谈第二代异构计算,OpenPOWER有CAPI+FPGA不服来战
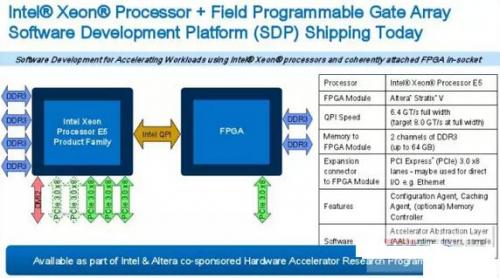
采用QPI接口与CPU互联,明摆着是冲着缓存一致性而来,这与CAPI的思路异曲同工,并且在服务器的配置上给出了新的可能(比如FPGA芯片Socket化或直接板载),这与CAPI有了明显的不同,可谓各有利弊,但共同点都是开启了第二代异构计算的时代
当越来越多的FPGA加速芯片以各种缓存一致性的方式接入系统之后,由于FPGA的SRAM高速编程模式,理论上讲FPGA可以迅速的且无限次的更新内置的AFU,以应对不同的应用加速需求。这就给我们打开了一个想像空间--能否像Docker管理容器镜像那样,基于云+端的概念建立起一个AFU镜像的集散中心呢?事实上,OpenPOWER联盟已经在这么做了--建立AFU镜像商店,并已经落户SuperVessel Cloud(超能云)之上,目前已经有多个AUF镜像可用选择( https://crl.ptopenlab.com:8800/acceleration )。
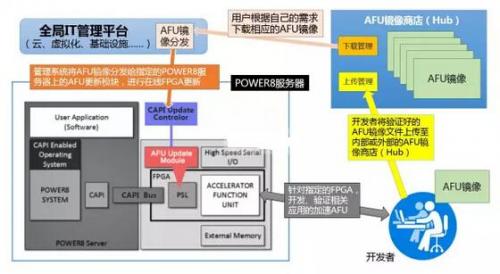
OpenPOWER CAPI-FPGA加速卡AFU镜像商店的更新流程
届时,任何相关的开发者、ISV都可以将自己针对某些具体的FPGA卡(经CAPI认证)所编写的AFU镜像(其实就是FPGA的编程配置文件),上传至AFU商店供其他用户免费或有偿使用。相关的AFU用户则可以像Docker那样,根据自己应用加速的需求与FPGA加速卡的型号,免费或付费下载相应的AFU镜像,通过全局的管理平台,分发给指定服务器上的CAPI更新控制器,由后者与指定的FPGA加速卡(一台服务器可以有多块加速卡,选择更新)PSL内的AFU更新模块一起加载AFU镜像。加载的方式有两种,一种是完整的FPGA重写(所有的门电路重写,包括PSL),另一种则是AFU单独更新。前者需要重起服务器,而后者则可以在线动态更新。目前100万门的FPGA的完整配置文件容量也就在50MB左右,由于是基于SRAM的硬件编程,100ms内即可更新完毕,用户几乎没有察觉,但服务器的加速功能就已经完全改变了。
我们可以试想一下这样的场景,对于某个内置CAPI+FPGA加速器的服务器集群,可以灵活的根据工作负载的需求改变FPGA中的AFU模块,让这个集群迅速具备针对新负载的加速能力,这对于集群高效的多场景灵活复用显然是很有帮助的,而这种模式也是GPGPU、DSP、ASIC等加速方式很难做到的。
展望未来,从某种角度上讲,GPGPU与FPGA在未来的应用系统中,将根据自身的特长有所侧重。如果将CPU比作人的话,GPGPU更像是高级计算器,为人类提供强大的科学计算的能力,做好学术研究,而FPGA更像是为某类工作定制的效率工具,执行大量固定而高度重复化的工作,大幅度提高人类的日常生活与工作效率(比如洗衣机、生产机器人),而人在未来更多的就是负责管理,用好计算器与效率工具--CPU的角色相信也会如此,随着技术的不断发展,更多的浮点与整数运算任务将会被GPGPU、FPGA、DSP、ASIC等不同的加速器所分担。
进化至第二代分布式计算?
基于上文所分析的CAPI+FPGA所展现出来的能力,如果我们进一步从单服务器延展至整个分布式计算的架构,就可以从一个更为广阔的全局视角来分析第二代异构计算所带来的关键影响。不久前,IBM提出的"第二代分布式计算"理念也正是基于这一全局的层次来建立的(据说在9月16日会召开发布会进行专门的阐述 )。
IBM中国研究院的高级研究员陈飞表示,IBM提出的第二代分布式计算有四个重要的特征,第一个特征:加速器的软硬件接口有统一的接口规范,以便于更好的协同管理与普适(第一代分布式计算的接口标准较为统一,毕竟只有CPU本身,相对更标准化),这方面CAPI就是一个标准化接口的尝试。第二个特征:加速器可以动态地在线发现以及加载。比如不需要系统的重启,但现在的加速器如果要改变功能,一般都要要求重启,或者是重启一些软件服务,但CAPI+FPGA则没有这个顾虑。第三个特征:分布式的系统要具备全局异构资源的调度能力,也就是说它能决定应用是运行在一个具有加速器的计算节点上,还是跑在一个普通的纯CPU的计算节点上。第四个特征:应该软件本身,具备兼容CPU运行模式和异构硬件运行模式的能力。

NVIDIA推出NVLINK互联总线,除了可作为GPU之间的互联外,还可用于CPU与GPU的互联,并也将具备缓存一致性的内存访问能力。IBM的POWER9处理器(预计2017年下半年发布)将具备这一接口,这就意味着在POWER9平台上NVIDIA的GPU也会获得与CAPI同样的对等访问能力,这样的GPGPU加速能力也将是POWER9独有的(在英特尔x86平台上,与CPU的互联连接仍然是传统的PCIe模式,NVLINK仅用于NVIDIA GPU之间的互联),对IBM所提出的第二代分布式计算理念无疑是一个有力支撑
从以上定义中,我们可以看出,正是CAPI+FPGA所具备的一些关键特性(缓存一致性、在线更新性、AFU替换能力等)为IBM所提出的第二代分布式计算打下了理论基础。当然,对于这个定义,我仍然有一些异议,毕竟从总体上讲,这个分布式处理的基础架构与应用分布处理的模式,和第一代相比并没有本质的不同,更多是分布式节点上处理模式的创新,并且由于加速体系标准的更加多样化,也让其普适性受到怀疑,除非有非常强大的全局管理平台来屏蔽掉底层的硬件差异性,否则全局上的"加速孤岛"现象不可避免(虽然对于具体的用户来说,这可能不是问题)。
但是不管怎样,第二代异构计算的模式,的确打开了我们的想像空间,它是否真的带来理想中的第二代分布式计算体系,还有赖于IBM、英特尔以及加速器、方案集成等前沿厂商的共同努力!不过,可以肯定的是,不管这种新兴的处理模式将如何称谓,它对于新时代下的信息处理平台(大数据分析、物联网、人工智能、机器学习等)所带来的明显帮助,以及为最终用户所创造的巨大价值,都将是毋庸置疑的!
- 台积电满脸“苹果光”(05-06)
- 智能手机陷入“千机一面”怪圈(06-08)
- CPU/APU:一场无声的反垄断技术较量(06-21)
- 移动设备纷纷采用多核CPU遭质疑:性能过剩(01-12)
- 系统级芯片SoC真的能取代传统CPU?(04-26)
- 国产CPU:放手一搏正当时(05-11)