FPGA仿真器与定制硅仿真器的区别
时间:01-22
来源:互联网
点击:
作者:LauroRizzatti
10多年以来,我一直坚定地支持基于FPGA的硬件仿真系统,并在2013年一直不遗余力地宣传其优势。自那以后,我已成为精通各类硬件仿真专业知识的顾问,但现在来评论FPGA硬件仿真系统与定制硅硬件仿真系统之间的区别似乎有些姗姗来迟。
商用FPGA硬件仿真器与定制硅硬件仿真器之间的根本区别在于映射被测设计(DUT)的核心单元。顾名思义,定制硅硬件仿真器是基于定制器件而造,不可用于商业用途。定制硅硬件仿真器就是采用两个不同种类当中的一个来实现的。
在第一类中,核心单元是专为硬件仿真应用而设计的定制FPGA,但通用FPGA是个糟糕的选择。Mentor Graphics提供一种称为Crystal2的此类器件,并称之为定制片上硬件仿真器,如图1。在第二类中,核心单元包括大量简单的布尔处理器,此类处理器在巨大的内存中执行设计数据结构存储。Cadence供应商称之为“基于处理器的硬件仿真器”。很显然,定制FPGA硬件仿真器与商用FPGA硬件仿真器具有一些相似之处,但仍然具备独特的功能。

图1:Mentor Graphiscs Crystal2“定制片上硬件仿真器”。
定制FPGA硬件仿真器
定制FPGA硬件仿真器由法国初创公司MetaSystems(1996年被Mentor Graphics收购)最先开发并商业化,采用不同于Xilinx和Altera所提供的独特FPGA。该硬件仿真器是基于定制硅上仿真器架构,专为涵盖整个硬件仿真器(包括可配置单元、局部互连矩阵、嵌入式多端口内存、I/O通道、带探测电路的调试引擎和时钟发生器)的仿真应用而设计。
这种方法使用了三个创新点,每个创新点都可提供独特的优势:
●可编程单元的内部互连网络;
●定制FPGA的外部互连网络和I/O结构;
●DUT调试引擎。
可编程单元的内部互连网络
可编程单元的互连网络包括两个不同分级层:位于查找表(LUT)及其集群(Cluster)级别的低层;以及更大块的LUT集群,即所谓的叠块的高层。
可以用空间类推法来描述低层。假设所有的LUT都位于球体表面上,任何两个LUT互连都必须穿过球体中心,则无论两个LUT位于何处,互连导线的长度始终相同。(图2)。

图2:描述低层空间类推法。
上述类推法延伸到更高层级,LUT集群可以分布在更大球体的表面上,并采用相同的方式互连(图3)。这基本上是一个重复相同模式的分形图,从外到内或从内到外移动。高层通过专利结构互连叠块,提供类似于低层固有的优势。
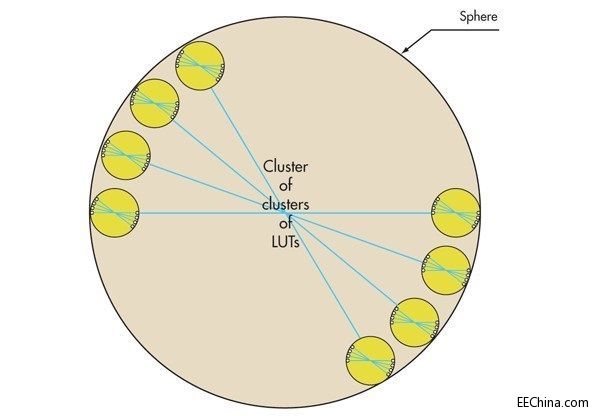
图3:高层级空间类推法。
高层通过微小的交互开关矩阵(有些类似于片上网络(NoC)架构)互连叠块,因此使该结构有别于传统网格互连网络。这种方法可以确保布线可预测、快速和无拥塞。
此外,时钟树通过导线连接到独立于数据路径的专用路径,因而可以预测和重复时序,并通过构造防止时序违规行为,因为数据路径比时钟路径更长。不可预测的时序和保持时间违规行为会破坏商用FPGA的可用性。
与商用FPGA的结构相比,定制方法可以确保时序的确定性和可重复性。该方法消除了布局约束,确保实现简单的布线和快速的编译(图4)。
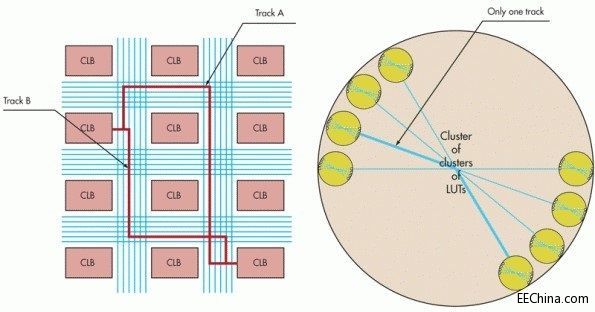
图4:商用FPGA与定制的对比。
