ARM Cortex-M 处理器家族介绍和比较
4.2Bit-band feature位段
Cortex-M3 和Cortex-M4处理器支持一个叫做位段的可选功能,允许有两段通过位段别名地址实现可以位寻址的1MB的地址空间(一段在从地址0x20000000起始的SRAM空间。另一段是从地址0x40000000起始的外围设备空间)。Cortex-M0, M0+ 和 Cortex-M1不支持位段(bit-band)功能,但是可以利用ARM Cortex-M系统设计套件(CMSDK)中的总线级组件在系统层面实现位段(bit-band)功能。Cortex-M7不支持位段(bit-band),因为M7的Cache功能不能与位段一块使用(Cache控制器不知道内存空间的别名地址)。
ARMv8-M的TrustZone 不支持位段, 这是由于位段别名需要的两个不同的地址可能会在不同的安全域中。对于这些系统,外围设备数据的位操作反而可以在外围设备层面处理(例如,通过添加位设置和清除寄存器)。
4.3存储器保护单元(MPU)
除了Cortex-M0, 其他的Cortex-M处理器都有可选的MPU来实现存储空间访问权限和存储空间属性或者存储区间的定义。运行实时操作系统的嵌入式系统, 操作系统会每个任务定义存储空间访问权限和内存空间配置来保证每个任务都不会破坏其他的任务或者操作系统内核的地址空间。Cortex-M0+, Cortex-M3 和 Cortex-M4都有8个可编程区域空间和非常相似的编程模型。主要的区别是Cortex-M3/M4的MPU允许两级的存储空间属性(例如,系统级cache类型),Cortex-M0+仅支持一级。Cortex-M7的MPU可以配置成支持8个或者16个区域,两级的存储空间属性。Cortex-M0 和 Cortex-M1不支持MPU.
Cortex-M23 和 Cortex-M33也支持MPU选项,如果实现了TrustZone安全扩展(一个用于安全软件程序,另一个用于非安全软件程序)可以有最多两个MPU。
4.4单周期I/O接口
单周期I/O接口是Cortex-M0+处理器独特的功能,这使Cortex-M0+可以很快的运行I/O控制任务。Cortex-M大多数的处理器的总线接口是基于AHB Lite或者AHB 5协议的,这些接口都是流水实现总线协议,运行在高时钟频率。但是,这意味着每个传输需要两个时钟周期。单时钟周期I/O接口添加了额外的简单的非流水线总线接口,连接到像GPIO(通用输入输出)这样的一部分设备特定的外设上。结合单周期I/O和Cortex-M0+天然比较低的跳转代价(只有两级流水线),许多I/O控制操作都会比大多数其他微控制器架构的产品运行的更快。
5性能考虑
5.1通用数据处理能力
在通用微控制器市场,benchmark数据经常用来衡量微控制器的性能,表7是Cortex-M处理器常用benchmark测试的性能数据:
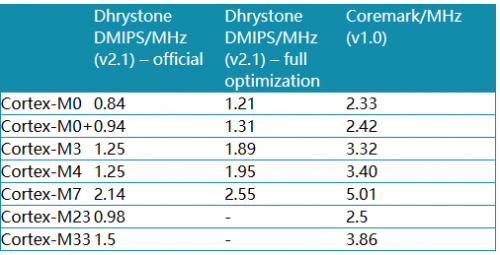
表 7: Cortex-M处理器常用benchmakr的性能分数
(来源:CoreMark.org 网站 and ARM 网站)
关于Dhrystone需要注意的是用来测试的Dhrystone是由官方源程序在没有启用inline and 和multi-file compilation编译选项的情况编译出来的(官方分数)。但是,很多微控制器厂商引用的是完全优化编译的Dhrystone测试出来的数据。
但是,benchmark工具的性能测试数据可能无法准确反应你的应用能达到的性能。例如,单周期I/O接口和DSP应用中使用SIMD,或者Cortex-M4/M7中使用FPU的加速效果并没有在这些测试数据中体现出来。
通常,Cortex-M3 和 Cortex-M4由于以下原因提供了更高的数据处理性能:
·更丰富的指令集
·哈佛总线架构
·写缓存(单周期写操作)
·跳转目标的预测取指
Cortex-M33也是基于哈佛总线的架构,有丰富的指令集。但是不像Cortex-M3 和 Cortex-M4,Cortex-M33处理器流水线是重新设计的高效流水线,支持有限的指令双发射(可以在一个时钟周期中执行最多两条指令)。
Cortex-M7支持更高的性能,这是因为M7拥有双发射六级流水线并支持分支预测。而且,通过支持指令和数据Cache,和即便使用慢速内存(例如,嵌入式Flash)也能避免性能损失的紧耦合内存,来实现更高的系统级性能。
但是,某些I/O操作密集的任务在Cortex-M0+上运行更快,这是因为:
·更短的流水线(跳转只需要两个周期)
·单周期I/O端口
当然也有设备相关的因素。例如,系统级设计,内存的速度也会影响到系统的性能。
你自己的应用程序经常是你需要的最好的benchmark。CoreMark分数是另外一个处理器两倍的处理器并不意味着执行你的应用也快一倍。对I/O密集操作的应用来说,设备相关的系统级架构对性能有巨大的影响。
5.2中断延迟
性能相关的另外一个指标是中断延迟。这通常用从中断请求到中断服务程序第一条指令执行的时钟周期数来衡量。表8列出了Cortex-M处理器在零等待内存系统条件下的中断延迟比较。
- 分析:2011年商用PC市场发展情况乐观(03-01)
- 富士通半导体与ARM签署全面授权协议(03-07)
- ARM手机芯片市场份额已超90% 英特尔倍感压力(03-17)
- 中国正探寻如何快速进驻HPC芯片领域(03-23)
- 美国国家半导体推出10款全新SolarMagic IC芯片 (05-03)
- IDC:中国一季度平板电脑出货量达86万台(07-20)