基于PLB总线的H.264整数变换量化软核的设计
时间:03-20
来源:互联网
点击:
H.264以其高复杂度为代价获得了优异的编码效率, 其中除部分控制流程的复杂模块外,H.264中的很多模块适合用硬件实现。应用中通常使用CPU+FPGA结构,将耗时较多的模块用FPGA实现,CPU仅负责一些低复杂度的算法和编码流程参数的设置。
参考文献[1]、[4]、[5]介绍了整数变换量化的硬件实现,但没有考虑数据在处理过程中的宽度问题,因此会造成FPGA资源的浪费。本文充分考虑了数据在处理过程中的动态范围,使用更少的FPGA资源来实现H.264中的整数变换量化
结合实际应用,文中对该软核在计算速度和硬件资源方面分别做了优化。经过速度优化的软核性能明显优于文献[1]、[4]、[5]中的设计,经过消耗资源优化的软核也完全能够胜任高分辨率的实时编码。
1 整数变换
在完成帧内和帧间预测以后,需要对图像参差数据进行整数变换和量化,使图像数据的能量集中到一小部分系数上,进一步降低码流速率。
1.1 整数变换原理
H.264中对图像参差进行二维DCT变换,表达式为:

其中:
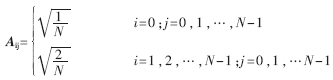
X为输入数据,A为变换矩阵,Y为变换结果。H.264对4×4的图像块进行操作,则相应的4×4 DCT变换矩阵A为:

防止解码后的数据失配,H.264对4×4 DCT中的A进行改造,采用整数DCT技术,取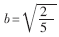 则(1)式可分解为:
则(1)式可分解为:
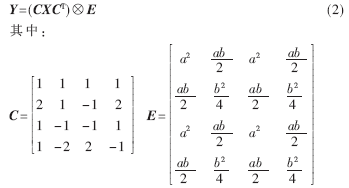
与E的乘法被归纳到量化运算中,这样(CXCT)中只剩下整数的加法、减法和移位运算,因此可以大大降低硬件实现的复杂度,变换结果最多只需要16位的数据。
1.2 整数变换硬件结构
本设计H.264中的4×4整数变换采用蝶形快速算法,如图1所示。首先对4×4块的每一行做一维整数变换,然后再对行变换结果做列的一维整数变换,最终得到4×4的整数变换结果。图1模块需要32个加法器和32个减法器,这样在一个时钟周期内就可以完成一个4×4块的整数变换。
整数变换通常的做法是全部使用16位加法器和减法器,这样可以简化设计。然而在实际应用中,输入的像素点范围是[0,255],如果第一级变换就使用16位,则数据宽度无疑会占用更多的硬件资源。根据分析可知,计算一维行变换以后,数据输出范围为[-765,1020],只需使用11位二进制数表示。计算一维列变换以后,数据输出范围是[-3 060,4080],需要使用13位二进制数表示。因此整数变换模块的数据宽度可以确定为:进行一维行变换时的加法器和减法器使用11位数据宽度,一维列变换的加法器和减法器使用13位数据宽度。
由于数据单向流动的特点,即没有反馈,可以使用流水线提高系统性能。使用流水线时需要注意前后模块处理速率的匹配。如本模块中在行变换与列变换插入缓存构成前后模块,前后模块用同一时钟,并且整个模块的工作频率以最低工作频率的模块来确定。本设计用1级流水线来提高工作频率。如果流水线级数过多会消耗大量FPGA资源,仿真实验证明,此模块使用1级流水线时,只增加极少FPGA资源。
2 量化
为了进一步降低图像传输码率,需要对图像进一步压缩,方法是使用变换编码及量化技术。
2.1 量化原理
H.264中采用标量量化器。标量量化器的原理是:

其中,y为输入样本点编码,Qstep为量化步长,FQ为y的量化值。H.264标准支持52个量化步长。量化的简化操作如下:
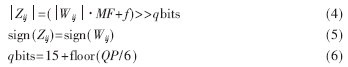
