请教Nvidia第一题
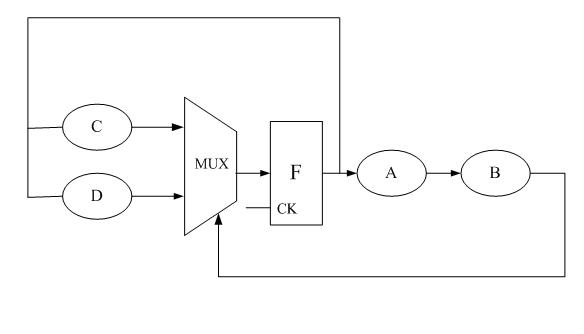
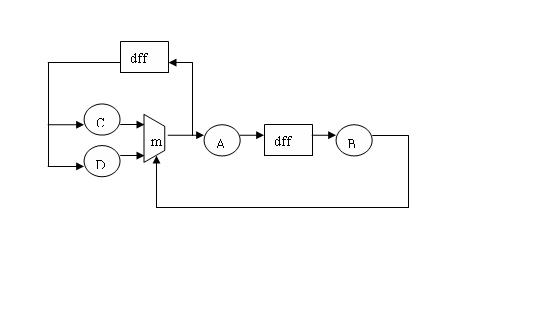
Clk=1ns,A=0.3ns,B=0.6ns,C=0.3ns,D=0.2ns,MUX=0.2ns,忽略F的clk-q延时, A->B->MUX是关键路径,0.3+0.6+0.2>1,请修正violation,可复制logic,面积不考虑。
这题考的是不是retiming啊,但怎么好像不行啊?
这里把答案说了,可惜以后没法再出这道题面试人了-_-!
具体的自己慢慢想吧
提醒一下说可以A和B之间加一级流水的同学
F->A->B->MUX->F是个环...
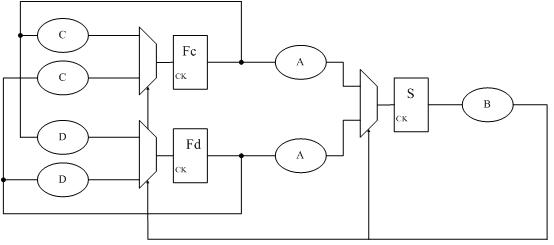
太专业了 :〉
我用点土办法,就是pipeline
我觉得大家插入寄存器这种方法不妥,因为插入寄存器,已经改变设计了,使得一拍出现结果了,变成两拍了。我试着给出一个不作pipeline的方法,它完全和原图等效。
1,第一步,寄存器前移过MUX;
2,第二步,MUX向后移过逻辑A和B。
3,第三步,寄存器再前移过MUX。
那么现在的关键路径变成MUX+MUX+C MUX+MUX+D A+B, 没有超过1 ns的路径了。

我也觉得有很多种方法,下面也是不做pipeline的,似乎也可以
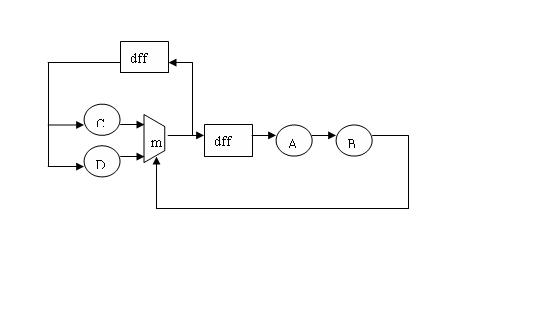
第一,复制dff,
具体操作:将dff移在A之前,原先dff的反馈分支上复制此dff。
第二,将其中一个dff移到A后面。
不会发附件,抱歉1.JPG,2.JPG
牛人多年不见
其实跟预测概念相似
但不是预测
预测是猜一个往后算
算错了再取消
这个相当于碰到分支就两条路都走
TRIPS就是这么做的
看看这个思路对不对
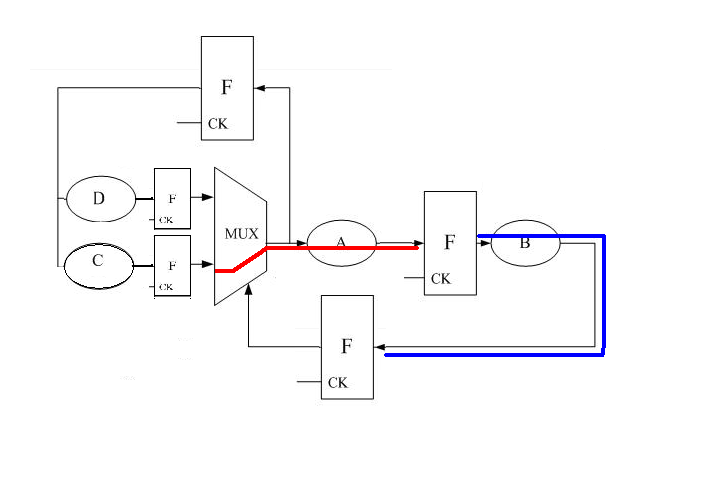
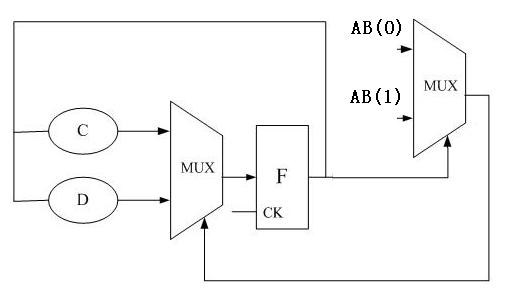
