基于TalusVortexFX的32/28纳米节点设计方案
以克服阿姆达尔定律所定义的局限性。如图9所示,采用全新DistributedSmartSync(分布式智能同步)技术的TalusVortexFX提供了与贯穿物理实现流程所有步骤(时钟树综合除外,这种方法对它起不了什么作用)的智能同步技术相结合的独特分布式管理。微捷码将这款最新解决方案称为TalusVortexFX,它以DistributedSmartSync技术增强了Talus1.2。
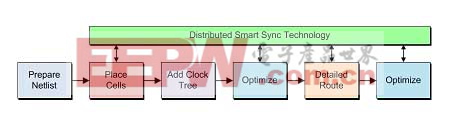
技术增强的TalusVortexFX流程的高级视图
这种技术背后的概念是:对一个更大型的设计或模块进行智能分割、将设计分区分散到整个网络的服务器上执行设计实现、最后在主要流程阶段自动对这些设计实施重新同步。本质上,这让设计师能够处理更大型设计,同时仍可获得与他们之前在规模更小得多的电路模块上所实现的相同的吞吐量(即每天单元数)。甚至在使用同等数量的内核/线程的时候,这种分布式方案的处理速度也较最佳多线程扁平流程要快上2-3倍。
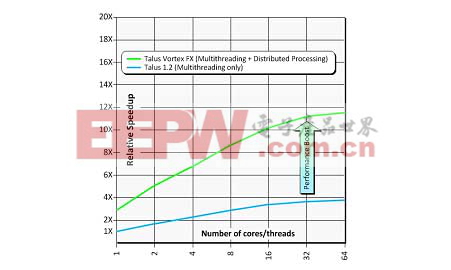
图10.仅多线程vs.多线程+分布式处理
物理实现工程师的生产率一般是根据每天单元数来进行衡量。使用最好的常规流程,可能获得的最大生产率一般约为每天100万个单元。相较之下,TalusVortexFX的分布式处理技术可将这一数字提高到每天200-500万个单元,这种技术贯穿整个流程(对于只布局的门极电路而言,生产率可获得更高的提升,这是一些用户会关注的另一指标)。
还值得关注的是:TalusVortexFX为物理实现团队提供了在设计周期早期执行快速的假设分析的能力,实现了最佳的面积、速度和功耗间折衷权衡。但还有一点也不容忽视:DistributedSmartSync技术完全增强了现有Talus1.2技术,进而促进了这款产品的快速采用。
至于保留现有硬件资源的投资方面,DistributedSmartSync技术让用户现有的内存为32GB和64GB的设备能够得到充分利用。若未采用这项技术而转向32/28纳米节点设计,那么将要求用户的设备要升级为内存128GB或256GB的设备,碰到大型服务器场的话这可能需耗费几百万美元。
除了通过缩短设计周期、提高工程团队使用扁平方法的能力(在不必添加额外资源的前提下)、提高工程团队的生产率以外,TalusVortexFX的使用通过缩短上市时间(赢利时间)还解决了如何满足日益紧张的开发时间表这一问题。
总结
进行32/28纳米及更小尺寸技术节点设计时会遇到许许多多的问题,包括低功耗设计、串扰效应、工艺变异以及操作模式和角点数量的显著增加。微捷码的TalusVortex1.2物理实现环境完全解决了所有这些问题。
此外,32/28纳米节点设计尺寸及复杂性的不断提高还造成了工程资源(不扩大团队规模而取得更大成果)、硬件资源(无需升级主板、增加内存或购买全新设备,使用现有设备和服务器场来处理更大型设计)和如何满足日益紧张开发时间表等方面相关问题的增加。为了解决这些问题,通过TalusVortexFX创新性的DistributedSmartSync™(分布式智能同步)技术,TalusVortex显著地提高了其容量和性能。
设计 方案 节点 纳米 TalusVortexFX 32 28 基于 相关文章:
- 基于FPGA的DSP设计方法(08-26)
- 电力电子装置控制系统的DSP设计方案(04-08)
- 基于DSP Builder的VGA接口设计(04-10)
- 基于DSP和USB的高速数据采集与处理系统设计(05-01)
- 数字信号处理(DSP)应用系统中的低功耗设计(05-02)
- 基于DSP的嵌入式显微图像处理系统的设计(06-28)