悬崖边上的CPU设计师: 现在该往哪里去?
时间:11-10
来源:互联网
点击:
作者:Ron Wilson, 总编辑, Altera公司
对可怜的处理器设计师表示同情。他们的工作以前非常简单。在每一半导体新工艺代中,每平方毫米的晶体管数量都会加倍,速度会有很大的提高,同时总功耗也会降低。设计师的黄金规则是 “保持体系结构不变,在实现上稍作调整。”
但现在完全不同了。速度提高的越来越小,功耗降低的也越来越少。您再也不能简单的提高时钟了:设计师不得不使用所有新晶体管来研究实现并行功能。但是怎样找到并行功能呢? 首先,我们找到了现成的好方法:通过超标量体系结构自动实现指令级并行功能。然后,有了更多的晶体管,使用了大部分指令并行功能,矢量处理器进行数据并行处理,宏单元级指令并行 — 线程,采用多线程,然后是多核CPU 。
但是,我们突然发现自己身处无尽的 “暗硅片” 中。所有这些晶体管的功率密度增加非常快,如果它们都同时全速运行,根本没法对其进行散热。我们使用时钟选通,然后是电源选通,最后降低晶体管封装密度,以避免互联走线被熔化。但是,这限制了我们采用越来越多的晶体管实现数据和算法的并行处理。看起来这一过程要慢慢停下来了。
年初的热点芯片大会上就提出了这类问题。虽然在克服困难方面已经取得了很大的成就,但是芯片设计师仍然展示了还有继续创新的空间:找到能够进行并行处理的地方,使用所有晶体管的方法,以及使其保持较低温度的技术。
找到好方法
很显然,如果我们继续使用所有这些晶体管,那么,我们必须降低能耗。这意味着,减少信息的传送:数据移动和复制少了,指令读取的少了。不仅 DRAM 周期能耗比较高,而且在高级进程中,数据通过阻抗越来越大的片内互联也是问题。在传统的体系结构中,我们能够传送大量的数据:最近的估算表明,SoC 中 80% 的活动硅片用于连接或者缓冲互联,而不是用于逻辑功能。
信息传送的少了,意味着需要围绕数据内部结构来组织处理单元—这是热点芯片大会论文最明显的观点。我们特别关注一下四种情形。第一,搜索引擎加速,处理大量的非结构和独立数据元素。第二种情形,矢量处理,处理高度结构化的数据,其元素之间会有相关性。第三种,有很多线程的问题,但不一定是并行数据处理。最后一种情形,单线程加速。
搜索引擎加速
对于并行执行而言,网络搜索既带来了很多难题,也创造了机会。数据中心设计师不仅仅需要多核 x86 CPU,他们考虑更多的是数据的非结构、独立特性—基本上,网页上到处都是。在热点芯片大会上,微软资深研究硬件设计工程师 Andrew Putnam 介绍了他的团队在加速必应搜索引擎方面的工作。
Putnam 简要介绍了搜索问题的关键阶段流程,页面评定 (图1)。在第一阶段,服务器群—大量的服务器,选择候选页面:含有某些搜索字符串元素的页面。这些页面被送入评定引擎,本身包括三级:特性提取、自由形式表达评估,以及机器学习评分。
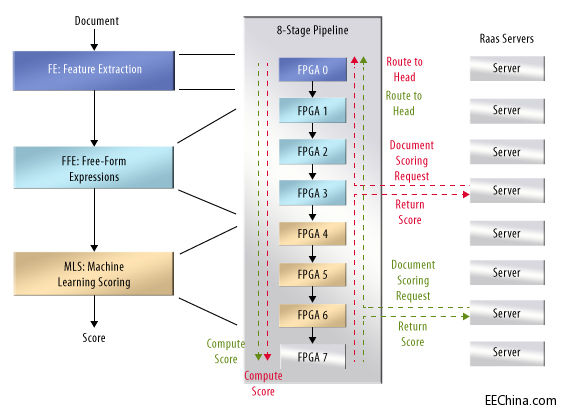
图1. 在专用处理单元群中实现页面评定流水线,加速必应搜索。
Putnam 说,特性提取是由 54 个硬件状态机阵列完成的,即,规则表达匹配和结果列表。使用状态机避免了指令获取和解码操作带来的能耗问题。为进一步降低能耗,页面内容不会通过特性提取器:只有记录特性出现、位置和频率的表格数据被传送至下一级。
表达式评估器是另一阵列,但这次是特殊的多线程处理器阵列。这些处理器,以 240 个单元为一群,读取来自提取器的表格数据,从中计算出非常复杂的数字表达值,这可能会包括超越函数。必应开发人员调整了算法,因此,这些表达式会有所变化,无法对其进行硬线连接。这一级的输出是页面评定,为从搜索字符串中提取出的元特性分配一个数字。
