瑞芯微RK3066真那么牛么,跑1.6G!
难道像N家那样是LPG工艺,cpu core 用的40G? 还是瑞芯微瞎吹的?
***********************************************************
新上市的RK3066,40nm的A9双核1.6GHZ,mali400四核,1G内存,10寸IPS屏幕,比较垃圾的摄像头,跑分都很牛(当然跑分虽然和性能正相关,但很多时候相关性也就那么回事),视频播放很无敌(国产芯片特色),1200左右的价格,拿来做电子书,看视频还是很爽的。 淘宝上酷比魔方那个双核豌豆能卖出去1000台/周,销量排第五,上升量排第二,原道那个也能卖500多台/周。 版上有人尝过鲜么?
**************************************************************
终于有人说实话了。
严谨的公司一般都把自己worst corner下的性能当做产品的参数公布。
很多公司公布的性能都是tt条件或者偏更好的条件用于宣传...
这有什么好吹的?后端做的好?
还是别的什么水平更高?
做一个这样的芯片,比比利润排多少还有点意义
不好意思intel有时就这么认真的傻。
他宣称的2.3G就是降压10%,升温到125c还能跑2.3G的。
显然1.6G是虚伪的。
只在跑分的时候能到这个频率,正常时候是1.4G顶天。
而且跑分的时候,GPU都给超到400MHz了,而默认参数GPU只有266。国产厂商真是无下
限。
参见:
http://tieba.baidu.com/p/1707223213?
pid=21584321013&cid=21584558093#21584558093
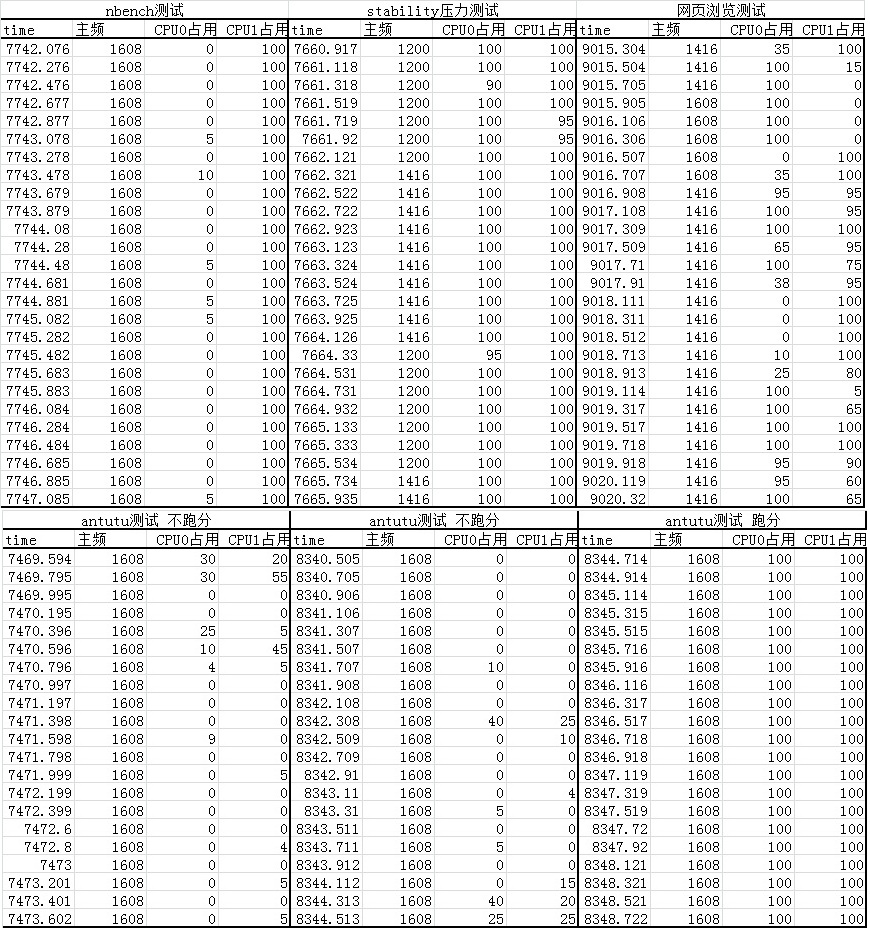
RK30的话,默认的governor(interactive)下,RK30双核满载最高只能到1.4GHz,长
时间满载则偶尔会到1.2GHz。
1.6GHz只在单核满载的情况下可以达到。
不过安兔兔跑分下可以到双核1.6GHz满载,但是不跑分也是1.6GHz锁定,不降频。说明
对安兔兔测试特别照顾了。
其他SOC还没测试
芯片商还是挺聪明的啊。。。还能这样玩
ft,我的电脑现在还有这个错误。。。开双线程分别计算同一段程序,两者的结果愣是
不一样,相同的源码,放到别人的机器上就没有问题。
崩溃鸟,一定有哪儿有问题但是肯定不是cpu的问题,嘿嘿。
re
每次怀疑工具有问题时的结局都是自己有问题.
程序非常简单,开两个线程,调用同一个函数,计算1到1000000开方的和,但是两个线程就是结果不一样。 一个结果是21081849486.439266, 另一个整数部分一样,小数部分是。439312. 这样的计算结果很难用程序出错来形容,只能说是浮点数的累加和有个小误差,但是误差来自于哪里我也是百撕不得骑姐呀。以前在其他版面上发过,但是也没人搞清楚为什么。源码如下
:
#include <stdio.h>
#include <stdlib.h>
#include <fcntl.h>
#include <pthread.h>
#include <math.h>
static pthread_mutex_t client_mutex = PTHREAD_MUTEX_INITIALIZER;
static pthread_t client_thread;
#define CLIENT_LOCK() pthread_mutex_lock(&client_mutex);
#define CLIENT_UNLOCK() pthread_mutex_unlock(&client_mutex);
void *client_thread_main(void *arg);
void calc(int key)
{
struct timeval time1,time2;
int i;
double res;
int ret;
res=0;
printf("thread%d...\n",key);
ret=gettimeofday(&time1,NULL);
for(i=0;i<10000000;i++)
res+=sqrt(i);
ret=gettimeofday(&time2,NULL);
printf("thread%d: time spend:[%d]s [%d]ms %f\n", key, time2.tv_sec - tim
e1.tv_sec, (time2.tv_usec - time1.tv_usec)/1000, res);
}
int client_init(void)
{
if (pthread_create(&client_thread, NULL, client_thread_main, NULL))
{
perror("client_recv: pthread_create");
return (-1);
}
return (0);
}
void *client_thread_main(void *arg)
{
for(;;)
{
CLIENT_LOCK();
calc(1);
CLIENT_UNLOCK();
//usleep(100);
}
}
int main(int argc,char *argv[])
{
pthread_mutex_init(&client_mutex, NULL);
client_init();
for(;;)
{
usleep(1000);
CLIENT_LOCK();
calc(0);
CLIENT_UNLOCK();
}
return 0;
}