谈第二代异构计算,OpenPOWER有CAPI+FPGA不服来战
从以上图片可以看出,由于一致性特色的加入,让CAPI加速卡避开了传统I/O设备的驱动模式,直接以"硬件代理"的方式嵌入应用的执行,因此在总体的命令开销方面有明显的减少。这直接带来的效果就是延迟大幅降低--总延迟约只有传统加速模式的1/36,并且带来了更大的好处--由于没有了传统I/O设备层,应用平台为了适配加速器的编程修改非常小,应用开发者完全可以将应用做成自适应模式,在非CAPI平台上采用传统的处理模式,当发现系统有CAPI加速器则自动打开CAPI模式,这显然非常有利于CPAI加速模式在相关应用领域里的普及。
在具体的应用环境中,目前CAPI还不能用于虚拟化平台(比如KVM),但完全支持基于Linux核心的Docker容器平台(现在的CAPI全面支持Ubuntu 14.10)。按照IBM未来的发展规划,新一代CAPI正在路上,它将基于PCIe 4.0规格(也可能会采用新的总线接口),并稍加改动,连接带宽较PCIe 4.0稍微提高,以抵销CAPI协议的开销,从而让加速器可以充分利用到PCIe的带宽。另外,CAPI的虚拟化(多个应用可以分时复用加速器)也将是必然的,融入云计算平台的统一管理也将水到渠成。并且单一PSL未来可以挂载多个AFU,在FPGA内部最多可以同时具备4个AFU,PSL分别为它们保存各自的虚拟空间地址,并与CAPP一起保持缓存一致性,这就相当于给系统同时配备了4个外挂核心。在操作系统方面,未来还将支持AIX、RedHat等OS,这将意味着除了PowerLinux平台,传统的AIX POWER服务器上的应用也将能享受到CAPI加速。
OpenPOWER CAPI+FPGA应用实战
借助于OpenPOWER联盟,很多厂商都投入到了CAPI+FPGA的加速卡设计中,中国的恒扬科技(Semptian)即是其中之一,其最新推出的Semptian NSA-120是一款基于XILINX Kintex UltraScale FPGA的CAPI PCIe板卡,采用PCIE x8 Gen3 接口规格,支持两路DDR3 1600 SODIMM(容量为2x8GB),而首先投入的AFU,是针对大数据存储中常用的纠删码(Erasure Code)的编/解码加速。
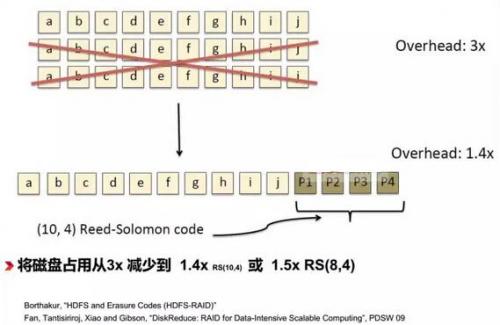
纠删码是应对降低海量分布式存储占用空间的常用手段,相对于传统的3复本冗余的存储模式(相当于3x容量占用),纠删码冗余的存储容量只相当于原数据量的1.4x,降低了超过50%的存储空间需求,但在大规模数据读写过程中,纠删码的实时编/解码运算对于服务器CPU来说将是一个比较大的占用,在分布式应用架构中,这意味着将影响应用本身的性能

通过Semptian NSA-120的加速,获得了明显的纠删码的性能提升,如果再多加一块Semptian NSA-120(双CPU配置时最多可插4块),性能还会加倍提高

为了进一步方便ISV与AFU的开发者,恒扬科技专门提供了NPL(NSA Platform Layer),即FPGA基础平台,帮助AFU开发者硬件无感知的开发AFU算法单元
