悬崖边上的CPU设计师: 现在该往哪里去?
时间:11-10
来源:互联网
点击:
需要大量流水线的应用
与数据并行的很多问题相比,数据中的一些问题看起来很难解决,但是可以编程,产生很多线程。在这种情况下,您仍然可以实现很多并行执行,但是每一线程可以完成不同的工作,因此,矢量处理体系结构的价值不大。对于这些情形,ARM® CTO Mike Muller 在他的主题演讲中建议了一种不同的策略:他称之为异构计算/同构体系结构。
这种想法来自于 ARM 的 big.LITTLE 概念。如果一项任务有很多线程,一个或者两个线程真正需要大量的计算,而很多线程并不需要。big.LITTLE 概念就是把一些小规模的低功耗处理器,以及使用相同的指令集而功能强大的大规模处理器组织起来。然后,硬核线程可以在高速大功率 CPU 上运行,线程完成后,可以选通电源供电。在较慢的低功耗 CPU 上运行简单线程。
在热点芯片大会上,Muller 进一步延伸了这一概念,他建议,除了 big 和 LITTLE ARM 内核,集群还可以含有 ARM 的 MALI GPU 内核,以及单指令多线程处理器,一些实例目前已经在 ARM 的研究实验室中开始规划了 (图2)。所有处理器会共享公共编程语言,甚至是某些对象代码,共享主存储器,透明、动态的进行线程分配,降低了对显式数据传送的需求。通过把每一线程分配给低功耗处理器,满足了线程目前的性能需求,这类系统降低了总任务的能耗。
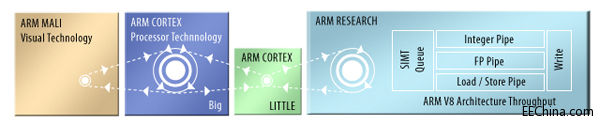
图2. ARM 的异构计算同构体系结构结合了完全不同的微体系结构内核,可以共享相同的源代码。
单线程性能
聪明的程序员发现并应用了数据并行执行功能,梳理好代码中的所有线程后,仍然存在单线程执行的问题。但是,我们已经把时钟频率、超标量体系结构、分支预测以及很多其他方法发挥到了极限。还有什么其他好办法吗?在一篇介绍新 Denver CPU 内核的文章中,Nvidia CPU 设计师 Darrell Boggs说,有。
丹佛很可能是ARM V8所要采用的 (图3)。这是一种七路超标量体系结构,含有整数、整数/负载存储和 NEON 浮点执行流水线。它使用了硬件预获取单元,每一周期解码 8 条指令。这实际源自很早的 CPU 体系结构的一种特性:丹佛完成动态随时微代码优化功能。
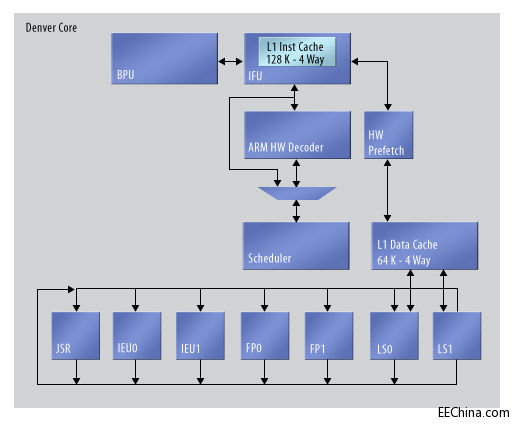
图3. 在您深入了解指令获取单元之前,Nvidia 的丹佛 CPU 看起来像是传统的超标量 CPU。
Boggs 解释说;“执行和分支单元在执行期间对代码进行分析。把分析信息传送给硬件优化器,解开循环,重新命名寄存器,重新组织指令。然后,优化后的代码以微代码的形式存储器在特殊高速缓存中。”
Boggs 解释说,第一次通过循环,丹佛构建了代码的微代码版本,优化了数千条指令。在后续的步骤中,读取单元装入来自优化高速缓存而不是指令高速缓存的微代码,旁路指令解码器,把微代码直接送入执行单元。结果,对于迭代代码,丹佛在遇到新代码之前会尽可能只使用最初的指令流。会很快开始处理大部分微代码。
Boggs 宣称,这一方法提高了执行速度。他展示了结果,在标准测试中,2.5 GHz 丹佛接近甚至超越了 Intel 的 Haswell。
Boggs 说,丹佛还解决了功耗问题。除了时钟选通和电源轨选通之外,CPU 还支持低电压 “保持” 模式,保持 CPU 和高速缓存状态,有效的降低了泄漏电流。通过避免 CPU 检查点和高速缓存泛洪问题,保持模式提供了空闲间隙降低功耗的方法,这些间隙非常短,无法完全进行电源选通,通过这些方法处理泛洪和状态恢复问题。
对高性能和低功耗的需求会持续不断,半导体技术再也不能以简单的方式来满足这些需求。而解决方案越来越专门针对应用的特殊性,算法编程,以及数据的本质结构等。最终,所有体系结构都会更加专用化,通用 CPU 这一术语的含义也会逐渐变化。
