请教,关于时钟分频与路选
时间:10-02
整理:3721RD
点击:
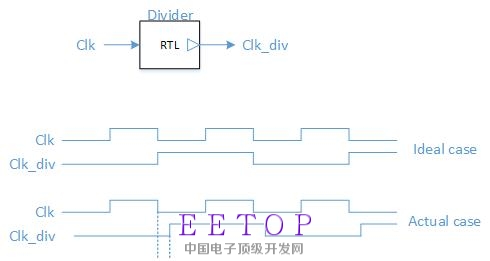
第一个问题是有关分频时钟的实现。
在上图中,时钟Clk_div是由源时钟Clk经过2分频得到的。分频器是通过RTL写的。根据之前一些帖子里的建议,在RTL里实例化了一个BUF来驱动Clk_div。在DC里做综合的时候,通过create_clock设置Clk,通过create_generated_clock设置Clk_div。根据create_generated_clock的描述,DC将使用Clk的沿的位置来计算Clk_div的沿的位置。我理解的是,在DC中,两个时钟的波形是如理想情况(ideal case)所示。可是,在对分频器进行综合后,实际上Clk和Clk_div的沿是不能完全严格重合的,因为分频器内部电路会有延迟。所以,实际情况应该是Actual case所示。那么,问题是:分频器引入的延迟在DC综合时会被考虑吗?如果Clk时钟域和Clk_div时钟域有数据交互,且跨越这2个时钟域的组合路径不被当做false_path,那么DC会考虑分频器引入的延迟对Clk_div的影响吗?如果DC考虑分频器本身的延迟,那么DC内部的Clk_div的波形究竟是Ideal case还是Actual case?
第二个问题:对于一个简单的同步设计,当完成综合后,虽然时钟树还没有插,我们还是可以把生成的门级网表导入到一个SPICE仿真器中去仿真,只需要在时钟端设置一个理想脉冲电压源作为时钟信号就行。因为理想脉冲电压源具有无穷大的驱动能力,因此可以驱动多个连接到它的DFF。可是,对于具有内部分频时钟的设计来说,它的分频时钟Clk_div是内部的,整个设计并没有针对Clk_div的port。那么综合后的结果是分频器的那个BUF直接驱动大量的Clk_div域中的DFF?如果把这样一个设计的网表导入到SPICE中,会因为分频器中的BUF驱动不了那么多的负载,导致Clk_div信号很差。于是,就可能出现DC中分析没问题,但SPICE仿真不通过的情况。不知道是不是这样?
第三个问题:在DC综合中,通过create_generated_clock设置的Clk_div,它的clock transition是怎么样的?

第四个问题是关于时钟路选的。如上面的图中显示的,两个时钟Clk1和Clk2通过一个MUX产生Clk_sel。这个MUX是使用RTL设计的。那么在DC综合的时候,是把Clk_sel设置成generated clock并且把Clk1和Clk2中比较快的那个作为source吗?DC综合时,MUX的延迟会对Clk_sel时钟域中的时序分析产生影响吗?
我觉得综合时无需考虑分频引起的delay。
clk和clk_div2有交互,如果逻辑是异步或是多时钟周期,需要设置false path或multicycle
clk_div2的transition需要设置,和普通clk一样用set_clock_transition
时钟mux的处理,最好使能多时钟分析。就是mux输出端创建两个generated clock
关于clock的驱动能力需要设max cap, max transition, max fanout等,综合时认为是ideal就行,由pr工具去做
如果clk与clk_div2有单周期的交互,后端pr做时钟树会平衡clk与clk_div2
谢谢!