多层互连网络对高容量进行权衡,现可用于最大的FPGA,并支持快速和无拥塞的FPGA布局和布线(P&R)。可以在约五分钟内对一个定制FPGA进行布局布线。即使将最大FPGA的填充率降低至50%或以下,P&R仍可能需要几个小时。
毫无疑问,与使用当前市场上最大的商用FPGA相比(例如Xilinx Virtex-7 XC7V2000T),映射10亿ASIC等效门设计将需要更多的定制FPGA器件。实际差异可能会小于通过比较内部资源(例如LUT)估算的结果,因为定制FPGA的利用率接近100%,而商用FPGA则为50%左右。
以下因素有助于减轻容量差距:内置的VirtualWire逻辑(用于I/O数最大化而不是消耗LUT);内置的调试引擎(节约留给DUT映射的宝贵的可配置资源);以及一个有效的布线器。
这两种技术都受益于在多个PC分配P&R,但定制方法仍然具有优势。在一系列定制FPGA上对10亿ASIC等效门设计进行布局和布线(在大型模拟场进行操作)可能需要30分钟。在一系列较小的Xilinx Virtex-7上对相同的设计进行布局和布线将需要几个小时。
拥有了该技术,定制FPGA硬件仿真器供应商可以管控运营,优化和定制P&R软件,而这是商用FPGA硬件仿真器供应商无法做到的。因为后者受FPGA厂商支配。
片上硬件仿真器的外部互连网络
片上硬件仿真器的外部互连网络是基于所谓的VirtualWire技术。借助VirtualWire,FPGA集合会自动编译为一个巨大的FPGA,该FPGA不会受到可破坏通过传统方式互连的一系列等效FPGA的潜在时序问题的影响。该技术在开发时仅可用于采用商用FPGA的硬件仿真器。现在,相同的技术已嵌入到片上硬件仿真器。
VirtualWire是基于多个再综合流程(时序、存储器、互连),此类流程将DUT转换为映射到一系列定制片上硬件仿真器器件的功能等效的设计。
时序再综合使用正确性维护转换来重新定时用户的设计,通过引入单个高速时钟来保护其免受不准确的FPGA延迟。此外,还消除了传统硬件仿真系统的保持时间问题。
存储器再综合实现低成本实施各类存储器(包括宽多端口RAM),无需构建定制存储卡或使用FPGA存储器。多路复用和存储器共享支持使用快速且便宜的常见SRAM芯片进行存储器硬件仿真。
互连再综合通过在器件固定和有限数量的I/O管脚上增加传输中的I/O信号数,来扩展器件间的通信带宽,并以最大速度进行连接。最终结果是,器件利用率显著提高到约100%,避免拥塞并维护DUT完整性。
在每个I/O管脚增加I/O信号类似于在FPGA原型板上实施I/O数最大化的方法。
VirtualWire实现更为复杂。该技术:
●通过保证局部时序正确性实现全局时序正确性和系统可扩展性;
●提供为所有触发器计时的虚拟时钟,分配单个同步低偏移时钟;
●信号布线和调度受编译器控制,因为信号必须通过已知数量的FPGA。
VirtualWire实现还扩展了带宽,从而可提高FPGA和导线的利用率。多路复用技术可以扩展各级封装的互连带宽,从FPGA间和板间到机箱间,使得分区更容易。
此外,还提供相同的多路复用技术来访问存储器。通过对数据总线进行多路复用,可以使用常见的SRAM芯片构建宽存储器。可以使用SRAM芯片实施多端口存储器。可以在布线和调度步骤中整合存储器调度。
