基于DSP嵌入式说话人识别系统的设计与实现
1.5 模型参数存入与参数调出
将模型参数存入FLASH ROM的目的是保存训练所得的参数,以供识别时调用。训练可能用于多次识别,或者训练和识别可能处于不同的时间地点,所以,保存参数的存储器选定为具有掉电时数据不丢失特点的FLASH ROM。每个说话者语音参数代表一个说话者身份,所以每个说话者模型参数应存储在FLASHROM中一个确定的位置。为此,该系统在FLASHROM中分配了10块的区域,每个说话者模型参数占有一块特定的区域。
在FLASH ROM中存人数据格式为32 b无符号整数。而训练得到的是浮点型的数据。这就要求在数据存入之前将浮点数转换为32 b无符号类型的整数,假设要转换的数据为float x[M][N]则转换方法如下:
(1)x[M][N]归一化;
(2)对x[M][N]乘以一常数K得到有符号整型的数组y[M][N],即:
y[M][N]=x[M][N]×K (1)
(3)屏蔽第32位符号位,得到32 b无符号类型的整数数组。方法如下:
z[i][j]=y[i][j]&0x7FFFFFFF (2)
(4)将z[i][j]存入FLASH ROM。
通过统计实验数据发现归一化后数据的范围为10-5~1,故K选择为108,既可以实现较大精度的转化,又不会影响第31位的数值。转换得到的有符号整型数组y[M][N]范围为-108~108,在存储器中正数为原码表示,负数为补码表示,通过计算发现,该范围的正数第31位为0,负数第31位为1,所以,上述第(3)步,将有符号数转换为无符号数后,数值的正负改为使用第31位标识。在识别阶段,要将说话者的GMM参数依次从FLASH ROM中读出,逐个与待识别者语音的MFCC参数比较,求最大似然值。参数调出过程与以上存入过程相反。
1.6 说话人身份识别的结果显示
说话人的身份显示通过LED的组合显示确定。在DSK上有4只LED灯,将每个LED灯看成是一位二进制数。则4个LED灯最大可表示16个人的身份。该系统取前10个组合来表示所识别的说话人的身份。
1.7 自举的实现
以上程序都是通过PC机与DSP组合实现,要想使系统在DSP上单独完成,还必须实现自举。该系统采用ROM方式自举。在自举实现过程中,程序的烧写可以通过CCS自带的FLASHBorn工具实现。在烧写过程中应正确的分配FLAH ROM的空间。FLASHROM空间总体分为程序存储区和数据存储区,经计算,程序代码段大小为0x162C0,故在FLASH ROM中划分127 KB的空间供程序代码使用,空间中未使用的部分供程序扩展使用。数据存储区划分的大小为64 KB的空间,每个说话者模型参数占用空间为4.2 KB左右,最多可存放15个说话人GMM模型参数。该系统训练者数目为10个,占用空间为42 KB左右。剩余的空间可用来扩展训练人数,也可用于后期系统的改进。如可以利用语音提示来显示说话人身份,而提示语音的数据可以存放于此区域。具体的存储的安排如表1所示。

2 系统的算法与软件设计
说话人识别系统的实现方案如图3所示。
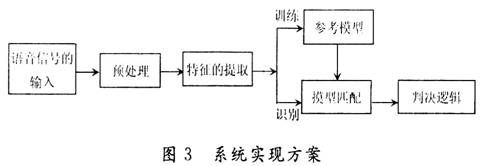
输入的模拟语音先通过预处理,包括预滤波、采样、量化、加窗、端点检测、预加重等。语音经过预处理后进行特征提取。在训练阶段,对提取的特征进行相应的处理后就可以获得参考模型。识别阶段,语音通过同样的通道获得特征参数,生成测试摸型,之后将测试摸型与参考摸型进行匹配,从而根据判决逻辑获得判决结果。
2.1 语音信号的端点检测
语音信号的端点检测目的是去除语音信号中的噪声段。端点检测从很大程度上影响到识别率。常用方法有短时能量法,短时过零率法和双门限法等。本系统选用双门限法,实验表明,效果优于前两种方法。在双门限方法端点检测中,阈值的选择尤为关键,该系统的语音采样频率设为8 kHz,语音分帧为每帧80个点。经过多次实验,这里短时能量低阈值通过式(3)的动态方式得到,高阈值设为低阈值的5倍。而过零率的阈值选取应充分考虑到噪声的影响,通过大量实验发现系统中噪声的过零率一般不超过5,所以对过零率的阈值选取为25,取得了很好的效果,准确率达到95%以上。
ITU=0.03(amp_max-amp_min)+amp_min (3)
在端点检测过程中有时会遇到突发性的干扰噪声,这种噪声持续时间很短,一般小于5 ms。为了消除这种干扰,这里用检测后的起止长度判断它是不是语音。如果所检测到的语音长度足够的短,则可以把它当成是噪声。
2.2 特征参数的提取
语音信号的特征提取是说话人身份识别的难点。能否用相对简单的方法提取出一种最能体现说话人个性信息的特征将成为以后研究的方向。该系统中用的是能体现人耳听觉特性的Mel倒谱系数(MFCC)。
MFCC着眼于人耳的听觉机理,依据听觉的结果来分析语音的频谱,获得了很好的识别率和很好的噪声鲁棒性,它利用
DSP 嵌入式说话人识别系统 身份识别 相关文章:
- 在采用FPGA设计DSP系统中仿真的重要性 (06-21)
- 基于 DSP Builder的FIR滤波器的设计与实现(06-21)
- 达芬奇数字媒体片上系统的架构和Linux启动过程(06-02)
- FPGA的DSP性能揭秘(06-16)
- 用CPLD实现DSP与PLX9054之间的连接(07-23)
- DSP+FPGA结构在雷达模拟系统中的应用(01-02)