尝试通过算法重构和Vivado HLS生成高效的处理流水线
时间:04-13
来源:互联网
点击:
流水线化内存访问
有了解耦处理流水线的初步实施方案后,我们就可以对其执行几项优化,以提高其效率。正如我们所见,当使用HLS映射C函数时,内存读取出现阻塞。这个问题也出现在流水线中的个别阶段。例如,负责加载x[curInd]的模块在等待数据时可能会产生拖延,即使在下个curInd已经就绪而且FIFO下游有足够空间的情况下亦是如此。
为了解决这个问题,我们可以做一下转变以简化内存访问。对于某个特定阶段,我们不在C函数中执行简单的内存加载,而是将地址推送到新的FIFO。然后,单独实例化一个新的硬件模块,以读取地址FIFO送出的地址,并将它们发送到内存子系统。返回的数据被直接推送到下游FIFO。现在,内存访问得到了有效的流水线化。
地址的推送操作可在Vivado HLS中通过向FIFO接口的内存存储来代表,AXI总线协议允许您指定突发长度;而且,通过对解耦C函数进行一些小的修改,并利用流水线化的内存访问模块,我们就可利用该功能。
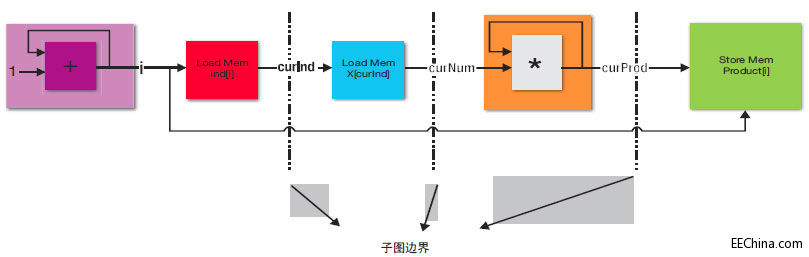
图3 – 对子图的重构

图4 – 背包问题
除了生成地址以外,解耦C函数中每个内存操作符还要在连续存储块被访问时计算突发长度。循环计数器的复制还有助于突发访问的生成,因为被访问的字数量可以在每个解耦函数中本地确定。
不过,用以监测下游FIFO和发送内存请求的硬件模块则采用Verilog实现。这是因为在由Vivado HLS综合的内存接口中,外发地址和响应数据没有捆绑在一起。不过这是一个简单模块,能在不同基准测试中重用很多次,因此设计工作就被摊销了。
复制或通信?
在重构内核并生成解耦处理流水线的过程中,用来在不同阶段移动数据的FIFO会形成很大开销。通过复制少量计算指令可以去除一些FIFO,这样通常很有好处,因为即使是最小深度的FIFO也会占用不少FPGA资源。
一般而言,在权衡利弊以探究最佳设计点的过程中,您可以使用成本模型和规范的优化技术。但在大多数基准测试中,仅仅为它的每个用户复制简单的循环计数器就可以节省很多面积,这也正是我们所做的。在这个引导性实例中, 该优化是指复制i的整数加法器,因此存储结果 i时不需要从其它模块获得索引。
内存的突发访问
第三项优化是内存的突发访问(burst-memory access)。为了更高效地利用内存带宽,我们希望通过一次内存事务处理携带多个数据字。
实验评估
我们应用上述方案做了几个案例研究。 为评估这种方法的优势,我们将使用该方案生成的解耦处理流水线 (DPP)与单纯使用HLS生成的加速器进行比较。当为单纯或DPP实现方案调用Vivado HLS时,我们将目标时钟频率设置到150MHz,并在布局布线后使用所能达到的最高时钟速率。此外,我们针对加速器和内存子系统之间的交互尝试了不同的机制。所用的端口为ACP和HP。我们为每个端口在可重配置阵列上实例化一个64KB高速缓存。
本实验所用的物理器件是赛灵思的Zynq®-7000 XC7Z020全可编程SoC,安装在ZedBoard评估平台上。
我们还在Zynq SoC 的ARM®处理器上运行应用的软件版本,并将其性能作为实验的基准。生成的所有加速器功能齐全,无需任何DMA机制将数据移入和移出可重配置架构。
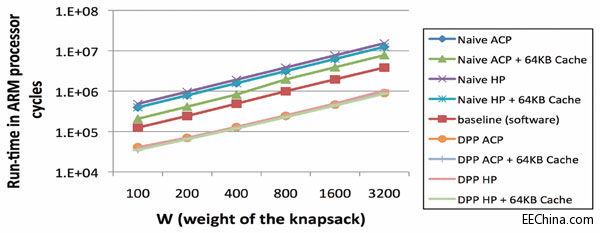
图5 – 针对背包问题的运行时间比较
案例研究1:
背包问题
众所周知,背包问题是一个组合问题,可以通过动态编程来求解。内核的结构如图4所示。其中黑体字的变量都是在运行时间从
