8b/10b编码与GTX的恩怨情仇
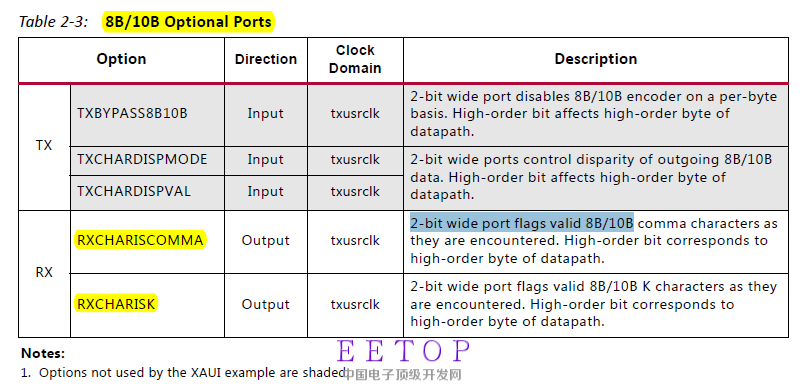
吉比特收发器,关于8b/10b编码方面我有一些疑问。在对IP核进行例化时,我把外部数据设置成32位,内部数据设置成40位,很明显勾上8b/10b的选项。8b/10b编码的目的是使0和1的数目相对均衡,例化完成后IP核会有相应的状态标志位,如上图黄色部分标示,重点观察黄色部分的两个标志。
我的问题就是不太懂这两个状态标志有什么作用,我看过GTX接收控制程序,这两个状态标志位起到了很重要的控制作用。
GTX的测试程序,就是自发自收,相信大家都理解。是发送32位的数据给IP 核,发送数据的时候刚开始发送070809bc,又是575859bc,又是5A5b5cfb,又是ffffffff等,然后再发送正常的数据,就是一个递增的数据,这看起来很酷,并行数据进入IP核,串行数据由txp,txn输出,txp,txn接到IP核的rxp,rxn,又进入了IP核,然后并行输出070809bc这几个奇怪的数据,然后就是很酷的递增数据。
好,下面说说我的理解与疑问。
1.在发送递增数据之前,有一些我称之为‘奇怪数据’先发送,好,我可以理解成他们是特殊的包头,就是说接收端收到这些奇怪的数据时就考虑接收真正的数据,就是说,接收到的数据是ffffffff时,接收控制程序才开始把往后接收到的数据也就是真正的数据写进FIFO或者ram,这看起来是一个好方法。 但是肯定是有问题的,这些奇怪的数据,我猜想有可能是用来找串行数据的边界的,因为他们实在是奇怪,不寻常,我特别期望有大神在这里给指点一下,我这里不是很清楚。
2.照我的理解,应该是用不到我一开始提到的8b/10b 的控制标志位的,但是测试程序确实用到了,这就使我心存疑虑,看手册我无法理解这两个控制标志位到底是什么意思。
3,接收的艺术,现在我们单纯考虑用IP核接收高速的串行数据,能把串行数据的边界找出来,变成正确的并行接收数据。
我觉得不可能是无脑的就把出来的并行数据(高速串行数据经IP核变成并行数据)当成正确的数据来处理,接收端肯定要再做一下处理吧,确定是正确的数据然后再处理;因此怎么确定呢?会不会就是那两个奇怪的8b/10b的状态标志位可以提示数据是对齐的,但是我的内心高速我,没有这么简单,8b/10b编码没有这个对齐功能啊,它的相关的状态标志位又能做什么?数据对齐,好像用到什么k码,有大神能给高屋建瓴的讲一下吗?
4.还有最后一个疑问,相信大家看到黄色的两个状态标志位是2 bit wide port,但是在rtl中的这两个输出端口(在IP核上)却是4位宽的,有图为证,在下面,RTL中的端口名在pg168文档中是搜不到的,但是意思应该不差。

欢迎大家热烈讨论,共同把吉比特收发器理解好,各路大神也停下繁忙的脚步,帮我们看一看这些问题,当是放松。
路过帮顶
论坛好基友啊!
