采用Altera 10代FPGA实现低延时小尺寸设计
时间:06-09
来源:互联网
点击:
- 更孝更快、更好
Altera新的低延时10GbE IP内核最先受益于10代FPGA体系结构。IP优化将内核性能从156.25 MHz提高到312.5 MHz。表2对比了现有标准10GbE IP内核与新的低延时内核。不但体积减小36%,速度提高24%,而且低延时40GbE IP内核在体积和延时方面的优势是减小了40%,而低延时100GbE IP内核打破了传统的思路,引脚布局减小了55%,往返延时降低了70%。与已经非常优秀的内核和真正同类最佳的IP相比,这些IP均更为先进。
表1列出了标准和低延时10GbE IP内核在大小和速度上的不同。
表1.10GbE内核大小和速度
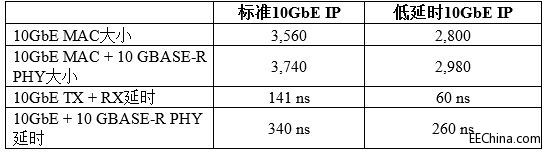
表2列出了标准和低延时40GbE IP内核在大小和速度上的不同。
表2.40GbE IP内核大小和速度
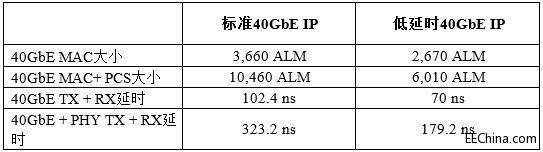
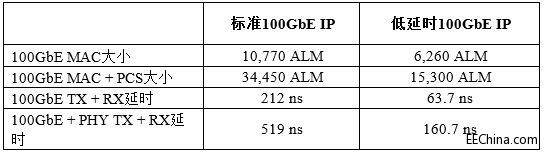
表3列出了标准和低延时100GbE IP内核在大小和速度上的不同。
表3.100GbE IP内核大小和速度
Interlaken是可扩展协议,支持从10 Gbps到100 Gbps及以上的芯片至芯片数据包传送。Interlaken设计用于接入、骨干以太网和数据中心应用的多太比特路由器和交换机,这些应用要求IP可配置,以优化系统性能和互操作性。Altera的Interlaken IP内核使用了Stratix V和Arria V FPGA中的硬核PCS,与软核IP相比,节省了30%至50%的逻辑资源。Altera的IP内核经过了大量的仿真验证,确保了符合Interlaken协议规范v1.2。表4总结了Altera Interlaken IP的特性和优点:
表4.Altera Interlaken IP的特性和优点

目前低延时10GbE IP内核已开始提供,并可早期试用Interlaken和40GbE以及100GbE IP内核,预计2014年上半年开始批量供货。
设计人员可以从数百个Altera IP解决方案中进行选择,所有这些IP都经过了全面的测试、验证和优化,能够在底层硬件上工作,从而避免了棘手的集成问题,支持围绕复杂的IP模块开发应用程序,并确保能够协同工作,因此,产品能够更迅速面市。
随着数据速率的不断提高,100 Gbps带宽会很快耗尽,新的400 Gbps系统高速协议将是现有硬件面临的一个主要难题。10代FPGA体系结构不断创新,Altera可交付1 GHz FPGA,极大的提高了带宽,同时切实降低了功耗,减小了管芯尺寸。Stratix 10 FPGA将能够处理400GbE,甚至500 Gbps Interlaken。
综合考虑进行设计
那么Altera是如何针对这么多的IP内核快速实现如此低的延时,并减小尺寸的?答案在于IP体系结构以及底层FPGA硅片的体系结构。事实上,二者相结合才实现了电路板上的这些重大改进。对于底层硅片,通常认为芯片设计不可避免的会有困难,在速度、功耗、延时和管芯尺寸上要进行难以取舍的综合考虑。从28 nm开始,Altera重新设计了FPGA,与前一代FPGA相比,生产的芯片速度更快,功耗更低,体积更小,设计人员工作起来比以前更自由。