内存读取。因此,无法确切知道从哪个位置加载的变量opt_without。当w和n 比较大时,我们无法在片上缓冲整个opt阵列。我们只能让计算引擎取回所需的部分。
图5给出了运行时间对比情况,将使用我们的方案(DPP)生成的加速器与单纯通过HLS推送函数而生成的加速器进行比较。图中还显示了在ARM处理器上运行函数时的性能。 我们将n(项数)固定为40,使w (背包的总重量)在100至3,200之间变化。

图6 – 稀疏矩阵向量乘法
从对比中很容易看出,通过单纯使用Vivado HLS来映射软件内核这种方法得到的 ARM处理器性能高出约4.5倍。另外,当使用
加速器性能比基准要求慢很多。 DPP时,各种内存访问机制之间的Zynq SoC 上的超标量 差别相当小——使用我们的方案时,无序式ARM内核能受内存访问时延的影响要小很多。
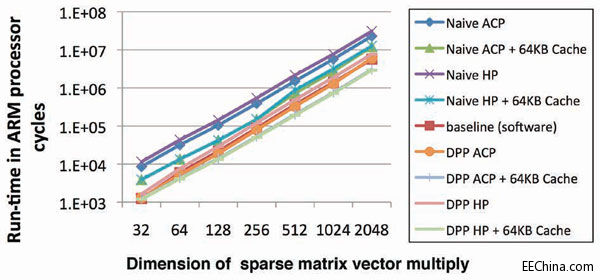
图7 – 针对稀疏矩阵向量乘法的运行时间对比
很大程度开拓指令级并行性,而且具有一个高性能片上高速缓存。Vivado HLS工具提取的案例研究2:稀疏矩阵向量乘法
附加并行性显然不足以补偿硬处理器内核对于稀疏矩阵向量(SpMV)乘法是一个可编程逻辑的时钟频率优势计算内核,已经在各种研究项目中以很多不同方法进行过研究、变换和基准确定。这里,我们的目的不是以及来自可重配置阵列的使用特殊数据结构和存储分配方式更长的数据访问时延。构建最佳性能的SpMV乘法,不过,当内核被解耦,分成而是想根据最基本的算法描述多个处理阶段时,看看在使用Vivado HLS时重构性能就会明显比传递能提供多少优势。
如图6所示,在我们的实验中,稀疏矩阵以压缩稀疏行(CSR)格式存储。在取回数字以进行实际的浮点乘法之前,需要先执行来自索引数组的负载。用来决定访问哪个控制流程和内存位置的数值只有在运行时间才知道。在图7所示的运行时间对比中,矩阵的平均密度为1/16,尺寸在32和2,048之间变化。
此处,单纯的映射法在性能上再次落后于软件版。当不使用FPGA上的高速缓存时,用我们的方法生成的解耦处理流水线在性能上几乎与基准性能相同。
当在可重配置阵列上实例化一个64KB高速缓存时,DPP的性能接近基准的两倍。与之前的基准相比,高速缓存的增加对DPP的性能具有更显著的影响。
案例研究3:FLOYD-WARSHALL 算法
Floyd-Warshall是一种图形算法,用来找到任意一对顶点之间成对的最短路径。内存访问模式比之前的基准要简单。因此,有可能存在一种方法可以设计出DMA+加速器结构,以获得很好的计算重叠和片外通信。我们的方案能试着自动实现这种重叠,但是我们尚未进行相关的研究,以表明绝对最佳与实际所得之间的差距。
不过,与之前的基准一样,我也进行了运行时间对比。这里,我们使图形的大小在40个节点至160个节点之间变化。每个节点平均有全部节点的1/3作为其邻点。得到的结果与背包问题中的十分类似。

图8 –Floyd-Warshall算法
解耦处理流水线所实现的性能约为软件基准的3倍,吞吐量达到任何单纯映射法的两倍多。当使用DPP时,对FPGA高速缓存的影响也很小,展示出了对于内存访问时延的容限。
我们这种简单的技术构建出的处理流水线可以更好地使用内存带宽,而且对内存时延有更好的容限,因此能够改善Vivado HLS的性能。所描述的方法可对控制数据流图中的内存访问和较长的依赖循环解耦,这样高速缓存缺失就不会拖延加速器的其它部分。
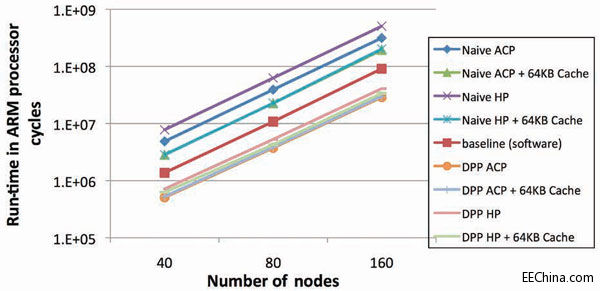
图9 – 针对Floyd-Warshall算法的运行时间比较
