谈第二代异构计算,OpenPOWER有CAPI+FPGA不服来战
OpenPOWER CAPI简介
OpenPOWER是以IBM、NVIDIA、Mellanox、Google、TYAN为首的5家公司,于2013年8月发起的一个技术推广联盟,截止到2015年6月,OpenPOWER会员数量超过了130家,来自于中国的厂商就超过了20家。
OpenPOWER所推广的技术就是基于IBM POWER8及以后的处理器与平台技术,这其中POWER8处理器所具备的一致性加速处理器接口(CAPI,Coherent Accelerator Processor Interface)就是一个重要的技术点,也正是它让FPGA迅速成为了新一代异构计算的亮点。
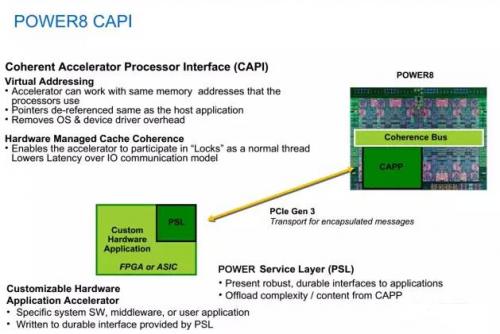
CAPI的基本原理就是通过在POWER处理器(从POWER8开始)内部设置一致性加速处理器代理(CAPP,Coherent Accelerator Processor Proxy),而在外置的加速卡上,则内置POWER处理器服务层(PSL,POWER Service Layer),其与CAPP配合,为加速卡在CPU上打通了一个"后门"。加速卡(PSL)与CPU(CAPP)之间采用成熟的PCIe总线+CAPI协议进行数据传输,但不用走复杂的PCIe I/O模式,并获得了与CPU对等访问虚拟内存地址的能力。目前POWER8内部共有两个CAPP,每个CPU可外接两个CAPI加速卡
CAPI最为关键的重点就在于一致性(Coherent),确切的说它包含两个概念,它们之间是相辅相成的。第一个就是虚拟地址空间访问的一致性,这与传统的总线地址或物理地址访问的模式有了本质的区别。虚拟地址空间访问的一致性,是CAPI加速器实现与CPU对等访问的根本体现,否则在应用编程上仍然要有较大的调整。
一致性的第二个含义就是缓存一致性,在IBM提供的PSL硬核模块(可以集成于合作伙伴的芯片,或写入FPGA)中包含有256KB的缓存,而在CPU内部,CAPP则负责维护CAPI一侧的缓存行目录,以保证CPU级的缓存一致性(CC,Cache Coherency )。这就相当于在CPU内部额外增加了一个特殊的处理核心(给CPU开了一个外挂),其对于内存的访问能力与其他"正常的"CPU核心是一致的,纳入到统一的CC体系,这就与传统的通过PCIe插卡实现加速的方式有了本质的不同。
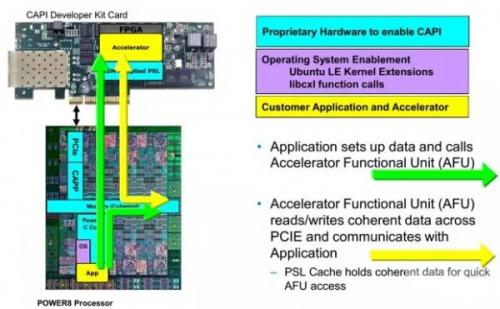
在具体的FPGA加速应用中,应用透过CAPP与PSL的连接,挂载(绑定)加速卡,PSL与CAPP一起协同,让FPGA里的加速功能单元(AFU,Accelerator Functional Unit)实现与CPU的对等访问--可直接看到应用所指向的虚拟内存地址,并通过PCIe总线与应用沟通