原来电路只有一个状态,现在证明这个状态为寄存器更新的时候,时序不满足,需要推挤一下寄存器,那么状态就分裂了(图111,电路比较简单,寄存器移动的方法也有限),然后分析图111,上面一个环路不是关键路径,重复。下面一个回路关键路径优化就比较明显了,B到达时间比较晚,所以尽量先把A算完再按照B选择。得到222.jpg
不过这样优化的效果怎么样呢
一般RTL中的寄存器都是有明确物理意义的,严格一点的话为了便于优化,模块的输出都应该是寄存器输出。这个模块如果作为一个子模块的话,这样优化或者按照Xiaoyao大侠的优化方法,原来的状态都不见了。如果保持原有输出的话需要变成组合逻辑输出,即222.jpg中的上面一个mux的输出(延迟C+MUX)。这样实际是向后面一个路径“借”了时间。个人认为还不如pipeline处理。
一点浅见,没在实际中用过这么高级的优化方法,不知道对比对wj626 (hwj626) 的大作中提到: 】
:
: Clk=1ns,A=0.3ns,B=0.6ns,C=0.3ns,D=0.2ns,MUX=0.2ns,忽略F的clk-q延时, A->B->MUX是关键路径,0.3+0.6+0.2>1,请修正violation,可复制logic,面积不考虑。
: 这题考的是不是retiming啊,但怎么好像不行啊?


最后一步的修改好像有问题
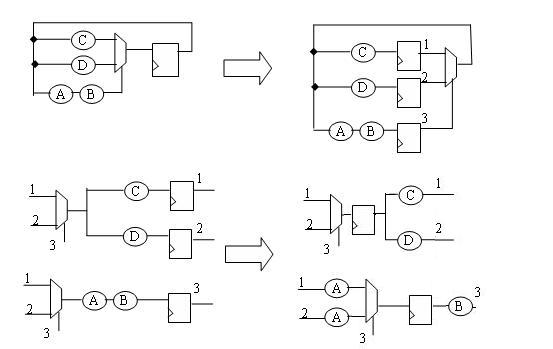
但是我觉得它破坏了输出。我们假设第一张图的输出为寄存器的Q端口。那如果它的FF reset到0的话,输出为0。等效电路在reset 到0的时候,输出也应该等于0。但是在这个精简的等效电路中,输出不等于0,而是
0---C---
0---D---MUX--
|
|
0--B-------
所以严格来说,两者并不是等效的。
但在我的retiming过程中,只移动MUX,mux可以保证严格等效不走样。如果移动A,B,C,D这些实体逻辑穿越寄存器的话,会破坏下一级的输出。
我的意思是说: ---C---FF---并不能直接转为--FF--C---, 这两者的输出不等效。你觉得呢。
2年前NV的笔试也有类似的题目,思路应该是提前计算吧。
PS:有没说寄存器位宽多少?