根据恒扬科技大数据采集与分析产品经理张军的介绍,目前FPGA的编程环境已经有了很大的改善,这其中OpenCL开发平台的发展起到了重要的推进作用。虽然现在仍然很初级,但对于传统的应用开发者来说,借助OpenCL开放的标准化平台,已经可以相对较为容易的上手,而在底层编程部分,仍然会通过FPGA厂商的专用工具进行HDL编译,再写入FPGA。此外,FPGA厂商也在像NVIDIA那样,提供自己的集成开发环境(IDE),它的作用相当于CUDA之于GPGPU,为开发者提供更完整的工具包,加速FPGA的编程。比如赛灵思的 SDAccel开发环境,就可为赛灵思的FPGA加速OpenCL、C和C++内核的开发与部署。相应的CAPI-FPGA加速卡厂商,也会提供底层平台,方便开发者基于自己的板卡进行AFU开发。比如恒扬科技就提供了NPL和相关的SDK,可以让开发者专心于AFU的算法实现。
另一个典型的CAPI加速实例则是外置存储加速,IBM基于CAPI控制卡+自己的FlashSystem全闪存阵列,提供了一套NoSQL数据引擎,由于CAPI将传统的PCIe控制卡的I/O开销省去,大大降低了系统延迟,成为KVS数据平台更好的选择。
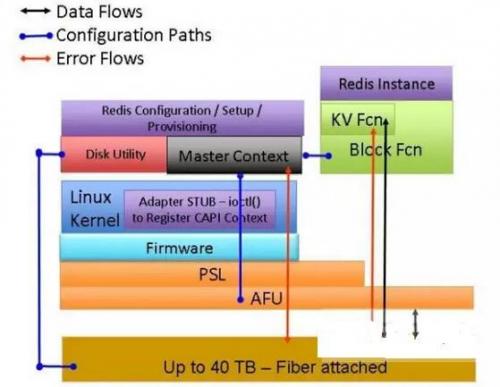
IBM基于支持CAPI+全闪存阵列而推出NoSQL数据加速引擎,配套全闪存阵列可以通过CAPI加速卡直接访问应用内存空间,大大降低了数据传输的延迟,非常有利于单笔数据访问量少,但IO密集的键值存储(KVS,Key-Value Store)平台
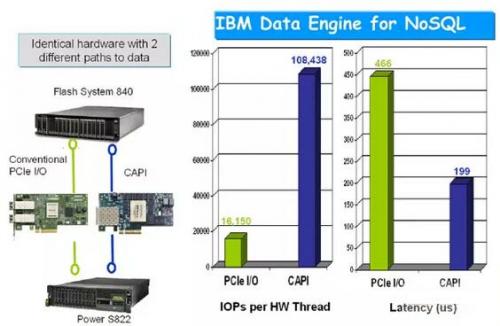
通过与非CAPI控制卡连接的性能相对比,可以看出由于CAPI连接不是传统的I/O驱动模式,而近似于CPU直联,所以在IOPS性能与延迟性能上较传统的PCIe控制卡有明显的提升,不过如果是大数据块传输,CAPI控制卡在总带宽上可能会有一定劣势,但到下一代CAPI这将不再是问题
第二代异构计算与未来应用愿景
如果说以GPGPU为主,大幅度提高系统浮点运算能力是第一代异构加速计算的典型特征的话,我们现在可以基本总结出以FPGA为主,所谓的第二代异构计算的一些重要特征:第一:具备缓存一致性和对等的内存访问能力,这是最为重要的特征,与第一代异构计算有了本质的不同,并对应用编程具备了明显的友好性;第二:基于FPGA可灵活配置加速模块,毫无疑问,在第二代异构计算中,FPGA将是一大主角,它本身灵活的可编程性为应用加速提供了丰富的应用场景;第三、它将隆重开启整数运算加速的大门,随着FPGA编程的便利性进一步提高,FPGA的整数型加速将会迅速普及(当然绝不是说FPGA不能用于浮点加速,只是看应用比例),这对于当前的大数据、海量视频处理、图像匹配等新兴需求不谋而合,就像当初GPGPU与科学计算的发展相得益彰一样,第二代异构计算将把相应的整数型应用的性能带到新的高度。
当然,看到这一趋势的不仅仅是IBM与OpenPOWER,CPU巨头英特尔以167亿美元收购FPGA第二大厂Altera的用意也不言自明。在不久前结束的IDF15上(英特尔信息技术峰会2015美国站),英特尔正式发布了CPU通过QPI直联FPGA的方案设计。
- 台积电满脸“苹果光”(05-06)
- 智能手机陷入“千机一面”怪圈(06-08)
- CPU/APU:一场无声的反垄断技术较量(06-21)
- 移动设备纷纷采用多核CPU遭质疑:性能过剩(01-12)
- 系统级芯片SoC真的能取代传统CPU?(04-26)
- 国产CPU:放手一搏正当时(05-11)