这一数据随后被送入机器学习级,Putnam 对此并没有介绍,这可能需要大量的并行神经网络仿真。正是这一可训练级为页面产生最终的评定分。
Putnam 说,微软选择在大规模 FPGA 的 2D 平面内实现三级评定引擎。每一 FPGA 位于中间电路板上,插入到微软标准服务器机柜的服务器刀片中。Putnam 观察到,可以采用 ASIC 来很好的均衡速度和功耗。但是由于必应评定算法的多变性,需要具备重新配置能力。他提醒说,否则,特殊的硬件很快就会成为程序员面临的瓶颈问题,最终不得不依赖数据中心来解决问题。
微软的设计人员建立了硬件引擎的很多例化,允许异步运行,研究页面评定的固有并行特性。尽可能减少指令获取和解码操作。定义了任务,因此,只有很少量的数据在流水线级之间传送。在不同的环境中应用相同的原理,会导致完全不同的体系结构。
矢量处理器
搜索引擎使用的数据集有两个重要的特性(除了巨大的规模之外)。首先,数据元素是独立的。即,一个页面的评定分值对任何其他页面的分值没有影响,因此,打分任务互不影响。其次,数据元素是非结构化的:两个页面不必有相同的格式。
但是仍然有其他大量的数据集具有严格的结构。例如,在大气模型中,每一点都会是矢量,包括了坐标、温度、入射射线、各种气体的压力分量,以及悬浮颗粒的浓度等。计算模型的下一状态需要对同一矢量算法进行大量的重复。
这些问题非常适合采用矢量处理器来解决:很多同样的算法流水线工作在锁定步骤,同时完成相同的运算,但是针对不同的数据—即,经常使用的术语,单指令多数据 (SIMD) 机制。很显然,这些机制并行完成很多运算,从而提高了性能。通过减少指令获取数据流,也降低了能耗。
在热点芯片大会上,NEC 开发经理 Shintaro Momose 介绍了他所在单位的下一代芯片设计,包括 NEC 长远的 SX 系列矢量超级计算机:SX-ACE。Momose 重点介绍了两个特殊问题:存储器带宽和粒度。
Momose解释了很多大规模应用 — 包括天气预报、例子物理、流体动力学,以及结构分析等,为提高计算性能,这需要很高的存储器带宽,计算机每完成一次浮点运算都需要与存储器交换一个字节。而矢量处理器芯片达到了数十 GFLOPS,对 DRAM 的要求越来越高 — 足以填满芯片的任何总线。相应的,NEC 把 DRAM 控制器—16 个独立的 DDR3 SDRAM 控制器,直接放到矢量处理器管芯中,大量的管芯交叉开关连接所有 DRAM 通道和任何矢量处理单元。这一决定使得单芯片总带宽达到 256 GBps。
粒度是更有趣的一个问题。并行体系结构最近的发展趋势是—可能受到图形处理单元 (GPU) 进行高性能计算的影响,由非常简单的处理器构成大规模阵列。而 Momose 看到,这类体系结构虽然概念上很简单,但是在实际中,要求程序员发现足够的并行功能,使这些小 CPU 工作起来,让每一个任务保持同步或者互相锁定。他认为,更好的是采用一些功能更强大的矢量内核而不是很多小内核。
这就是 SX-ACE 所采用的方法。每一芯片中的每个内核都包括标量处理单元、矢量处理单元和 1 MB 的共享快速 RAM。矢量单元有 16 个处理模块,每个模块包括了两个加法流水线,两个乘法流水线,以及一个除法/平方根流水线,一个逻辑流水线,以及一个屏蔽流水线。每一芯片有四个内核,因此,每一芯片总峰值达到 256 GFLOPS,与存储器总带宽相匹配。在大规模本地存储器周围布置快速控制处理器和 16 个算术模块,NEC找到了大规模并行和实际代码编程的最佳平衡点,这些代码与实际的数据有很大的相关性。
