用Xilinx Vivado HLS实现浮点复数QRD矩阵分解
时间:04-27
来源:互联网
点击:
QRD矩阵分解的Vivado HLS设计实现与优化
C模块划分
Vivado HLS生成的RTL代码在默认情况下保留原有c代码的层次结构。在构建c代码层次时,可以采用由上至下、自下而上相结合的模块划分方式。
将单精度浮点基本运算如加、减、乘、除、平方根等写成最底层的子函数,以便添加directives来指导工具优化方向。
float hfmult
(
float in1,
float in2
)
{
#pragma HLS PIPELINE
// 注:将hfmult函数流水化设计,以获得更好的时序性能
#pragma HLS RESOURCE variable=return core=FMul_fulldsp latency=9
// 注:制定hfmult的延迟为9个时钟周期,以便hfmult内部实现有充分的时钟节拍流水,特别是有足够的时钟节拍分配给DSP48内部做流水处理
float out;
out = in1 * in2;
}
类似的设计方法及思路也同样适用于浮点加,减等运算。
提高C转换成FPGA RTL 实现的并行度
由于计算时间、速度的要求,往往需要提高运算的并行度,需要对qrd_engine中in_u及r数组(HLS综合成FPGA的BRAM或分布式RAM)加数组分割directive,这样数据才可以并行进入后面的并行处理单元。
#pragma HLS ARRAY_PARTITION variable=in_u complete dim=2
#pragma HLS ARRAY_PARTITION variable=r complete dim=2
对数组memory地址读写设计优化
C语言中的数组通常会被综合成FPGA的存储memory,这样就会有地址的读写。但为了达到更好的时序性能,可以尽量减少对memory的读写,从而简化所生成RTL代码中的mux。
写法1,定义成,in_u[i/div_UNM][i%div_NUM],对下面的运算,将产生两次memory读写。
calc_coef(lamda_sqrt, in_u[i/div_UNM][i%div_NUM], …);
for(j=0; j<N_DIM; j++)
for(k=0; k<div_NUM; k++)
{
in_u_read = in_u[u_addr][k];
}
写法2,定义成变量in_u_pre, 通过 if(u_addr == (i+1)/div_NUM && k==(i+1)%div_NUM)判断来实现同样的功能,这样只需要一次memory读写,从而获得更好的II性能,当然也提升了时序性能。
calc_coef(lamda_sqrt, in_u_pre, …);
for(j=0; j<N_DIM; j++)
for(k=0; k<div_NUM; k++)
{
in_u_read = in_u[u_addr][k];
if(u_addr == (i+1)/div_NUM && ==(i+1)%div_NUM)
in_u_pre = in_u_read;
}
有时为了使in_u综合出的RAM时序更好,也可以对in_u综合的RAM加resource directive来控制其stage, 比如为3 stage,这样生成的RAM, 在输入,输出都会打一拍register。
#pragma HLS RESOURCE variable=in_u core=RAM3S
浮点运算加法级联与加法树
由于浮点运算的精度与其运算的先后顺序有直接关系,在Vivado HLS中,为了保证生成的RTL代码与C中的精度一样, Viado-HLS一般不会改变代码中中浮点运算的顺序。有时为降低浮点运算的latency,使用并行加法树将比串行级联加法来获得更有效。
浮点串行加法级联,这样写法是有严格先后顺序的,Vivado HLS将其生成串行实现的RTL代码,其latency为35个时钟周期。
void fp_adder_cascade (float *r, float a, float b, float c, float d)
{
#pragma HLS PIPELINE
*r = a + b + c + d;
}
如果用户确定上面的浮点加顺序调整对精度的影响在误差范围内, 那么可以采用并行加法树,这样 Vivado HLS 将其生成并行加法RTL代码实现,其latency为降为23个时钟周期。
void fp_adder_tree (float *r, float a, float b, float c, float d)
{
#pragma HLS PIPELINE
float e, f;
e = a + b;
