GPU/FPGA尽显鸡肋,谁才能拿下人工智能战略制高点
深度学习作为新一代计算模式,近年来,其所取得的前所未有的突破掀起了人工智能新一轮发展热潮。深度学习本质上是多层次的人工神经网络算法,即模仿人脑的神经网络,从最基本的单元上模拟了人类大脑的运行机制。由于人类大脑的运行机制与计算机有着鲜明的不同,深度学习与传统计算模式有非常大的差别。
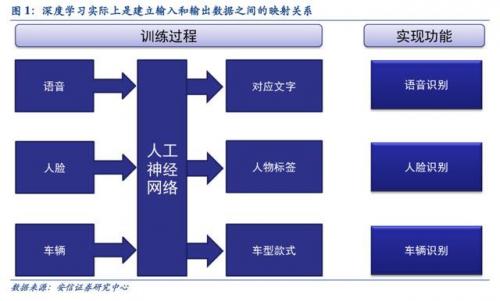
深度学习的人工神经网络算法与传统计算模式不同,它能够从输入的大量数据中自发的总结出规律,从而举一反三,泛化至从未见过的案例中。因此,它不需要人为的提取所需解决问题的特征或者总结规律来进行编程。人工神经网络算法实际上是通过大量样本数据训练建立了输入数据和输出数据之间的映射关系,其最直接的应用是在分类识别方面。例如训练样本的输入是语音数据,训练后的神经网络实现的功能就是语音识别,如果训练样本输入是人脸图像数据,训练后实现的功能就是人脸识别。

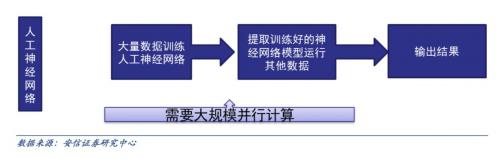
传统计算机软件是程序员根据所需要实现的功能原理编程,输入至计算机运行即可,其计算过程主要体现在执行指令这个环节。而深度学习的人工神经网络算法包含了两个计算过程:
1、用已有的样本数据去训练人工神经网络;
2、用训练好的人工神经网络去运行其它数据。 这种差别提升了对训练数据量和并行计算能力的需求,降低了对人工理解功能原理的要求。
传统计算架构无法支撑深度学习的海量数据并行运算
根据上文的分析我们可以看到,深度学习与传统计算模式最大的区别就是不需要编程,但需要海量数据并行运算。
传统处理器架构(包括x86 和ARM 等)往往需要数百甚至上千条指令才能完成一个神经元的处理,因此无法支撑深度学习的大规模并行计算需求。
为什么传统计算架构无法支撑深度学习的大规模并行计算需求?因为传统计算架构计算资源有限。
传统计算架构一般由中央运算器(执行指令计算)、中央控制器(让指令有序执行)、内存 (存储指令)、输入(输入编程指令)和输出(输出结果)五个部分构成,其中中央运算器和中央控制器集成一块芯片上构成了我们今天通常所讲的 CPU。
我们从CPU 的内部结构可以看到:实质上仅单独的 ALU 模块(逻辑运算单元)是用来完成指令数据计算的,其他各个模块的存在都是为了保证指令能够一条接一条的有序执行。这种通用性结构对于传统的编程计算模式非常适合,同时可以通过提升CPU 主频(提升单位时间执行指令速度)来提升计算速度。

但对于并不需要太多的程序指令,却需要海量数据运算的深度学习的计算需求,这种结构就显得非常笨拙。尤其是在目前功耗限制下无法通过提升CPU 主频来加快指令执行速度,这种矛盾愈发不可调和。因此,深度学习需要更适应此类算法的新的底层硬件来加速计算过程,也就是说,新的硬件对我们加速深度学习发挥着非常重要的作用。目前主要的方式是使用已有的GPU、FPGA 等通用芯片。

新计算平台生态正在建立
GPU 因其并行计算优势最先被引入深度学习
GPU作为应对图像处理需求而出现的芯片,其海量数据并行运算的能力与深度学习需求不谋而合,因此,被最先引入深度学习。
2011 年吴恩达率先将其应用于谷歌大脑中便取得惊人效果,结果表明12 颗NVIDIAD 的GPU 可以提供相当于2000 颗CPU 的深度学习性能,之后纽约大学、多伦多大学以及瑞士人工智能实验室的研究人员纷纷在GPU 上加速其深度神经网络。

英伟达(Nvidia)是全球可编程图形处理技术的领军企业,公司的核心产品是GPU 处理器。
英伟达通过GPU 在深度学习中体现的出色性能迅速切入人工智能领域,又通过打造NVIDIA CUDA 平台大大提升其编程效率、开放性和丰富性,建立了包含CNN、DNN、深度感知网络、RNN、LSTM 以及强化学习网络等算法的平台。
根据英伟达公开宣布的消息来看,在短短两年里,与NVIDIA 在深度学习方面展开合作的企业便激增了近35 倍,增至3,400 多家企业,涉及医疗、生命科学、能源、金融服务、汽车、制造业以及娱乐业等多个领域。
英伟达针对各类智能计算设备开发对应GPU,使得深度学习可以渗透各种类型的智能机器
IT 巨头争相开源人工智能平台
深度学习系统一方面需要利用庞大的数据对其进行训练,另一方面系统中存在上万个参数需要调整。
IT 巨头开源人工智能平台,旨在调动更多优秀的工程师共同参与发展其人工智能系统。开放的开发平台将带来下游应用的蓬勃发展。最典型的例子就是谷歌开源安卓平台,直接促成下游移动互
- 嵌入式系统与FPGA的最新动向(05-18)
- FPGA走向硅片融合时代(07-12)
- 20nm时代,FPGA或将拔得头筹(11-30)
- 没有退路的FPGA与晶圆代工业者(01-03)
- 电源管理成为FPGA新的技术突破口(12-16)
- 数字电源为FPGA带来高效率(12-16)