对可怜的处理器设计师表示同情。他们的工作以前非常简单。在每一半导体新工艺代中,每平方毫米的晶体管数量都会加倍,速度会有很大的提高,同时总功耗也会降低。设计师的黄金规则是 “保持体系结构不变,在实现上稍作调整。”
但现在完全不同了。速度提高的越来越小,功耗降低的也越来越少。您再也不能简单的提高时钟了:设计师不得不使用所有新晶体管来研究实现并行功能。但是怎样找到并行功能呢? 首先,我们找到了现成的好方法:通过超标量体系结构自动实现指令级并行功能。然后,有了更多的晶体管,使用了大部分指令并行功能,矢量处理器进行数据并行处理,宏单元级指令并行 — 线程,采用多线程,然后是多核CPU 。
但是,我们突然发现自己身处无尽的 “暗硅片” 中。所有这些晶体管的功率密度增加非常快,如果它们都同时全速运行,根本没法对其进行散热。我们使用时钟选通,然后是电源选通,最后降低晶体管封装密度,以避免互联走线被熔化。但是,这限制了我们采用越来越多的晶体管实现数据和算法的并行处理。看起来这一过程要慢慢停下来了。
年初的热点芯片大会上就提出了这类问题。虽然在克服困难方面已经取得了很大的成就,但是芯片设计师仍然展示了还有继续创新的空间:找到能够进行并行处理的地方,使用所有晶体管的方法,以及使其保持较低温度的技术。
找到好方法
很显然,如果我们继续使用所有这些晶体管,那么,我们必须降低能耗。这意味着,减少信息的传送:数据移动和复制少了,指令读取的少了。不仅 DRAM 周期能耗比较高,而且在高级进程中,数据通过阻抗越来越大的片内互联也是问题。在传统的体系结构中,我们能够传送大量的数据:最近的估算表明,SoC 中 80% 的活动硅片用于连接或者缓冲互联,而不是用于逻辑功能。
信息传送的少了,意味着需要围绕数据内部结构来组织处理单元—这是热点芯片大会论文最明显的观点。我们特别关注一下四种情形。第一,搜索引擎加速,处理大量的非结构和独立数据元素。第二种情形,矢量处理,处理高度结构化的数据,其元素之间会有相关性。第三种,有很多线程的问题,但不一定是并行数据处理。最后一种情形,单线程加速。
搜索引擎加速
对于并行执行而言,网络搜索既带来了很多难题,也创造了机会。数据中心设计师不仅仅需要多核 x86 CPU,他们考虑更多的是数据的非结构、独立特性—基本上,网页上到处都是。在热点芯片大会上,微软资深研究硬件设计工程师 Andrew Putnam 介绍了他的团队在加速必应搜索引擎方面的工作。
Putnam 简要介绍了搜索问题的关键阶段流程,页面评定 (图1)。在第一阶段,服务器群—大量的服务器,选择候选页面:含有某些搜索字符串元素的页面。这些页面被送入评定引擎,本身包括三级:特性提取、自由形式表达评估,以及机器学习评分。
图1. 在专用处理单元群中实现页面评定流水线,加速必应搜索。
Putnam 说,特性提取是由 54 个硬件状态机阵列完成的,即,规则表达匹配和结果列表。使用状态机避免了指令获取和解码操作带来的能耗问题。为进一步降低能耗,页面内容不会通过特性提取器:只有记录特性出现、位置和频率的表格数据被传送至下一级。
表达式评估器是另一阵列,但这次是特殊的多线程处理器阵列。这些处理器,以 240 个单元为一群,读取来自提取器的表格数据,从中计算出非常复杂的数字表达值,这可能会包括超越函数。必应开发人员调整了算法,因此,这些表达式会有所变化,无法对其进行硬线连接。这一级的输出是页面评定,为从搜索字符串中提取出的元特性分配一个数字。
这一数据随后被送入机器学习级,Putnam 对此并没有介绍,这可能需要大量的并行神经网络仿真。正是这一可训练级为页面产生最终的评定分。