其中,Wij为输入样本点编码,MF是标准中定义的值,QP为量化系数,f为偏移量,对帧内预测图像块f取2qbits/3,对帧间预测图像块f取2qbits/6。
2.2 量化器实现
量化器硬件结构如图2所示,其结果是实现对式(4)和式(5)的组合电路。W是需要量化的数据,MF是根据QP和当前点位置在查找表中得到的值。f和qbits是根据QP查表的输出。
为了硬件资源消耗最少,需要分析数据在计算过程中的动态范围,使用最少的数据宽度来表示传输的数据,从而使用最少的硬件资源来实现组合运算逻辑。W是整数变换结果,根据整数变换部分的分析,其取值范围是[-3 060,4 080],MF最大取13107,乘法器输出动态范围是[-40 107 420,53 476560],至少用27位二进制数表示。本量化器的乘法器使用Vetex-Ⅱ中的18×18硬件乘法器,因此在输入加法器之前需要将数据宽度调整为27bit。加法器输出的27位数据通过移位模块调整为16位数据宽度。
综合考虑工作频率和资源占用率,设计中使用2级流水线来提高性能。
2.3 量化器优化
本量化器一次只能量化一个点,无法满足高质量图像编码的要求。针对高质量图像编码对此量化器进行速度优化,即将n个量化器并联,一个时钟周期计算n个点。n根据实际需要进行选择。考虑到与变换模块的速度匹配,选择16个量化器并联。
3 软核设计及测试
3.1 PLB总线的软核结构
PLB(Processor Local Bus)总线是IBM开发的一种高性能片上总线,主要应用于PowerPC405处理器系统中,它支持32位、64位和128位数据宽度。本设计使用64位总线宽度,最大速据传输速率达800Mb/s。
如图3,PLB的软核设计分为总线接口和H.264整数变换量化模块两部分。PLB总线接口是与硬件体系结构相关的部分,它是整数变换量化模块与PLB总线上其他设备进行交互的桥梁。整数变换量化模块与体系结构无关,它也可以被移植到ARM体系结构中。
参考文献[1]、[4]、[5]介绍了整数变换量化的硬件实现,但没有考虑数据在处理过程中的宽度问题,因此会造成FPGA资源的浪费。本文充分考虑了数据在处理过程中的动态范围,使用更少的FPGA资源来实现H.264中的整数变换量化
结合实际应用,文中对该软核在计算速度和硬件资源方面分别做了优化。经过速度优化的软核性能明显优于文献[1]、[4]、[5]中的设计,经过消耗资源优化的软核也完全能够胜任高分辨率的实时编码。
1 整数变换
在完成帧内和帧间预测以后,需要对图像参差数据进行整数变换和量化,使图像数据的能量集中到一小部分系数上,进一步降低码流速率。
1.1 整数变换原理
H.264中对图像参差进行二维DCT变换,表达式为:
其中:
X为输入数据,A为变换矩阵,Y为变换结果。H.264对4×4的图像块进行操作,则相应的4×4 DCT变换矩阵A为:
防止解码后的数据失配,H.264对4×4 DCT中的A进行改造,采用整数DCT技术,取
则(1)式可分解为:与E的乘法被归纳到量化运算中,这样(CXCT)中只剩下整数的加法、减法和移位运算,因此可以大大降低硬件实现的复杂度,变换结果最多只需要16位的数据。
1.2 整数变换硬件结构
本设计H.264中的4×4整数变换采用蝶形快速算法,如图1所示。首先对4×4块的每一行做一维整数变换,然后再对行变换结果做列的一维整数变换,最终得到4×4的整数变换结果。图1模块需要32个加法器和32个减法器,这样在一个时钟周期内就可以完成一个4×4块的整数变换。
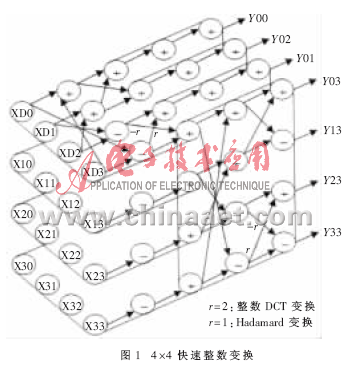