有了解耦处理流水线的初步实施方案后,我们就可以对其执行几项优化,以提高其效率。正如我们所见,当使用HLS映射C函数时,内存读取出现阻塞。这个问题也出现在流水线中的个别阶段。例如,负责加载x[curInd]的模块在等待数据时可能会产生拖延,即使在下个curInd已经就绪而且FIFO下游有足够空间的情况下亦是如此。
为了解决这个问题,我们可以做一下转变以简化内存访问。对于某个特定阶段,我们不在C函数中执行简单的内存加载,而是将地址推送到新的FIFO。然后,单独实例化一个新的硬件模块,以读取地址FIFO送出的地址,并将它们发送到内存子系统。返回的数据被直接推送到下游FIFO。现在,内存访问得到了有效的流水线化。
地址的推送操作可在Vivado HLS中通过向FIFO接口的内存存储来代表,AXI总线协议允许您指定突发长度;而且,通过对解耦C函数进行一些小的修改,并利用流水线化的内存访问模块,我们就可利用该功能。
图3 – 对子图的重构
图4 – 背包问题
除了生成地址以外,解耦C函数中每个内存操作符还要在连续存储块被访问时计算突发长度。循环计数器的复制还有助于突发访问的生成,因为被访问的字数量可以在每个解耦函数中本地确定。
不过,用以监测下游FIFO和发送内存请求的硬件模块则采用Verilog实现。这是因为在由Vivado HLS综合的内存接口中,外发地址和响应数据没有捆绑在一起。不过这是一个简单模块,能在不同基准测试中重用很多次,因此设计工作就被摊销了。
复制或通信?
在重构内核并生成解耦处理流水线的过程中,用来在不同阶段移动数据的FIFO会形成很大开销。通过复制少量计算指令可以去除一些FIFO,这样通常很有好处,因为即使是最小深度的FIFO也会占用不少FPGA资源。
一般而言,在权衡利弊以探究最佳设计点的过程中,您可以使用成本模型和规范的优化技术。但在大多数基准测试中,仅仅为它的每个用户复制简单的循环计数器就可以节省很多面积,这也正是我们所做的。在这个引导性实例中, 该优化是指复制i的整数加法器,因此存储结果 i时不需要从其它模块获得索引。
内存的突发访问
第三项优化是内存的突发访问(burst-memory access)。为了更高效地利用内存带宽,我们希望通过一次内存事务处理携带多个数据字。
实验评估
我们应用上述方案做了几个案例研究。 为评估这种方法的优势,我们将使用该方案生成的解耦处理流水线 (DPP)与单纯使用HLS生成的加速器进行比较。当为单纯或DPP实现方案调用Vivado HLS时,我们将目标时钟频率设置到150MHz,并在布局布线后使用所能达到的最高时钟速率。此外,我们针对加速器和内存子系统之间的交互尝试了不同的机制。所用的端口为ACP和HP。我们为每个端口在可重配置阵列上实例化一个64KB高速缓存。
本实验所用的物理器件是赛灵思的Zynq®-7000 XC7Z020全可编程SoC,安装在ZedBoard评估平台上。
我们还在Zynq SoC 的ARM®处理器上运行应用的软件版本,并将其性能作为实验的基准。生成的所有加速器功能齐全,无需任何DMA机制将数据移入和移出可重配置架构。
图5 – 针对背包问题的运行时间比较
案例研究1:
背包问题
众所周知,背包问题是一个组合问题,可以通过动态编程来求解。内核的结构如图4所示。其中黑体字的变量都是在运行时间从
内存读取。因此,无法确切知道从哪个位置加载的变量opt_without。当w和n 比较大时,我们无法在片上缓冲整个opt阵列。我们只能让计算引擎取回所需的部分。