Putnam 说,微软选择在大规模 FPGA 的 2D 平面内实现三级评定引擎。每一 FPGA 位于中间电路板上,插入到微软标准服务器机柜的服务器刀片中。Putnam 观察到,可以采用 ASIC 来很好的均衡速度和功耗。但是由于必应评定算法的多变性,需要具备重新配置能力。他提醒说,否则,特殊的硬件很快就会成为程序员面临的瓶颈问题,最终不得不依赖数据中心来解决问题。
微软的设计人员建立了硬件引擎的很多例化,允许异步运行,研究页面评定的固有并行特性。尽可能减少指令获取和解码操作。定义了任务,因此,只有很少量的数据在流水线级之间传送。在不同的环境中应用相同的原理,会导致完全不同的体系结构。
矢量处理器
搜索引擎使用的数据集有两个重要的特性(除了巨大的规模之外)。首先,数据元素是独立的。即,一个页面的评定分值对任何其他页面的分值没有影响,因此,打分任务互不影响。其次,数据元素是非结构化的:两个页面不必有相同的格式。
但是仍然有其他大量的数据集具有严格的结构。例如,在大气模型中,每一点都会是矢量,包括了坐标、温度、入射射线、各种气体的压力分量,以及悬浮颗粒的浓度等。计算模型的下一状态需要对同一矢量算法进行大量的重复。
这些问题非常适合采用矢量处理器来解决:很多同样的算法流水线工作在锁定步骤,同时完成相同的运算,但是针对不同的数据—即,经常使用的术语,单指令多数据 (SIMD) 机制。很显然,这些机制并行完成很多运算,从而提高了性能。通过减少指令获取数据流,也降低了能耗。
在热点芯片大会上,NEC 开发经理 Shintaro Momose 介绍了他所在单位的下一代芯片设计,包括 NEC 长远的 SX 系列矢量超级计算机:SX-ACE。Momose 重点介绍了两个特殊问题:存储器带宽和粒度。
Momose解释了很多大规模应用 — 包括天气预报、例子物理、流体动力学,以及结构分析等,为提高计算性能,这需要很高的存储器带宽,计算机每完成一次浮点运算都需要与存储器交换一个字节。而矢量处理器芯片达到了数十 GFLOPS,对 DRAM 的要求越来越高 — 足以填满芯片的任何总线。相应的,NEC 把 DRAM 控制器—16 个独立的 DDR3 SDRAM 控制器,直接放到矢量处理器管芯中,大量的管芯交叉开关连接所有 DRAM 通道和任何矢量处理单元。这一决定使得单芯片总带宽达到 256 GBps。
粒度是更有趣的一个问题。并行体系结构最近的发展趋势是—可能受到图形处理单元 (GPU) 进行高性能计算的影响,由非常简单的处理器构成大规模阵列。而 Momose 看到,这类体系结构虽然概念上很简单,但是在实际中,要求程序员发现足够的并行功能,使这些小 CPU 工作起来,让每一个任务保持同步或者互相锁定。他认为,更好的是采用一些功能更强大的矢量内核而不是很多小内核。
这就是 SX-ACE 所采用的方法。每一芯片中的每个内核都包括标量处理单元、矢量处理单元和 1 MB 的共享快速 RAM。矢量单元有 16 个处理模块,每个模块包括了两个加法流水线,两个乘法流水线,以及一个除法/平方根流水线,一个逻辑流水线,以及一个屏蔽流水线。每一芯片有四个内核,因此,每一芯片总峰值达到 256 GFLOPS,与存储器总带宽相匹配。在大规模本地存储器周围布置快速控制处理器和 16 个算术模块,NEC找到了大规模并行和实际代码编程的最佳平衡点,这些代码与实际的数据有很大的相关性。
Altera 半导体 SoC 神经网络 仿真 FPGA 电路 总线 ARM 解码器 电压 电流 相关文章:
- ALTERA FPGA在微处理器系统中的在应用配置(07-09)
- 藏在系统核心芯片中的DRAM控制器(12-10)
- 真实环境中的系统设计(09-09)
- IoT促进了低功耗的发展(12-05)
- 闪存革命无处不在(12-25)
- 可穿戴电子系统的发展——人类和嵌入式系统的结合(12-05)