时序优化问题请教
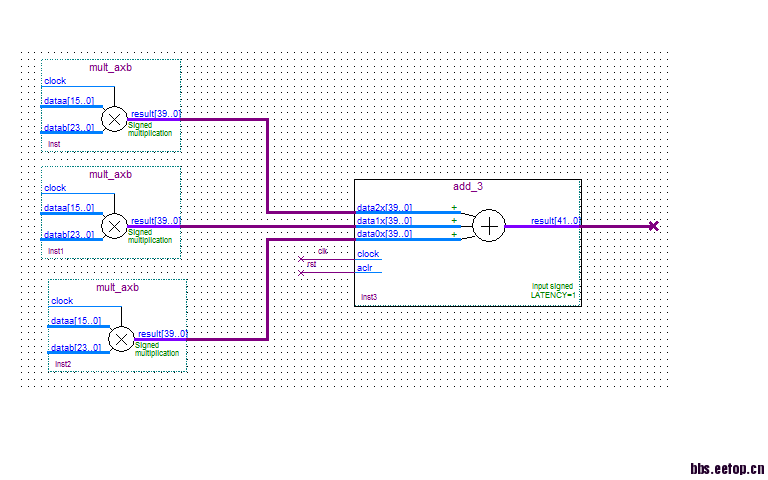
设计模型如上图,实现功能为乘完后相加,其中每个乘法器为16bit*24bit,这样的乘法器共有20个,后级为一个输入个数为20的并行加法器,实现在150M时钟下的流水作业,但是在约束时钟后,时序分析报告里面乘法输出nod到并行加法器输入Nod之间路径的 setup余量为-2.126ns,请问像这种设计该如何约束,才能保证在150M的时钟下正常工作。望高手指教~
说明:用timequest 分析路径时,相应路径的逻辑级数为94级,其中有一级的fanout 有100000多个。
我的想法如下:
1.首先更改下乘法器IP核,在例化时选择两级流水输出,若已经有了则忽略这一步
2.把20输入的加法改为逐级两两相加,最好在每一级的后面用寄存器输出;这样中间可能会增加5级流水,因此你需要调整下相关的时序保证功能没有发生改变。
这样做了之后,相当于把你的大的组合逻辑通过时序流水拆成小的时序逻辑,如果你的片子支持的速率远大于150M,那么修改后时序应该不难通过。
LS说得有理,就采用这种流水线方式。
另外,你使用了20个乘法器资源,这个占用有点多,你现在的输入数据是每个时钟都有数据进来吗?如果不是,可考虑乘法器复用,减少资源消耗。
你说的把后级20路并行加法器拆分的方法,好像只能改变加法器这一级的最大延迟,但是我感觉我的问题在于,乘法运算耗时太长,这样下一个时钟上升沿到来时,即加法器将要锁存数据时,要锁存的乘法结果还没到来(加法器的data_require 早于data_arrive 2点几秒),所以我感觉我的问题应该在于优化前级的乘法器,而不是后级的加法器,只是个人感觉,希望你能答疑~
另外不知道能否讲下,在对乘法器进行例化时,lantcy 这个参数对乘法器的影响是什么?我只知道从结果上看,相当于延迟了整数个时钟周期,好像该参数值越大,占用的资源就越大。
时序分析报告里面乘法输出nod到并行加法器输入Nod之间路径的 setup余量为-2.126ns,
想问下你例化的乘法器的IP核中有流水么,也就是lantcy,你设置了几那么乘法器的输出相对于输入就会延时几拍,一般要求此值至少为2,当然会增加LE的资源,增加的数目为延时数*数据位宽;
如果你例化时有的话,并且芯片本身也支持150M的速率的话,那至少这一级是不会有时序问题的。
为什么不用芯片的DSP资源 ,里面有乘加器啊。
在乘法器例化时,lantcy我设置的为1。设置为1可有时序问题 ?
我用的就是芯片自带硬核(dsp block),使用的芯片是stratix 4 系列530芯片。实现100点复数乘法在150M下的流水作业。
你可以试一下单独跑乘法器,看能最快达到多少,是否芯片本身支持不到呀?
芯片本身到150M是没有问题的,看一下时序不满足的路径,如果是DSP和DSP硬核之间的路径,可以考虑中间打拍,或者增加latency。
按照你说的说法,芯片本身跑150M应该是没有问题的,但是altera的乘法器IP本身的架构随着不同的芯片结构也不同,但是如果真如10L所猜测的话,那么可以尝试增加latency;我在实际使用过程中一般都设置2,暂时还没遇到你的问题,如果你修改后还有时序问题,不妨将warning贴上来,大家一起分析!