f = c + d;
*r = e + f;
}
对浮点乘法使用的DSP48的优化
同样我们也可以通过设置充足的latency directive给DSP48,这样有足够的时钟节拍给到DSP48内部打拍register。
如果对上述的单精度浮点乘法hfmult latency设置为3,这样分配到每个DSP48 内部只有2级latency, 那么综合总合出来代码DSP48内部的A_reg 或 P_reg不会打一拍, 这样将会大大降低时序性能。
derive_core fmul_der -base FMul_maxdsp -latency 3 -fixed
set_directive_resource -core fmul_der hfmult out
或者:
为了达到较好的时序性能,对上述的单精度浮点乘法hfmult latency至少设置为4,这样分配到每个DSP48 内部只有3级latency, 那么综合总合出来代码DSP48内部的A_reg 或 P_reg都会各打一拍。
derive_core fmul_der -base FMul_maxdsp -latency 4 -fixed
set_directive_resource -core fmul_der hfmult out
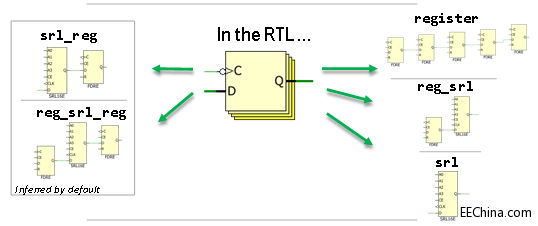
对Shifter Register的优化
利用Vivado HLS 2014.4的Shift Register RTL Attribute,有5种类型SRL来控制不同的shifter register组合:srl, srl_reg, reg_srl, reg_srl_reg。
比如在Vivado HLS生成的RTL代码中加(* srl_style “reg_srl_reg” *),将综合成在SRL之前、之后分别用一个register来实现。如图所示:
Vivado HLS QRD矩阵分解设计结果
本文中QRD矩阵分解的大小是128x128的单精度复数浮点,我们使用Xilinx
Vivado HLS 2014.4版本,将其生成的RTL在Xilinx Virtex-7 FPGA上实现。
延迟(latency)性能
本文所述的设计,在Xilinx Vivado HLS 2014.4中达到的延迟15237个时钟周期。
Interval(吞吐率的倒数)性能
在Xilinx Vivado HLS中,interval是指下一个新的可以输入QRD模块的数据与前一个数据之间所间隔的时钟周期数,也可以理解为吞吐率的倒数。这里Interval的单位是时钟周期。
本文所述的设计,在Xilinx Vivado HLS 2014.4 中达到的Interval是15238个时钟周期。
时序(timing)性能
使用Xilinx Vivado HLS 2014.4在Xilinx Virtex-7器件中实现单个128x128单精度浮点复数QRD分解模块,时钟频率达到了350 MHz (2.85ns)。
处理时间性能
QRD矩阵分解的处理时间就是所用的延迟x时钟周期,所以是:15237 x 2.85 = 43.4 uS。
FPGA资源
将Xilinx Vivado HLS 2014.4生成的RTL代码,在Vivado 2014.4中综合,实现,使用的资源如下表。这个资源使用率只占Xilinx Virtex-7 7V485T的4%,使用Vivado HLS 2014.4高效地实现了QRD矩阵分解。
Slice 4048
LUT 11882
FF 12495
DSP 109
BRAM 0
SRL 314
总结
使用Xilinx Vivado HLS工具,可以让算法工程师、FPGA工程师及软件工程师快速基于FPGA实现典型的数字信号处理算法。本文以浮点复数QRD矩阵分解为例,介绍了如何使用 Vivado HLS 快速、高效地基于FPGA实现,并降低开发者对算法的FPGA实现难度。
Vivado HLS可以帮助设计者大幅提升生产力。 使用 Vivado HLS 开发效率比手写RTL实现快5-10倍,其FPGA资源效率与手写RTL接近,且C/C++仿真验证比传统FPGA RTL要快100倍。。
Xilinx DSP FPGA 仿真 Verilog VHDL C语言 相关文章:
- 基于FPGA的片上系统的无线保密通信终端(02-16)
- 基于Virtex-5 FPGA设计Gbps无线通信基站(05-12)
- 基于ARM的嵌入式系统中从串配置FPGA的实现(06-09)
- 基于PLB总线的H.264整数变换量化软核的设计(03-20)
- 迄今为止最牛的ASIC验证平台(05-22)
- 验证FPGA设计:模拟,仿真,还是碰运气?(08-04)