图5给出了运行时间对比情况,将使用我们的方案(DPP)生成的加速器与单纯通过HLS推送函数而生成的加速器进行比较。图中还显示了在ARM处理器上运行函数时的性能。 我们将n(项数)固定为40,使w (背包的总重量)在100至3,200之间变化。
图6 – 稀疏矩阵向量乘法
从对比中很容易看出,通过单纯使用Vivado HLS来映射软件内核这种方法得到的 ARM处理器性能高出约4.5倍。另外,当使用
加速器性能比基准要求慢很多。 DPP时,各种内存访问机制之间的Zynq SoC 上的超标量 差别相当小——使用我们的方案时,无序式ARM内核能受内存访问时延的影响要小很多。
图7 – 针对稀疏矩阵向量乘法的运行时间对比
很大程度开拓指令级并行性,而且具有一个高性能片上高速缓存。Vivado HLS工具提取的案例研究2:稀疏矩阵向量乘法
附加并行性显然不足以补偿硬处理器内核对于稀疏矩阵向量(SpMV)乘法是一个可编程逻辑的时钟频率优势计算内核,已经在各种研究项目中以很多不同方法进行过研究、变换和基准确定。这里,我们的目的不是以及来自可重配置阵列的使用特殊数据结构和存储分配方式更长的数据访问时延。构建最佳性能的SpMV乘法,不过,当内核被解耦,分成而是想根据最基本的算法描述多个处理阶段时,看看在使用Vivado HLS时重构性能就会明显比传递能提供多少优势。
如图6所示,在我们的实验中,稀疏矩阵以压缩稀疏行(CSR)格式存储。在取回数字以进行实际的浮点乘法之前,需要先执行来自索引数组的负载。用来决定访问哪个控制流程和内存位置的数值只有在运行时间才知道。在图7所示的运行时间对比中,矩阵的平均密度为1/16,尺寸在32和2,048之间变化。
此处,单纯的映射法在性能上再次落后于软件版。当不使用FPGA上的高速缓存时,用我们的方法生成的解耦处理流水线在性能上几乎与基准性能相同。
当在可重配置阵列上实例化一个64KB高速缓存时,DPP的性能接近基准的两倍。与之前的基准相比,高速缓存的增加对DPP的性能具有更显著的影响。
案例研究3:FLOYD-WARSHALL 算法
Floyd-Warshall是一种图形算法,用来找到任意一对顶点之间成对的最短路径。内存访问模式比之前的基准要简单。因此,有可能存在一种方法可以设计出DMA+加速器结构,以获得很好的计算重叠和片外通信。我们的方案能试着自动实现这种重叠,但是我们尚未进行相关的研究,以表明绝对最佳与实际所得之间的差距。
不过,与之前的基准一样,我也进行了运行时间对比。这里,我们使图形的大小在40个节点至160个节点之间变化。每个节点平均有全部节点的1/3作为其邻点。得到的结果与背包问题中的十分类似。
图8 –Floyd-Warshall算法
解耦处理流水线所实现的性能约为软件基准的3倍,吞吐量达到任何单纯映射法的两倍多。当使用DPP时,对FPGA高速缓存的影响也很小,展示出了对于内存访问时延的容限。
我们这种简单的技术构建出的处理流水线可以更好地使用内存带宽,而且对内存时延有更好的容限,因此能够改善Vivado HLS的性能。所描述的方法可对控制数据流图中的内存访问和较长的依赖循环解耦,这样高速缓存缺失就不会拖延加速器的其它部分。
图9 – 针对Floyd-Warshall算法的运行时间比较
C语言 赛灵思 FPGA 电路 总线 Verilog SoC ARM CSR 相关文章:
- 周立功:如何兼顾学习ARM与FPGA(05-23)
- 初学者如何学习FPGA(08-06)
- 为何、如何学习FPGA(05-23)
- 智能命令行设计及其在 SOPC 系统中的应用(08-14)
- 我的FPGA学习历程(05-23)
- 赛灵思详解新近推出的FPGA领域设计平台(12-16)