四个字节,每位代表一个字节。
1.你可以认为是training用的data,一般的高速串行协议serdes都需要训练之后才可以正常使用
当然他本身提供的testbench其实是很不严谨的
2.这两标志位就是用来表征收到的是不是comma,是不是k symbol,自己译码器是也是可以的
3.接受其实有两个过程,一个是symbol lock,就是把数据切分成10bit,10bit的并行流,不同的协议不一样,很简单的,pcie的话就是拿comma来切
串行端从一堆数据流中识别出comma,然后就知道了10比特的边界在哪里,gtx里面叫clock correction,然后进行8b/10b解码,如果有多条lane,还要进行deskew操作,gtx里面叫channel bonding.
具体你可以看看你最终实例化模块的参数是怎么定义的(GTXE2_CHANNEL实例化时候的参数),你真要深入学习,就参照文档去看看每个参数是什么意思:
GTXE2_CHANNEL #(
.ALIGN_COMMA_DOUBLE("FALSE"),
.ALIGN_COMMA_ENABLE(10'b1111111111),
.ALIGN_COMMA_WORD(1),
.ALIGN_MCOMMA_DET("TRUE"),
.ALIGN_MCOMMA_VALUE(10'b1010000011),
.ALIGN_PCOMMA_DET("TRUE"),
.ALIGN_PCOMMA_VALUE(10'b0101111100),
.CBCC_DATA_SOURCE_SEL("ENCODED"),
.CHAN_BOND_KEEP_ALIGN("FALSE"),
.CHAN_BOND_MAX_SKEW(1),
.CHAN_BOND_SEQ_1_1(10'b0000000000),
.CHAN_BOND_SEQ_1_2(10'b0000000000),
.CHAN_BOND_SEQ_1_3(10'b0000000000),
.CHAN_BOND_SEQ_1_4(10'b0000000000),
.CHAN_BOND_SEQ_1_ENABLE(4'b1111),
.CHAN_BOND_SEQ_2_1(10'b0000000000),
.CHAN_BOND_SEQ_2_2(10'b0000000000),
.CHAN_BOND_SEQ_2_3(10'b0000000000),
.CHAN_BOND_SEQ_2_4(10'b0000000000),
.CHAN_BOND_SEQ_2_ENABLE(4'b1111),
.CHAN_BOND_SEQ_2_USE("FALSE"),
4.虽然位宽定义了4比特,但是你看看,估计就2比特是有用的,而且那个wrapper你可以自己点进去看看,包了一大堆东西
我以前搞过sata的wrapper,他有些连接还是错的,不要过分迷信那个wrapper,最重要的是最终实例化那个模块的参数值,wrapper仅仅是用来参考的
发的帖子居然被审核了,干
lz可以去看看文档里面的channel bonding和clock correction
谢谢您的回答,非常有用。
非常感谢您的热心回答,本来昨天就准备回复,但是思想一度很混乱。
在8b/10b编码中把K28.1,K28.5,K28.7作为K码的控制字符,称为COMMA,在任意数据组合中,comma只能作为控制字符出现,而在数据的负荷部分不会出现。因此可以用comma指示帧的开始和结束标志位,或始终修正和数据流对齐的控制字符。
当标志位是4位的话,应该是一位对应一个字节,因为我设置的外部数据是32位,刚开始发送的几个奇怪的32位数据最后一个字节确实是K码,当标志位是0001时,表示接收到了奇怪的数据,应该是作为帧头使用,根据发送端发送数据的机制,接收端再加一些控制,就可以接收到正确的数据,因此接收端要与发送端有配合,要根据发送端发送数据的方式来编写具体的独特的控制代码。
或始终修正和数据流对齐的控制字符。这句话,我不是很清楚。http://www.cnblogs.com/church/archive/2012/07/30/2614718.html