整数变换通常的做法是全部使用16位加法器和减法器,这样可以简化设计。然而在实际应用中,输入的像素点范围是[0,255],如果第一级变换就使用16位,则数据宽度无疑会占用更多的硬件资源。根据分析可知,计算一维行变换以后,数据输出范围为[-765,1020],只需使用11位二进制数表示。计算一维列变换以后,数据输出范围是[-3 060,4080],需要使用13位二进制数表示。因此整数变换模块的数据宽度可以确定为:进行一维行变换时的加法器和减法器使用11位数据宽度,一维列变换的加法器和减法器使用13位数据宽度。
由于数据单向流动的特点,即没有反馈,可以使用流水线提高系统性能。使用流水线时需要注意前后模块处理速率的匹配。如本模块中在行变换与列变换插入缓存构成前后模块,前后模块用同一时钟,并且整个模块的工作频率以最低工作频率的模块来确定。本设计用1级流水线来提高工作频率。如果流水线级数过多会消耗大量FPGA资源,仿真实验证明,此模块使用1级流水线时,只增加极少FPGA资源。
2 量化
为了进一步降低图像传输码率,需要对图像进一步压缩,方法是使用变换编码及量化技术。
2.1 量化原理
H.264中采用标量量化器。标量量化器的原理是:
其中,y为输入样本点编码,Qstep为量化步长,FQ为y的量化值。H.264标准支持52个量化步长。量化的简化操作如下:
其中,Wij为输入样本点编码,MF是标准中定义的值,QP为量化系数,f为偏移量,对帧内预测图像块f取2qbits/3,对帧间预测图像块f取2qbits/6。
2.2 量化器实现
量化器硬件结构如图2所示,其结果是实现对式(4)和式(5)的组合电路。W是需要量化的数据,MF是根据QP和当前点位置在查找表中得到的值。f和qbits是根据QP查表的输出。
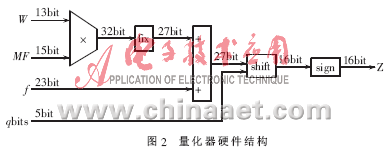
为了硬件资源消耗最少,需要分析数据在计算过程中的动态范围,使用最少的数据宽度来表示传输的数据,从而使用最少的硬件资源来实现组合运算逻辑。W是整数变换结果,根据整数变换部分的分析,其取值范围是[-3 060,4 080],MF最大取13107,乘法器输出动态范围是[-40 107 420,53 476560],至少用27位二进制数表示。本量化器的乘法器使用Vetex-Ⅱ中的18×18硬件乘法器,因此在输入加法器之前需要将数据宽度调整为27bit。加法器输出的27位数据通过移位模块调整为16位数据宽度。
综合考虑工作频率和资源占用率,设计中使用2级流水线来提高性能。
2.3 量化器优化
本量化器一次只能量化一个点,无法满足高质量图像编码的要求。针对高质量图像编码对此量化器进行速度优化,即将n个量化器并联,一个时钟周期计算n个点。n根据实际需要进行选择。考虑到与变换模块的速度匹配,选择16个量化器并联。
3 软核设计及测试
3.1 PLB总线的软核结构
PLB(Processor Local Bus)总线是IBM开发的一种高性能片上总线,主要应用于PowerPC405处理器系统中,它支持32位、64位和128位数据宽度。本设计使用64位总线宽度,最大速据传输速率达800Mb/s。
如图3,PLB的软核设计分为总线接口和H.264整数变换量化模块两部分。PLB总线接口是与硬件体系结构相关的部分,它是整数变换量化模块与PLB总线上其他设备进行交互的桥梁。整数变换量化模块与体系结构无关,它也可以被移植到ARM体系结构中。
FPGA 仿真 电路 总线 ARM Xilinx USB 相关文章:
- 基于FPGA的片上系统的无线保密通信终端(02-16)
- 基于Virtex-5 FPGA设计Gbps无线通信基站(05-12)
- 基于FPGA的DVI/HDMI接口实现(05-13)
- 基于ARM的嵌入式系统中从串配置FPGA的实现(06-09)
- 采用EEPROM对大容量FPGA芯片数据实现串行加载(03-18)
- 赛灵思:可编程逻辑不仅已是大势所趋,而且势不可挡(07-24)