82倍于摩尔定律?移动GPU乱象解析
图形和性能表现,那我们只能抱歉的通知您--仅材质包一项,您就要分别准备ECT1、DXTC、PVRTC以及ATITC四种。虽然ECT1是共有格式,但因为缺乏一个强力的领导者进行推动和革新,这种材质压缩格式在MALI以外的其他显示架构中的执行效率均非常低落,真想让游戏变得漂亮真实,您无论如何都绕不开微软、Imagination以及Adreno共同造就的"想成功请多付出3倍努力"的局面。
浮夸的性能增长,没有游戏规则来约束和规范竞争,这就是移动显示领域的全部了么?显然不是。一切乱象的根源,同时也是一切乱象中最根本的这一位,其实早在去年的第一组《口袋里的战争》系列中就已经与我们见过面了:
在一个以电池容量为最基本约束底限的领域,是谁让你们几个不要命的去拼硬件规格的?
更有效率的使用晶体管?who care?
手机和平板电脑用户最关心的是什么?是我的平板电脑换了个多强悍的CPU/GPU?是我的手机跑GLBenchmark/安兔兔能跑多少万分?显然不是。这些东西对用户没有一分钱的意义。智能移动平台用户最关心的事情永远都有且只有一个,那就是设备使用感受,或者说用户体验度。
用户体验度的提升是靠飙硬件实现的么?我们面前的移动显示芯片的性能都已经暴涨了656.25倍了,我们真切的用户体验度又提升了多少?
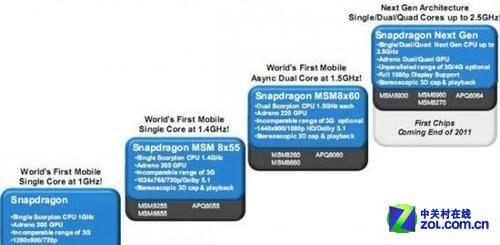
高通勾勒的Adreno发展路线图
整体而言,移动领域芯片性能的提升虽然水分巨大,但从纯理论角度来讲,这些提升并不是不存在的。无论SGX还是Tegra,它们的理论运算性能确实都在以不正常的幅度暴涨着。那究竟是谁把这些性能提升变成了没有任何意义,无法给我们带来有效用户体验度提升的"水分"呢?
逻辑芯片的性能决定要素多种多样,但无论何种芯片都要服从"给多少电就干多少活,给多少有用的晶体管就干多少活"这样一个最基本的定律。也许逻辑结构的变化在过去这些年里花样翻新,但最基本的性能限制要素--运算器的结构,在十数年间都没有过任何颠覆性的本质改变。运算器结构不变,其所能够达到的绝对性能上限和功耗上线就由频率和工艺限定死了,而设计者所做的事情,无非是通过对运算器之外的其他逻辑结构的重设、增减以及重新搭配,来追求更高的运算器动作有效度,并以此来逼近运算器所能够达到的性能。
逻辑结构的设计过程伴随着对必要结构的追加以及对非必要结构的删减和优化,补足过程通常意味着增加功耗,如果能够提供充足的必要结构如总线带宽、发射端以及仲裁资源等等,或者干脆的增加运算器的总量,单位时间内运算器能够输出的运算过程就会进一步提升,但对应的功耗也会因为有效动作总量的增多而增加。优化过程可以进一步平衡效率和能耗的关系,比如说提升缓冲资源的复用效率并以尽可能少的资源来满足更多运算器的缓冲需求,架构的整体能耗比就会提升,这类操作不会直接的提升。无论何种通用运算平台,都遵循这一最基本的原则。

为"更高效率的使用晶体管"所累的HD7900
以逻辑结构的运算效率而言,后者显然是更加有效同时值得提倡的方法,它属于"更加有效率的使用晶体管"而不是"堆砌晶体管"的范畴,不仅可以帮助整个架构提高真实的性能表现,还能以更少的晶体管来实现更多的性能,让架构的功耗表现因低效晶体管的减少而变得更低。但是与前者相比,它有一个看似无关紧要但却决定命运的弱点--无法给芯片带来非常直接的,可供宣传使用的参数:理论性能提升。
不能拿来宣传?没有直观可见的参数提升?这怎么行呢?
CEO:"嗯,很好很好,你们这个优化……寄存……器?抱歉我没念错吧?OK。你们递交的这个优化结构的一揽子改进确实非常棒,我个人以及大部分董事会成员都十分欣赏这种设计(好吧,虽然我们并不明白它是什么……),但是很遗憾,你这个方案没有多少数据层面的直观提升,我们没办法在这个方案的产品上标出2倍、3倍这样具有‘直接攻击力’的数字,很明显它不能帮助我们吸引眼球并从竞争对手的方案中脱颖而出啊。所以很抱歉,请拿出更加直观的方案吧。"
研发主管:"哦,那就让下面的团队继续回去堆ALU/核心吧,请董事会给我们订立一个明确的目标,稍后我们就会递交新的方案,感谢董事会。"
这年头,有概念可以炒作最重要了,炒作热乎了东西卖出去了钱卷回来了就行了,有效效率、实际性能或者半导体业界前途之类的东西谁会去管啊。所以让我们甘之如饴的接受堆砌和浮华,一起高呼"Flops万岁"吧。
伪云中的移动计算
每每提及智能移动平台,我们都会同时想到一个美好的概念--云计算。是的,将运算节
移动GPU NVIDIA Imagination 高通 ARM 相关文章:
- Adreno 400首曝光!(10-05)
- 移动GPU大战白热化:Vivante 32核心虎视眈眈(10-11)
- 高通/ARM/IMG厮杀手机GPU,英特尔/英伟达前来搅局(07-01)
- 开普勒架构 NVIDIA发布GeForce 700M移动GPU(03-02)
- 显卡市场份额之争 AMD逐渐让位NVIDIA(08-04)
- GE Fanuc智能平台引用NVIDIA’s CUDA技术(09-16)