如何用FPGA实现算法的硬件加速
时间:12-09
来源:互联网
点击:
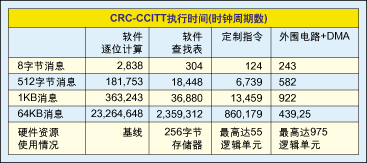
表1:各种规模的数据模块下CRC算法测试比较结果。
2).采用定制指令方法
CRC算法由连续的异或和移位操作构成,用很少的逻辑即可在硬件中简单实现。由于这一硬件模块仅需几个周期来计算CRC,采用定制指令来实现CRC计算要比采用外围电路更好。此外,无须涉及系统中任何其它外围电路或存储器。仅需要一个微处理器来支持定制指令即可,一般是指可配置微处理器。
当在硬件中实现时,算法应该每次执行16或32位计算,这取决于所采用的CRC标准。如果采用CRC-CCITT标准(16位多项式),最好每次执行16位计算。如果使用8位微处理器,效率可能不太高,因为装载操作数值及返回CRC值需要额外的周期。图2示出了用硬件实现16位CRC算法的内核。
信号msg(15..0)每次被移入异或/移位硬件一位。列表3示出了在64KB数据模块上计算CRC的一些C代码例子。该实例是针对Nios嵌入式处理器。
列表3:采用定制指令的CRC计算C代码。
unsigned short crcCompute(unsigned short *data_block, unsigned int nWords)
{
unsigned short* pointer;
unsigned short word;
/*
* initialize crc reg to 0xFFFF
*/
word = nm_crc (0xFFFF, 1); /* nm_crc() is the CRC custom instruction */
/*
* calculate CRC on block of data
* nm_crc() is the CRC custom instruction
*
*/
for (pointer = data_block; pointer <(data_block + nWords); pointer ++)
word = nm_crc(*pointer, 0) return (word);
}
int main(void)
{
#define data_block_begin (na_onchip_memory)
#define data_block_end (na_onchip_memory + 0xffff)
unsigned short crc_result;
unsigned int data_block_length = (unsigned short *)data_block_end - (unsigned short
*)data_block_begin + 1;
crc_result = crcCompute((unsigned short *)data_block_begin,
data_block_length);
}
采用定制指令时,用于计算CRC值的代码是一个函数调用,或宏。当针对Nios处理器实现定制指令时,系统构建工具会生成一个宏。在本例中为nm_crc(),可用它来调用定制指令。
在启动CRC计算之前,定制指令内的CRC寄存器需要先初始化。装载初始值是CRC标准的一部分,而且每种CRC标准都不一样。接着,循环将为数据模块中的每16位数据调用一次CRC定制指令。这种定制指令实现方式要比逐位实现的方法快27倍。
3).CRC外围电路方法
如果将CRC算法作为硬件外围电路来实现,并利用DMA将数据从存储器转移到外围电路,这样还可以进一步提高速度。这种方法将省去处理器为每次计算而装载数据所需要的额外周期。DMA可在此外围电路完成前一次CRC计算的时钟周期内提供新的数据。图3示出了利用DMA、CRC外围电路来实现加速的系统模块示意图。
在64KB数据模块上,利用带DMA的定制外围电路可获得比逐位计算的纯软件算法快500倍的性能。要知道,随着数据模块规模的增加,使用DMA所获得的性能也随之提高。这是因为设置DMA仅需很少的开销,设置之后DMA运行得特别快,因为每个周期它都可以传递数据。因此,若只有少数字节的数据,用DMA并不划算。
这里所讨论的所有采用CRC-CCITT标准(16位多项式)的算法都是在Altera Stratix FPGA的Nios处理器上实现的。表1示出了各种数据长度的测试比较结果,以及大致的硬件使用情况(FPGA中的存储器或逻辑单元)。
可以看出,算法所用的硬件越多,算法速度越快。这是用硬件资源来换取速度。
5 FPGA的优点
当采用基于FPGA的嵌入式系统时,在设计周期之初不必为每个模块做出用硬件还是软件的选择。如果在设计中间阶段需要一些额外的性能,则可以利用FPGA中现有的硬件资源来加速软件代码中的瓶颈部分。由于FPGA中的逻辑单元是可编程的,可针对特定的应用而定制硬件。因此,仅使用所需要的硬件即可,而不必做出任何板级变动(前提是FPGA中的逻辑单元足够用)。设计者不必转换到另一个新的处理器或者编写汇编代码,就可做到这一点。
使用带可配置处理器的FPGA可获得设计灵活性。设计者可以选择如何实现软件代码中的每个模块,如用定制指令,或硬件外围电路。此外,还可以通过添加定制的硬件而获取比现成微处理器更好的性能。
另一点要知道的是,FPGA有充裕的资源,可配置处理器系统可以充分利用这一资源。
算法可以用软件,也可用硬件实现。出于简便和成本考虑,一般利用软件来实现大部分操作,除非需要更高的速度以满足性能指标。软件可以优化,但有时是不够的。如果需要更高的速度,利用硬件来加速算法是一个不错的选择。
FPGA使软件模块和硬件模块的相互交换更加简便,不必改变处理器或进行板级变动。设计者可以在速度、硬件逻辑、存储器、代码大小和成本之间做出折衷。利用FPGA可以设计定制的嵌入式系统,以增加新的功能特性及优化性能。
FPGA 嵌入式 电路 总线 C语言 IDT Altera 相关文章:
- 基于FPGA的片上系统的无线保密通信终端(02-16)
- 基于Virtex-5 FPGA设计Gbps无线通信基站(05-12)
- 基于FPGA的DVI/HDMI接口实现(05-13)
- 基于ARM的嵌入式系统中从串配置FPGA的实现(06-09)
- 采用EEPROM对大容量FPGA芯片数据实现串行加载(03-18)
- 赛灵思:可编程逻辑不仅已是大势所趋,而且势不可挡(07-24)