如何用FPGA实现算法的硬件加速
时间:12-09
来源:互联网
点击:
3 选择代码
当需要优化C语言代码以满足某些速度要求时,可能要运行一个代码仿制工具,或亲自检查该代码以便了解代码的哪个部分导致系统停滞。当然,这需要熟悉代码以便知道瓶颈在哪儿。
即便找出瓶颈所在,如何优化也是个挑战。有些方案采用本地字大小的变量、带预先计算值的查找表,以及通用软件算法优化。这些技巧可产生快几倍的执行速度效果。另一种优化C算法的方法是用汇编语言编写。过去这种方法可获得很好的提高,但现今的编译器在优化C算法上已做得很好,因此这种性能的提高是有限的。如果需要显著的性能提高,传统的软件算法优化技巧恐怕是不够的。
然而,利用硬件实施的算法比软件实施要强100倍,这不足为奇。那么,如何确定将哪些代码转为硬件实施呢?大可不必将整个软件模块转换为硬件,而应选择那些在硬件中运行得特别快的操作,比如将数据从一处复制到另一处、大量的数学运算以及任何运行多次的循环。如果一个任务由几个数学运算组成,还可以考虑在硬件中加速整个任务。有些时候,仅加速任务中的一个操作就可满足性能要求。
4 实例:CRC算法的硬件加速
由于大量且重复的计算,循环冗余校验(CRC)算法或任何“校验和”算法都是硬件加速的不错选择。下面通过一个CRC算法的优化过程来探讨如何实现硬件加速。
首先,利用传统的软件技巧来优化算法,然后将其转向定制指令以加速算法。我们将讨论不同实现方法的性能比较和折衷。
CRC算法可用来校验数据在传输过程中是否被破坏。这些算法很流行,因为它们具有很高的检错率,而且不会对数据吞吐量造成太大影响,因为CRC校验位被添加进数据信息中。但是,CRC算法比一些简单的校验和算法有更大的计算量要求。尽管如此,检错率的提高使得这种算法值得去实施。
一般说来,发送端对要被发送的消息执行CRC算法,并将CRC结果添加进该消息中。消息的接收端对包括CRC结果在内的消息执行同样的CRC操作。如果接收端的结果与发送端的不同,这说明数据被破坏了。
CRC算法是一种密集的数学运算,涉及到二元模数除法(modulo-2 division),即数据消息被16或32位多项式(取决于所用CRC标准)除所得的余数。这种操作一般通过异或和移位的迭代过程来实现,当采用16位多项式时,这相当于每数据字节要执行数百条指令。如果发送数百个字节,计算量就会高达数万条指令。因此,任何优化都会大幅提高吞吐量。
代码列表1中的CRC函数有两个自变量(消息指针和消息中的字节数),它可返回所计算的CRC值(余数)。尽管该函数的自变量是一些字节,但
算要逐位来执行。该算法并不高效,因为所有操作(与、移位、异或和循环控制)都必须逐位地执行。
列表1:逐位执行的CRC算法C代码。
/*
* The width of the CRC calculation and result.
* Modify the typedef for a 16or32-bit CRC standard.
*/
typedef unsigned char crc;
#define WIDTH (8 * sizeof(crc))
#define TOPBIT (1 <<(WIDTH - 1))
crc crcSlow(unsigned char const message[], int nBytes)
{
crc remainder = 0;
/*
* Perform modulo-2 division, a byte at a time.
*/
for (int byte = 0; byte <nBytes; ++byte)
{
/*
* Bring the next byte into the remainder.
*/
remainder ^= (message[byte] <<(WIDTH - 8));
/*
* Perform modulo-2 division, a bit at a time.
*/
for (unsigned char bit = 8; bit > 0; "bit)
{
/*
* Try to divide the current data bit.
*/
if (remainder &TOPBIT)
{
remainder = (remainder <<1) ^ POLYNOMIAL;
}
else
{
remainder = (remainder <<1);
}
}
}
/*
* The final remainder is the CRC result.
*/
return (remainder);
}
1).传统的软件优化
图3:带CRC外围电路和DMA的系统模块示意图。
让我们看一下如何利用传统的软件技巧来优化CRC算法。因为CRC操作中的一个操作数,即多项式(除数)是常数,字节宽CRC操作的所有可能结果都可以预先计算并存储在一个查找表中。这样,通过一个读查找表动作就可让操作按逐个字节执行下去。
采用这一算法时,需要将这些预先计算好的值存储在存储器中。选择ROM或RAM都可以,只要在启动CRC计算之前将存储器初始化就行。查找表有256个字节,表中每个字节位置包含一个CRC结果,共有256种可能的8位消息(与多项式大小无关)。
列表2示出了采用查找表方法的C代码,包括生成查找表crcInit()中数值的代码。
crc crcTable[256];
void crcInit(void)
{
crc remainder;
/*
* Compute the remainder of each possible dividend.