中端Arria 10 FPGA和SoC是10代系列产品中推出的第一款系列器件。该系列器件为中端可编程器件设立了新标杆,以最低的中端器件功耗实现了当前高端FPGA的性能和功能。利用针对TSMC 20 nm工艺进行了优化的增强体系结构,Arria 10 FPGA和SoC比前一器件系列的性能更强,而功耗降低了40%。
Arria 10器件的特性和功能比目前的高端FPGA更丰富,而性能提高了15%。Arria 10 FPGA和SoC反映了硅片融合的发展趋势,实现了系统集成度最高的中端器件,包括115万LE、集成硬核IP和第二代处理器系统,这一系统具有1.5 GHz双核ARM Cortex-A9处理器。Arria 10 FPGA和SoC含有28 Gbps收发器,带宽比当前一代产品高4倍,系统性能提高了3倍,支持每秒2,666兆比特(Mbps) DDR4 SDRAM以及15 Gbps HMC。
高端Stratix 10 FPGA和SoC——内核性能高达1 GHz,将超过10 TeraFLOPS,这一性能水平是任何货架器件都不具备的。
对于在这些硅片平台上重新设计的IP,Altera工程师重新研究了数据通路,减少了流水线,非常关注优化控制结构。这样,他们将时钟速率提高了一倍,而延时没有变化。
Altera逻辑单元注意到在传统的流水线中,在寄存器级之间通常有三个甚至更多的LUT。现有的硬件体系结构有太多的寄存器,如果不增加后布局布线面积就无法提高寄存能力(请参考图1)。
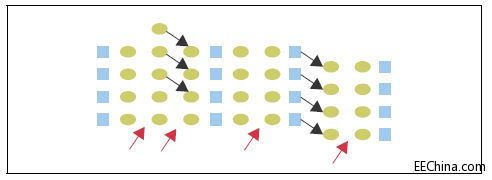
图1.Altera逻辑单元,每一个未寄存的LUT靠近一个未使用的寄存器。
将未寄存的LUT与寄存器相匹配导致电路带宽加倍,同时保持了面积不变。例如,100GbE能够运行在200 Gbps。应用工程师现在可以选择运行两个独立的流,也可以占用一半的电路来运行一个流(请参考图2)。
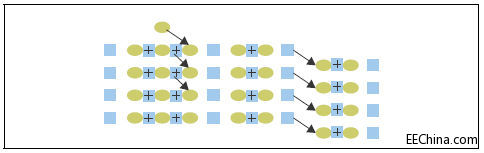
图2.未寄存LUT与未使用的寄存器相匹配
最后的选择涉及到删除一半的宽度,保持最初的带宽。对于并行度很高的电路,这是停止点:时钟速率加倍,相同的延时,一半的面积(请参考图3)。
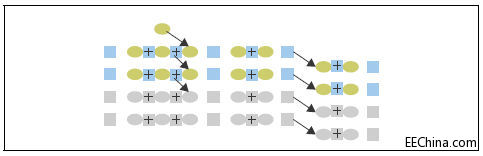
图3.提高了效率,限制带宽能够减小管芯面积。
所有这些体系结构创新都应用到了Stratix V、Arria 10以及Stratix 10 FPGA和SoC上。这就是前面列出的所有IP变小、更快、更好的主要原因。这些发现促使Altera在将要发布的所有新IP内核中实现Altera这些良好的实践。已经更新了Altera的设计软件,确保全面的器件支持,实现与已有设计的无缝移植。
Altera 电子 半导体 FPGA 物联网 传感器 收发器 电路 仿真 SoC ARM Cortex 相关文章:
- 验证FPGA设计:模拟,仿真,还是碰运气?(08-04)
- 学习FPGA绝佳网站推荐!!!(05-23)
- 智能命令行设计及其在 SOPC 系统中的应用(08-14)
- 我的FPGA学习历程(05-23)
- 在FPGA中实现源同步LVDS接收正确字对齐(05-01)
- Altera FPGA下载配置(11-11)