10多年以来,我一直坚定地支持基于FPGA的硬件仿真系统,并在2013年一直不遗余力地宣传其优势。自那以后,我已成为精通各类硬件仿真专业知识的顾问,但现在来评论FPGA硬件仿真系统与定制硅硬件仿真系统之间的区别似乎有些姗姗来迟。
商用FPGA硬件仿真器与定制硅硬件仿真器之间的根本区别在于映射被测设计(DUT)的核心单元。顾名思义,定制硅硬件仿真器是基于定制器件而造,不可用于商业用途。定制硅硬件仿真器就是采用两个不同种类当中的一个来实现的。
在第一类中,核心单元是专为硬件仿真应用而设计的定制FPGA,但通用FPGA是个糟糕的选择。Mentor Graphics提供一种称为Crystal2的此类器件,并称之为定制片上硬件仿真器,如图1。在第二类中,核心单元包括大量简单的布尔处理器,此类处理器在巨大的内存中执行设计数据结构存储。Cadence供应商称之为“基于处理器的硬件仿真器”。很显然,定制FPGA硬件仿真器与商用FPGA硬件仿真器具有一些相似之处,但仍然具备独特的功能。
图1:Mentor Graphiscs Crystal2“定制片上硬件仿真器”。
定制FPGA硬件仿真器
定制FPGA硬件仿真器由法国初创公司MetaSystems(1996年被Mentor Graphics收购)最先开发并商业化,采用不同于Xilinx和Altera所提供的独特FPGA。该硬件仿真器是基于定制硅上仿真器架构,专为涵盖整个硬件仿真器(包括可配置单元、局部互连矩阵、嵌入式多端口内存、I/O通道、带探测电路的调试引擎和时钟发生器)的仿真应用而设计。
这种方法使用了三个创新点,每个创新点都可提供独特的优势:
●可编程单元的内部互连网络;
●定制FPGA的外部互连网络和I/O结构;
●DUT调试引擎。
可编程单元的内部互连网络
可编程单元的互连网络包括两个不同分级层:位于查找表(LUT)及其集群(Cluster)级别的低层;以及更大块的LUT集群,即所谓的叠块的高层。
可以用空间类推法来描述低层。假设所有的LUT都位于球体表面上,任何两个LUT互连都必须穿过球体中心,则无论两个LUT位于何处,互连导线的长度始终相同。(图2)。
图2:描述低层空间类推法。
上述类推法延伸到更高层级,LUT集群可以分布在更大球体的表面上,并采用相同的方式互连(图3)。这基本上是一个重复相同模式的分形图,从外到内或从内到外移动。高层通过专利结构互连叠块,提供类似于低层固有的优势。
图3:高层级空间类推法。
高层通过微小的交互开关矩阵(有些类似于片上网络(NoC)架构)互连叠块,因此使该结构有别于传统网格互连网络。这种方法可以确保布线可预测、快速和无拥塞。
此外,时钟树通过导线连接到独立于数据路径的专用路径,因而可以预测和重复时序,并通过构造防止时序违规行为,因为数据路径比时钟路径更长。不可预测的时序和保持时间违规行为会破坏商用FPGA的可用性。
与商用FPGA的结构相比,定制方法可以确保时序的确定性和可重复性。该方法消除了布局约束,确保实现简单的布线和快速的编译(图4)。
图4:商用FPGA与定制的对比。
多层互连网络对高容量进行权衡,现可用于最大的FPGA,并支持快速和无拥塞的FPGA布局和布线(P&R)。可以在约五分钟内对一个定制FPGA进行布局布线。即使将最大FPGA的填充率降低至50%或以下,P&R仍可能需要几个小时。
毫无疑问,与使用当前市场上最大的商用FPGA相比(例如Xilinx Virtex-7 XC7V2000T),映射10亿ASIC等效门设计将需要更多的定制FPGA器件。实际差异可能会小于通过比较内部资源(例如LUT)估算的结果,因为定制FPGA的利用率接近100%,而商用FPGA则为50%左右。
