Xilinx UltraScale:为您未来架构而打造的新一代架构
不同的情况与组合。需要大量复杂的重复逻辑来应对这些可能的组合。此外,如果总线要求对四个数据包进行同时处理并写入到存储器中,那么可能需要对逻辑的某些部分进行加速(或扩展性能)。可以考虑通过逻辑加速或用四个独立的相同存储器控制器来相继处理多个数据包,但这些方式会进一步加大布线资源的压力,迫使架构必须具备更多的高性能、低歪斜布线资源。参见图4。
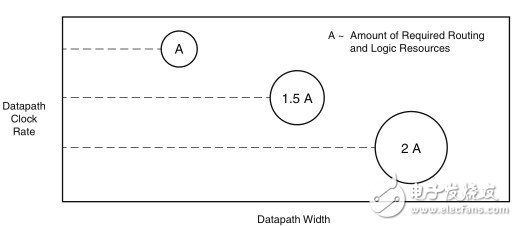
图4:增加数据路径时钟宽度和时钟速率需要更多逻辑和布线资源
半导体工艺的扩展影响互连技术
随着业界向20nm或更高级半导体工艺技术推进,在与铜线互连有关的RC延迟方面出
现了新的挑战,它会阻碍向新工艺节点演进所实现的性能提升效果。晶体管互连延迟的增加会直接影响所能实现的总体系统性能,因此更加需要所使用的布线架构能提供满足新一代应用要求的性能等级。UltraScale布线架构在开发过程中充分考虑了新一代工艺技术的特点,而且能明显减轻铜线互连的影响——如不进行妥善处理会成为系统性能瓶颈。
UltraScale互连架构:针对海量数据流进行优化
UltraScale新一代互连架构的推出体现了可编程逻辑布线技术的真正突破。赛灵思致力于满足从多Gb智能包处理到多Tb数据路径等新一代应用需求,即必须支持海量数据流。在实现宽总线逻辑模块(将总线宽度扩展至512位、1024位甚至更高)的过程中,布线或互连拥塞问题一直是影响实现时序收敛和高质量结果的主要制约因素。过于拥堵的逻辑设计通常无法在早期器件架构中进行布线;即使工具能够对拥塞的设计进行布线,最终设计也经常需要在低于预期的时钟速率下运行。而UltraScale布线架构则能完全消除布线拥塞问题。结论很简单:只要设计合理,就能进行布线。
我们来做个类比。位于市中心的一个繁忙十字路口,交通流量的方向是从北到南,从南到北,从东到西,从西到东,有些车辆正试图掉头,所有交通车辆试图同时移动。这样通常就会造成大堵车。现在考虑一下将这样的十字路口精心设计为现代化高速公路或主干道,情况又会如何。道路设计人员设计出了专用坡道(快行道),用以将交通流量从主要高速路口的一端顺畅地疏导至另一端。交通流量可以从高速路的一端全速移动到另一端,不存在堵车现象。
赛灵思为UltraScale架构加入了类似的快行道。这些新增的快行道可供附近的逻辑元件之间传输数据,尽管这些元件并不一定相邻,但它们仍通过特定的设计实现逻辑上的连接。这样,UltraScale架构所能管理的数据量就会呈指数级上升,如图5所示。
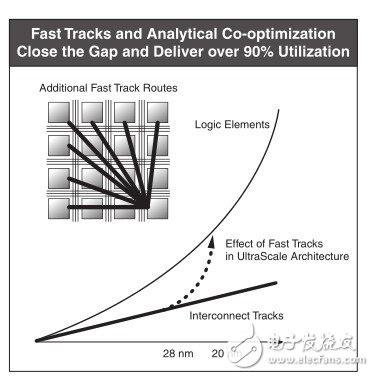
图5:增加真实有效的路由路径可以帮助解决日益增长的系统复杂性
UltraScale架构堆叠硅片互联技术全面强化所有功能
很少有开发的技术能够像堆叠硅片互联(SSI)技术集成那样对器件容量和性能产生如此重大的影响,这已得到了赛灵思第一代基于7系列All Programmable器件的3D IC产品的验证。集成SSI技术后,设计人员可以构建出工艺技术领先行业标准整整一代水平的更大型器件。而且该技术在赛灵思第二代基于UltraScale架构的3D IC产品中也同样会达到这种效果。
由于3D IC中硅片间通信连接比独立封装的硅片间通信连接更密集、更快速,因此硅片间的通信所需功耗更低(假设硅片无需驱动硅片到封装间互连以及板级互连的附加阻抗)。所以,与独立封装的硅片相比,SSI技术的集成能够在显著扩大容量和性能的同时降低功耗。此外,由于无法轻易访问电路板层面的硅片间通信,这样系统安全性也得到了加强。
Virtex®UltraScale和Kintex®UltraScale系列成员在第二代3D IC中的连接资源数量以及相关的硅片间带宽都实现了阶梯式增长。布线资源和硅片间带宽的大幅增长确保了新一代应用能够在实现其高器件利用率的前提下达到目标性能和时序收敛。
更多内容,请点击链接下载:http://www.elecfans.com/soft/5/2013/20130715324025.html
UltraScale架构 16nm All Programmable 20nm Xilinx 相关文章:
- UltraScale可编程架构如何解决互连问题?(06-09)
- 常见问题解答:Xilinx采用首个ASIC级UltraScale可编程架构(06-09)
- 赛灵思UltraScale架构:业界首款ASIC级All Programmable架构(06-09)
- 赛灵思ASIC级UltraScale架构要素及相关说明(06-09)
- 16nm工艺的麒麟650也不是吃干饭的料!(04-18)
- 解密业界首款16nm产品核心技术(02-11)