在CAPI+FPGA的应用中,用户先将相关应用的加速算法,以HDL(目前主要是Verilog HDL和VHDL)写入FPGA,构成加速功能单元(AFU),它就是上文提到的那个"外挂的特殊CPU核心"。然后再通过PSL与CAPP的协同,将AFU"嵌入"到CPU里,被应用发现并直接调用。AFU可以直接读写应用所管理的虚拟内存空间,以一种嵌入式的外挂处理模式实现应用的加速。从某种意义上说,"外挂"的AFU的作用有点像CPU的加速指令集(比如SSE、MMX等),但可灵活变换且效率明显更高。
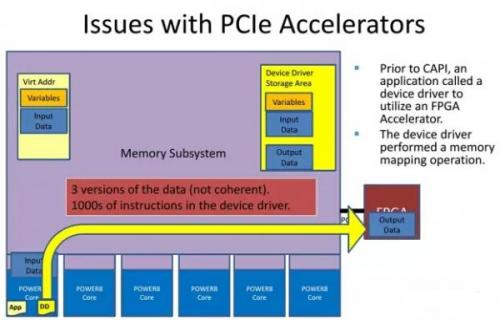
在非CAPI加速体系中,传统的加速卡是以一个I/O设备存在的,这必然需要虚拟地址的重新影射,从而在内存中会生成3个数据副本,并需要大量的驱动访问指令,后果就是延迟的增加
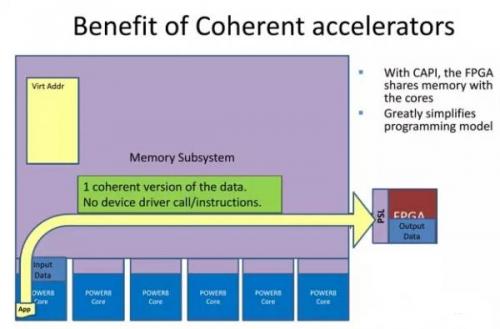
在CAPI体系下,CAPI加速器与CPU实现了对等访问,共享虚拟地址,数据无需转手,直接在加速器与应用之间进行沟通。在实际使用时也很简单,CAPI加速卡可以安装在任何提供PCIe3.0接口的OpenPOWER Linux服务器上。应用软件只需要调用一个CAPI函数,即可直接利用CAPI加速,而在对Linux更新驱动后,即可直接调用原有IM/GM等兼容接口函数
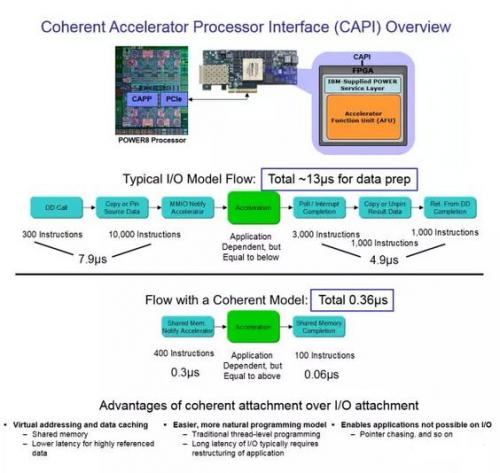
由于CAPI接口并非传统意义上的I/O驱动模式,直接走硬件代理与CPU沟通,所以从应用的全局视角,数据的访问步骤明显减少(FPGA与CPU对等访问),让数据访问效率大幅度提高,总延迟约是传统模式的1/36,同时这种应用加速设计,对于应用的编程修改影响最小
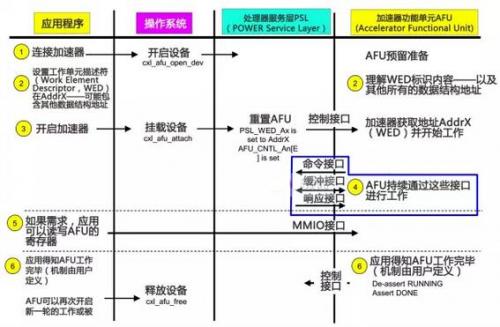
CAPI加速器从准备加速到完成加速的沟通流程相当的简洁明了,可以基本总结为--应用:CAPI加速器,我看到你了;CAPI加速器:应用,我已经为你准备好了;应用:我要处理的数据在内存地址AddrX处,剩下的工作就交给你了;CAPI加速器:好的,没问题;(开始循环加速)……CAPI加速器:报告应用,已经处理完毕;应用:好的,你先休息吧,有事我再叫你
从以上图片可以看出,由于一致性特色的加入,让CAPI加速卡避开了传统I/O设备的驱动模式,直接以"硬件代理"的方式嵌入应用的执行,因此在总体的命令开销方面有明显的减少。这直接带来的效果就是延迟大幅降低--总延迟约只有传统加速模式的1/36,并且带来了更大的好处--由于没有了传统I/O设备层,应用平台为了适配加速器的编程修改非常小,应用开
- 台积电满脸“苹果光”(05-06)
- 智能手机陷入“千机一面”怪圈(06-08)
- CPU/APU:一场无声的反垄断技术较量(06-21)
- 移动设备纷纷采用多核CPU遭质疑:性能过剩(01-12)
- 系统级芯片SoC真的能取代传统CPU?(04-26)
- 国产CPU:放手一搏正当时(05-11)