以下因素有助于减轻容量差距:内置的VirtualWire逻辑(用于I/O数最大化而不是消耗LUT);内置的调试引擎(节约留给DUT映射的宝贵的可配置资源);以及一个有效的布线器。
这两种技术都受益于在多个PC分配P&R,但定制方法仍然具有优势。在一系列定制FPGA上对10亿ASIC等效门设计进行布局和布线(在大型模拟场进行操作)可能需要30分钟。在一系列较小的Xilinx Virtex-7上对相同的设计进行布局和布线将需要几个小时。
拥有了该技术,定制FPGA硬件仿真器供应商可以管控运营,优化和定制P&R软件,而这是商用FPGA硬件仿真器供应商无法做到的。因为后者受FPGA厂商支配。
片上硬件仿真器的外部互连网络
片上硬件仿真器的外部互连网络是基于所谓的VirtualWire技术。借助VirtualWire,FPGA集合会自动编译为一个巨大的FPGA,该FPGA不会受到可破坏通过传统方式互连的一系列等效FPGA的潜在时序问题的影响。该技术在开发时仅可用于采用商用FPGA的硬件仿真器。现在,相同的技术已嵌入到片上硬件仿真器。
VirtualWire是基于多个再综合流程(时序、存储器、互连),此类流程将DUT转换为映射到一系列定制片上硬件仿真器器件的功能等效的设计。
时序再综合使用正确性维护转换来重新定时用户的设计,通过引入单个高速时钟来保护其免受不准确的FPGA延迟。此外,还消除了传统硬件仿真系统的保持时间问题。
存储器再综合实现低成本实施各类存储器(包括宽多端口RAM),无需构建定制存储卡或使用FPGA存储器。多路复用和存储器共享支持使用快速且便宜的常见SRAM芯片进行存储器硬件仿真。
互连再综合通过在器件固定和有限数量的I/O管脚上增加传输中的I/O信号数,来扩展器件间的通信带宽,并以最大速度进行连接。最终结果是,器件利用率显著提高到约100%,避免拥塞并维护DUT完整性。
在每个I/O管脚增加I/O信号类似于在FPGA原型板上实施I/O数最大化的方法。
VirtualWire实现更为复杂。该技术:
●通过保证局部时序正确性实现全局时序正确性和系统可扩展性;
●提供为所有触发器计时的虚拟时钟,分配单个同步低偏移时钟;
●信号布线和调度受编译器控制,因为信号必须通过已知数量的FPGA。
VirtualWire实现还扩展了带宽,从而可提高FPGA和导线的利用率。多路复用技术可以扩展各级封装的互连带宽,从FPGA间和板间到机箱间,使得分区更容易。
此外,还提供相同的多路复用技术来访问存储器。通过对数据总线进行多路复用,可以使用常见的SRAM芯片构建宽存储器。可以使用SRAM芯片实施多端口存储器。可以在布线和调度步骤中整合存储器调度。
FPGA 仿真 Mentor Cadence Xilinx Altera 嵌入式 电路 总线 相关文章:
- 基于FPGA的片上系统的无线保密通信终端(02-16)
- 基于Virtex-5 FPGA设计Gbps无线通信基站(05-12)
- 基于FPGA的DVI/HDMI接口实现(05-13)
- 基于ARM的嵌入式系统中从串配置FPGA的实现(06-09)
- 采用EEPROM对大容量FPGA芯片数据实现串行加载(03-18)
- 赛灵思:可编程逻辑不仅已是大势所趋,而且势不可挡(07-24)