基于DSP嵌入式说话人识别系统的设计与实现
0 引 言
说话人身份识别属于生物认证技术的一种,是一项根据语音中反映说话人生理和行为特征的语音参数来自动识别说话人身份的技术。近年来,说话人身份识别以其独特的方便性、经济性和准确性等优势受到瞩目,在信息安全等领域的应用逐渐增大,并成为人们日常生活和工作中重要且普及的安全验证方式。目前,说话人身份识别在理论上和实验室条件下已经达到了比较高的识别精度,并开始走向实际应用阶段。AT&T、欧洲电信联盟、ITT、Keyware、T-NETIX,Motorola和Vi-sa等公司相继开展了相关实用化研究,国内这方面研究主要在中科声学所,中科院自动化所,清华大学等研究所和大学中进行。
基于嵌入式的说话人身份识别系统具有高精度,适时性好,低功耗,低费用,体积小等优势,逐渐成为说话人身份识别面向实际应用的新热点。而随着DSP新技术的发展,DSP芯片无论在处理速度、精度、功耗或者体积等方面都取得了突破性的进展。DSP也越来越多的应用于说话人身份识别。但目前这方面研究主要局限于小数据量、与PC机配套使用上,没有太大的实用价值。在此介绍一种基于TMS320C6713 DSP芯片设计的嵌入式,10个人范围的说话人身份识别系统。该系统可以自举运行,并可灵活的选择训练、识别或者更换训练者、识别者,识别率达98%以上。
1 系统的架构及硬件构成
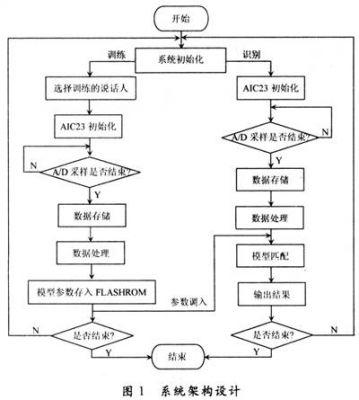
系统总体实现流程如图1所示。系统主要分为训练和识别两部分,系统初始化后由操作者控制训练或识别。训练目的是提取说话人模型参数并将其存储在FLASH ROM中。识别目的是读取待识别者语音信息并将获得的模型参数与训练的模型参数比较,从而获得识别结果。
1.1 系统的主要硬件构成
系统硬件构成如图2所示,主要包含语音采集模块、数据处理模块(DSP)、程序数据存储及自举FLASH模块、数据存储器RAM模块、系统时序逻辑控制CPLD模块、JTAG接口模块。
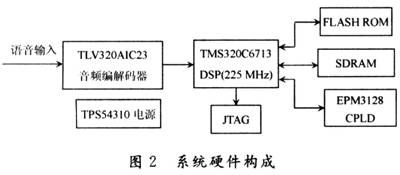
语音采集模块主要由TLV320AIC23音频编解码器来完成,该芯片是TI公司的一款高性能的立体声音频Codec芯片,内置放大器,输入/输出增益可编程设置。模数,数/模转换集成在一块芯片中。采样率8~96 kHz可编程实现。另外还具有低功耗,连接电路简单,性价比高的特点。
语音处理DSP采用TI公司的TMS320C6713芯片,该芯片实现浮点运算,最高时钟频率225 MHz,使用该芯片外部存储器接口可实现对外部存储器(SDRAM)数据传输和程序存储器(FLASH ROM)进行程序读写;依靠JTAG接口电路通过仿真器进行仿真调试,实现与主机数据交换;通过片内外设McBSP完成串行数据的接收和发送,实现对音频处理模块的控制等工作。
FLASH ROM最大可提供512 KB空间,通常为前256 KB可用。SDRAM最大容量为16 MB,为该系统提供较大的数据存储空间。CPLD为存储器的扩展实现逻辑编码。电源为TPS54310芯片,可为系统提供3.3 V和1.26 V两种电压。
1.2 选择说话人
该系统要训练10个人的语音,每个人的语音存放在FLASH ROM的不同位置。在训练的开始阶段,系统需确定当前训练者的身份,以便对训练完成后说话者模型参数存储位置有准确的判断。对当前训练者身份的选择由系统中的4个Switch实现。若把每个Switch的开关两种状态看成是二进制数的0,1,则最终可形成16种组合,代表16个人。该系统选取前10个组合。
1.3 AIC23语音采集
考虑到系统的实用性,语音的输入由mic in接口输入。语音采集若设为双声道,则采集的左右声道数据差别不大,对识别没有太大的帮助,而且采集到的语音会占用太大存储器空间,故采用单声道采样;对于采样精度要求,TLV320AIC23可实现8~96 kHz,16 b,20 b,24 b,32 b,的不同采样,随着采样频率的提高,采样间隔将相应的缩短,要求更大的内存空间和更长的处理时间,实验表明,采样率由16 kHz下降到8 kHz,所造成的识别率的微乎其微,但是可以节省50%的动态存储空间,并可减少大量的运算。对于采样位数,16 b精度已能满足该系统要求,故采样精度设为8 kHz,16 b采样。
1.4 数据的存储
由TLV320AIC23获得的语音信号的数据,只有赋值给相应的数组,才能在接下来的算法中有所应用。为此在SDRAM中定义一片数组存储区域。对于数组大小及类型的选择基于以下两点:
(1)数组大小选择。该系统算法中包含训练和识别两个内容。语音信号的训练需要大量的数据才能准确的提取语音的特征参量。该系统采用8 kHz采样率的10 s的语音信号,所需的数组空间大小为80 000个数据单位;语音信号的识别要求快速性,该系统采用时间较短的8 kHz 3 s语音信号,所需数组空间大小为30 000个数据单位,为了减少数据空间,系统设定为与训练数组共用前30 000个数据单位的空间。
(2)数组类型为浮点型,由于设定的采样格式是16 b采样,而采样后数据类型是Uint32,语音数据位于低16位,所以赋值过程中取低16位数据赋值给数组。
DSP 嵌入式说话人识别系统 身份识别 相关文章:
- 在采用FPGA设计DSP系统中仿真的重要性 (06-21)
- 基于 DSP Builder的FIR滤波器的设计与实现(06-21)
- 达芬奇数字媒体片上系统的架构和Linux启动过程(06-02)
- FPGA的DSP性能揭秘(06-16)
- 用CPLD实现DSP与PLX9054之间的连接(07-23)
- DSP+FPGA结构在雷达模拟系统中的应用(01-02)