一个典型的DDR DRAM结构图。一个DDR3器件会有8个块,而不是4个。
这就是原理。实际中,您可以对块进行间插处理,但是有一个限制,不是基于DRAM逻辑,而是芯片能够承受的热量。这种限制可以通过著名的“滚动四块访问窗口”,即,tRAW来表达:您一次能够有四个激活块的最长时间。这一规则实际上有例外,只要您从一个块转向下一块之前,在一个块上保持一定的时间,那么,您可以有连续激活的8个块。但是您应该知道:这比较复杂。
Altera SoC 电容 放大器 电压 总线 显示器 收发器 仿真 FPGA ARM 相关文章:
- ALTERA FPGA在微处理器系统中的在应用配置(07-09)
- 真实环境中的系统设计(09-09)
- IoT促进了低功耗的发展(12-05)
- 闪存革命无处不在(12-25)
- 悬崖边上的CPU设计师: 现在该往哪里去?(11-10)
- 可穿戴电子系统的发展——人类和嵌入式系统的结合(12-05)