我猜应该是这样理解:属于内部机制,我们无需多考虑,K28.1,K28.5,K28.7是作为逗点使用的,起到校正作用在于这三个码在编码成10位时,会产生连续的5个0,所以,可以用来确定边界,对于我们来说,不必纠结于此,它用作帧头帧尾对我们来说更实用。
以上就是我不成熟的见解,肯定是纰漏百出了,期待您的斧正。
你过谦了,我是做pcie/usb/sata ip的,所以知道的比较多一点,就拿大家常用的pcie来讲讲吧,gen1/gen2用的8b/10b,gen3之后就用128/130了
8b10b的话主要目的就是增加数据的跳变频率以及减少0和1的个数差别(dc balance),这些在那片博文里面都有讲到,我就不具体赘述了
symbol可以分为k symbol和data symbol, k symbol顾名思义就是用来做控制用的,k symbol还有一个特性就是它的10b编码disparity为+和disparity为-刚好是反过来的(kx(+) = ~kx(-))
还是拿pcie来举例,他的TLP(数据包)是这样的格式STP(k symbol ) + data frame + END( k symbol )
发送端按照这个格式发,接收端通过k symbol就能够把data frame给提取出来,具体的就是physical layer会把stp + data frame end 收取下来,进行crc校验之后拿掉stp,end symbol以及crc扔给data link layer. 所以发送和接收端其实对于数据的打包解包必须要一致,这些都是各种协议会有具体的规定,我不知道你具体是什么协议,所以也不好说。
你的第二个疑问“数据流对其的控制字符”,这个就要讲到pcie的multi lane了,也就是gtx的channel bonding,举个例子,比如pcie有两条lane在工作,每一条lane的延时都不一样,接收端就要通过k symbol将数据对齐(align)起来,典型的就是用skp ordered set ( skp symbol + IDL + IDL + IDL ),合计4个k symbol,展开的说就是:
在发送端,lane0和lane1会同时发送skip ordered set
在接收端,由于各条lane的延时不一样,可能lan0先收到skip,lane1后收到skip,这个时候就要将lane0的数据delay一下以达到和lane1数据对齐的目的,实际的做法其实很简单,就是用了一个fifo(deskew fifo,跟正常fifo有点不一样,允许overwrite)。
当然skip还有其他作用了,可以用来消除两边的时钟差距(elastic buffer),对应gtx的clock correction.
还有你有没有想过对于32bit的输出,为什么第一个k symbol总是在最低的字节呢?这个其实在gtx里面也是有一个对齐选项可以控制的。
再次感谢您的热心回答。
关于第一部分,我大致理解了。因为我看的测试程序就是自发自收,就谈不上什么协议了,只是随便定义个包头包尾看一下数据的传输,我后面有个板子,要做fpga和dsp的数据传输,用的是srio,到时可能要再向您请教。
关于第二点,通道绑定,K码用于数据对齐,这种思想我也了解了,直到看到您的第二篇回复我才理解这个思想,数据对齐是对多通道说的,以前我从没有想这个多通道的问题,根本就没有这个概念,根本上就理解错了,直到现在恍然大悟。
关于您给我的考察。
第二点,您说的是多通道通信,然后有个通道间的对齐问题。
但是我这里发送的32位数据,应该是单通道通信,只有一对txp,txn,rxp,rxn,并不是多路。
发送端把32位编成40位,通过串行线txp,txn发送出去,rxp,rxn接收到串行数据,根据打头的K码确定数据边界,接收好数据,假如k码不在最低位而是在倒数第二位,那么接收端接收到的32位数据就很可能是k码+高位的两字节+下一个32位数据的最低字节(非k码)。
信口胡开,不知道这是不是您期望的答案,有错您一定要指教。
现在我怀疑您的考察还是另有所指,还请您千万赐教。
学习学习。
发表一下看法嘛。
不会怎么发表...
那么接收端接收到的32位数据就很可能是k码+高位的两字节+下一个32位数据的最低字节(非k码)。
对的,而且GTX里面有参数可以配置让K码的对齐边界(ALIGN_COMMA_WORD,ALIGN_COMMA_ENABLE)
長見識