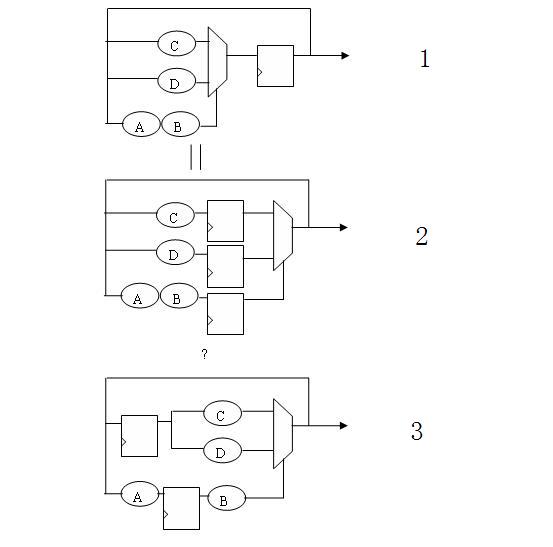
我之所以觉得这个精简的有问题,是因为在初始化为0后,几个等效电路并不相等。这不符合retiming的原则。
如下图所示,图1和图2是只移动mux,可以确认它们是恒等的,从输出看,也是相同的。但是,如果作到图3的变换,那么初始化后,输出的结果就有各种可能了。这个,值得我们在做retiming的时候注意。
虽然,都是调整位置,从图1到图2,可以做到从初始态到运行态都相等;但是从图2到图3,在运行态是相等的,但是在初始态,两者是不同结果的。
这样做可以么?
不是这个专业的,按照数字电路的基础知识我觉得这样似乎可以,大家看看有什么不对指出下,让我多学点,呵呵
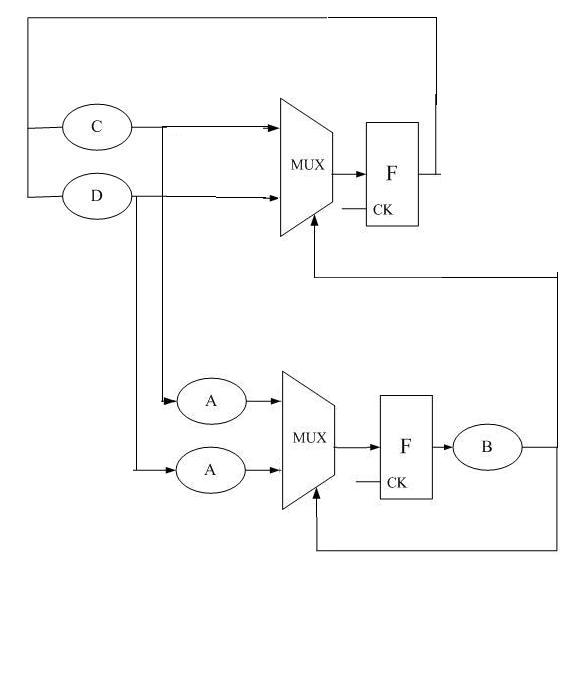
本来这个题可能答案本来就不唯一,其实也不用分个对错
但如果一定要说谁更好,我只说一点,其他同学的方案还没有把路径化到极限最短,而只是在题里面给的较松的条件下满足了timing,不能容忍更紧的条件,而我提出的方案,却能容忍A B C D都达到0.8ns这样的严格条件