*/
for (int dividend = 0; dividend <256; ++dividend)
{
/*
* Start with the dividend followed by zeros.
*/
remainder = dividend <<(WIDTH - 8);
/*
* Perform modulo-2 division, a bit at a time.
*/
for (unsigned char bit = 8; bit > 0; "bit)
{
/*
* Try to divide the current data bit.
*/
if (remainder &TOPBIT)
{
remainder = (remainder <<1) ^ POLYNOMIAL;
}
else
{
remainder = (remainder <<1);
}
}
/*
* Store the result into the table.
*/
crcTable[dividend] = remainder;
}
} /* crcInit() */
crc crcFast(unsigned char const message[], int nBytes)
{
unsigned char data;
crc remainder = 0;
/*
* Divide the message by the polynomial, a byte at a time.
*/
for (int byte = 0; byte <nBytes; ++byte)
{
data = message[byte] ^ (remainder >> (WIDTH - 8));
remainder = crcTable[data] ^ (remainder <<8);
}
/*
* The final remainder is the CRC.
*/
return (remainder);
} /* crcFast() */
整个计算减少为一个循环,每字节(不是每位)有两个异或、两个移位操作和两个装载指令。基本上,这里是用查找表的存储空间来换取速度。该方法比逐位计算的方法要快9.9倍,这一提高对某些应用已经足够。如果需要更高的性能,可以尝试编写汇编代码或增加查找表容量以挤出更多性能来。但是,如果需要20、50甚至500倍的性能提高,就要考虑采用硬件加速来实现该算法了。
当需要优化C语言代码以满足某些速度要求时,可能要运行一个代码仿制工具,或亲自检查该代码以便了解代码的哪个部分导致系统停滞。当然,这需要熟悉代码以便知道瓶颈在哪儿。
即便找出瓶颈所在,如何优化也是个挑战。有些方案采用本地字大小的变量、带预先计算值的查找表,以及通用软件算法优化。这些技巧可产生快几倍的执行速度效果。另一种优化C算法的方法是用汇编语言编写。过去这种方法可获得很好的提高,但现今的编译器在优化C算法上已做得很好,因此这种性能的提高是有限的。如果需要显著的性能提高,传统的软件算法优化技巧恐怕是不够的。
然而,利用硬件实施的算法比软件实施要强100倍,这不足为奇。那么,如何确定将哪些代码转为硬件实施呢?大可不必将整个软件模块转换为硬件,而应选择那些在硬件中运行得特别快的操作,比如将数据从一处复制到另一处、大量的数学运算以及任何运行多次的循环。如果一个任务由几个数学运算组成,还可以考虑在硬件中加速整个任务。有些时候,仅加速任务中的一个操作就可满足性能要求。
4 实例:CRC算法的硬件加速
由于大量且重复的计算,循环冗余校验(CRC)算法或任何“校验和”算法都是硬件加速的不错选择。下面通过一个CRC算法的优化过程来探讨如何实现硬件加速。
首先,利用传统的软件技巧来优化算法,然后将其转向定制指令以加速算法。我们将讨论不同实现方法的性能比较和折衷。
CRC算法可用来校验数据在传输过程中是否被破坏。这些算法很流行,因为它们具有很高的检错率,而且不会对数据吞吐量造成太大影响,因为CRC校验位被添加进数据信息中。但是,CRC算法比一些简单的校验和算法有更大的计算量要求。尽管如此,检错率的提高使得这种算法值得去实施。
一般说来,发送端对要被发送的消息执行CRC算法,并将CRC结果添加进该消息中。消息的接收端对包括CRC结果在内的消息执行同样的CRC操作。如果接收端的结果与发送端的不同,这说明数据被破坏了。
CRC算法是一种密集的数学运算,涉及到二元模数除法(modulo-2 division),即数据消息被16或32位多项式(取决于所用CRC标准)除所得的余数。这种操作一般通过异或和移位的迭代过程来实现,当采用16位多项式时,这相当于每数据字节要执行数百条指令。如果发送数百个字节,计算量就会高达数万条指令。因此,任何优化都会大幅提高吞吐量。
代码列表1中的CRC函数有两个自变量(消息指针和消息中的字节数),它可返回所计算的CRC值(余数)。尽管该函数的自变量是一些字节,但
算要逐位来执行。该算法并不高效,因为所有操作(与、移位、异或和循环控制)都必须逐位地执行。
列表1:逐位执行的CRC算法C代码。
/*
* The width of the CRC calculation and result.