与数据并行的很多问题相比,数据中的一些问题看起来很难解决,但是可以编程,产生很多线程。在这种情况下,您仍然可以实现很多并行执行,但是每一线程可以完成不同的工作,因此,矢量处理体系结构的价值不大。对于这些情形,ARM® CTO Mike Muller 在他的主题演讲中建议了一种不同的策略:他称之为异构计算/同构体系结构。
这种想法来自于 ARM 的 big.LITTLE 概念。如果一项任务有很多线程,一个或者两个线程真正需要大量的计算,而很多线程并不需要。big.LITTLE 概念就是把一些小规模的低功耗处理器,以及使用相同的指令集而功能强大的大规模处理器组织起来。然后,硬核线程可以在高速大功率 CPU 上运行,线程完成后,可以选通电源供电。在较慢的低功耗 CPU 上运行简单线程。
在热点芯片大会上,Muller 进一步延伸了这一概念,他建议,除了 big 和 LITTLE ARM 内核,集群还可以含有 ARM 的 MALI GPU 内核,以及单指令多线程处理器,一些实例目前已经在 ARM 的研究实验室中开始规划了 (图2)。所有处理器会共享公共编程语言,甚至是某些对象代码,共享主存储器,透明、动态的进行线程分配,降低了对显式数据传送的需求。通过把每一线程分配给低功耗处理器,满足了线程目前的性能需求,这类系统降低了总任务的能耗。
图2. ARM 的异构计算同构体系结构结合了完全不同的微体系结构内核,可以共享相同的源代码。
单线程性能
聪明的程序员发现并应用了数据并行执行功能,梳理好代码中的所有线程后,仍然存在单线程执行的问题。但是,我们已经把时钟频率、超标量体系结构、分支预测以及很多其他方法发挥到了极限。还有什么其他好办法吗?在一篇介绍新 Denver CPU 内核的文章中,Nvidia CPU 设计师 Darrell Boggs说,有。
丹佛很可能是ARM V8所要采用的 (图3)。这是一种七路超标量体系结构,含有整数、整数/负载存储和 NEON 浮点执行流水线。它使用了硬件预获取单元,每一周期解码 8 条指令。这实际源自很早的 CPU 体系结构的一种特性:丹佛完成动态随时微代码优化功能。
图3. 在您深入了解指令获取单元之前,Nvidia 的丹佛 CPU 看起来像是传统的超标量 CPU。
Boggs 解释说;“执行和分支单元在执行期间对代码进行分析。把分析信息传送给硬件优化器,解开循环,重新命名寄存器,重新组织指令。然后,优化后的代码以微代码的形式存储器在特殊高速缓存中。”
Boggs 解释说,第一次通过循环,丹佛构建了代码的微代码版本,优化了数千条指令。在后续的步骤中,读取单元装入来自优化高速缓存而不是指令高速缓存的微代码,旁路指令解码器,把微代码直接送入执行单元。结果,对于迭代代码,丹佛在遇到新代码之前会尽可能只使用最初的指令流。会很快开始处理大部分微代码。
Boggs 宣称,这一方法提高了执行速度。他展示了结果,在标准测试中,2.5 GHz 丹佛接近甚至超越了 Intel 的 Haswell。
Boggs 说,丹佛还解决了功耗问题。除了时钟选通和电源轨选通之外,CPU 还支持低电压 “保持” 模式,保持 CPU 和高速缓存状态,有效的降低了泄漏电流。通过避免 CPU 检查点和高速缓存泛洪问题,保持模式提供了空闲间隙降低功耗的方法,这些间隙非常短,无法完全进行电源选通,通过这些方法处理泛洪和状态恢复问题。
对高性能和低功耗的需求会持续不断,半导体技术再也不能以简单的方式来满足这些需求。而解决方案越来越专门针对应用的特殊性,算法编程,以及数据的本质结构等。最终,所有体系结构都会更加专用化,通用 CPU 这一术语的含义也会逐渐变化。
Altera 半导体 SoC 神经网络 仿真 FPGA 电路 总线 ARM 解码器 电压 电流 相关文章:
- ALTERA FPGA在微处理器系统中的在应用配置(07-09)
- 藏在系统核心芯片中的DRAM控制器(12-10)
- 真实环境中的系统设计(09-09)
- IoT促进了低功耗的发展(12-05)
- 闪存革命无处不在(12-25)
- 可穿戴电子系统的发展——人类和嵌入式系统的结合(12-05)