* Modify the typedef for a 16or32-bit CRC standard.
*/
typedef unsigned char crc;
#define WIDTH (8 * sizeof(crc))
#define TOPBIT (1 <<(WIDTH - 1))
crc crcSlow(unsigned char const message[], int nBytes)
{
crc remainder = 0;
/*
* Perform modulo-2 division, a byte at a time.
*/
for (int byte = 0; byte <nBytes; ++byte)
{
/*
* Bring the next byte into the remainder.
*/
remainder ^= (message[byte] <<(WIDTH - 8));
/*
* Perform modulo-2 division, a bit at a time.
*/
for (unsigned char bit = 8; bit > 0; "bit)
{
/*
* Try to divide the current data bit.
*/
if (remainder &TOPBIT)
{
remainder = (remainder <<1) ^ POLYNOMIAL;
}
else
{
remainder = (remainder <<1);
}
}
}
/*
* The final remainder is the CRC result.
*/
return (remainder);
}
1).传统的软件优化
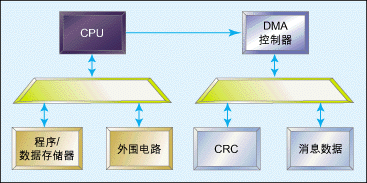
图3:带CRC外围电路和DMA的系统模块示意图。
让我们看一下如何利用传统的软件技巧来优化CRC算法。因为CRC操作中的一个操作数,即多项式(除数)是常数,字节宽CRC操作的所有可能结果都可以预先计算并存储在一个查找表中。这样,通过一个读查找表动作就可让操作按逐个字节执行下去。
采用这一算法时,需要将这些预先计算好的值存储在存储器中。选择ROM或RAM都可以,只要在启动CRC计算之前将存储器初始化就行。查找表有256个字节,表中每个字节位置包含一个CRC结果,共有256种可能的8位消息(与多项式大小无关)。
列表2示出了采用查找表方法的C代码,包括生成查找表crcInit()中数值的代码。
crc crcTable[256];
void crcInit(void)
{
crc remainder;
/*
* Compute the remainder of each possible dividend.
*/
for (int dividend = 0; dividend <256; ++dividend)
{
/*
* Start with the dividend followed by zeros.
*/
remainder = dividend <<(WIDTH - 8);
/*
* Perform modulo-2 division, a bit at a time.
*/
for (unsigned char bit = 8; bit > 0; "bit)
{
/*
* Try to divide the current data bit.
*/
if (remainder &TOPBIT)
{
remainder = (remainder <<1) ^ POLYNOMIAL;
}
else
{
remainder = (remainder <<1);
}
}
/*
* Store the result into the table.
*/
crcTable[dividend] = remainder;
}
} /* crcInit() */
crc crcFast(unsigned char const message[], int nBytes)
{
unsigned char data;
crc remainder = 0;
/*
* Divide the message by the polynomial, a byte at a time.
*/
for (int byte = 0; byte <nBytes; ++byte)
{
data = message[byte] ^ (remainder >> (WIDTH - 8));
remainder = crcTable[data] ^ (remainder <<8);
}
/*
* The final remainder is the CRC.
*/
return (remainder);
} /* crcFast() */
整个计算减少为一个循环,每字节(不是每位)有两个异或、两个移位操作和两个装载指令。基本上,这里是用查找表的存储空间来换取速度。该方法比逐位计算的方法要快9.9倍,这一提高对某些应用已经足够。如果需要更高的性能,可以尝试编写汇编代码或增加查找表容量以挤出更多性能来。但是,如果需要20、50甚至500倍的性能提高,就要考虑采用硬件加速来实现该算法了。
FPGA 嵌入式 电路 总线 C语言 IDT Altera 相关文章:
- 基于FPGA的片上系统的无线保密通信终端(02-16)
- 基于Virtex-5 FPGA设计Gbps无线通信基站(05-12)
- 基于FPGA的DVI/HDMI接口实现(05-13)
- 基于ARM的嵌入式系统中从串配置FPGA的实现(06-09)
- 采用EEPROM对大容量FPGA芯片数据实现串行加载(03-18)
- 赛灵思:可编程逻辑不仅已是大势所趋,而且势不可挡(07-24)