看FPGA如何在大数据的热潮中坐实第一把交椅
数据正在成为人类社会进步新的驱动力。有专家预测,未来5年中国大数据产业规模年均增长率将超过50%,到2020年中国的数据总量将占全球数据总量比例的20%,成为世界第一数据资源大国和全球数据中心。不过在垂涎于这个大数据盛宴的同时,我们也面临着一个"成长中的烦恼":我们是否有足够的能力去处理和"消化"这些海量的数据?虽然近年来数据中心的数量也在快速增加,但是面对数据处理任务指数级的增长,还是需要从更底层的核心硬件架构上寻求解决方案。
通用CPU是传统数据中心的核心,不过由于它是基于指令译码执行、共享内存的经典的冯·诺依曼结构, 注定了其可以完成复杂性的数据处理工作,但是处理大量并行的、重复性的数据并非其强项。"多核"CPU是一个应对之策,但仍然无法摆脱架构的限制,加之摩尔定律日益逼近天花板,依托制程工艺的进步带来性能上的提升,这条路也越来越不好走。因此异构处理器的概念被提出来,简单地说,就是将CPU不擅长的工作卸载到其他更适合的器件中去处理,不同架构的数据处理器件协同工作,各司其职,提升效率。在异构数据处理中,究竟谁适合与CPU"相加",业界有不同的思路,通常吞吐率、延迟、功耗和灵活性会被作为评估的基本标准。
在异构处理器中,"CPU+GPU"是一个重要选项。GPU采用SIMD(单指令流多数据流)的方式让多个执行单元以同样的步调处理不同的数据,大大提升了并行数据处理的能力,在计算密集型任务中可堪重用。不过GPU有一个"硬伤",就是在延迟比较高。这是因为GPU虽可实现数据并行但是其流水线深度受限,每个计算单元处理不同的数据包时,需要按照统一的步调做相同的事,这就使得输入输出的延迟增加,通常GPU的延迟会达到毫秒级。

要想克服上述问题,就需要今天的主角"FPGA"出场了。FPGA是一种可编程逻辑器件,可以根据需要通过软件编程去定义器件的硬件功能,非常灵活。这也就意味着基于FPGA的数据处理架构,每个逻辑单元的功能都是定义好的,无需指令就可完成工作,也不需要复杂的共用内存的调度和裁判,摆脱了冯·诺依曼架构的牵绊。在延时方面,FPGA的优势尤为明显,其不但可以实现数据并行,还可以实现流水线并行,流水线的不同级处理不同的数据包,这就使得不同数据的处理无需等待更为便捷,其延时只有微秒级。从数据吞吐能力上看,新一代FPGA的数据处理加速能力理论上已经可以与GPU比肩。同时拜不断进步的半导体工艺所赐,FPGA器件的功率也控制得很好。所以CPU+FPGA这种异构处理器组合被越来越多的人所看好。
还有一种技术选择我们不得不提一下,那就是ASIC。单从性能上讲,为特定网络数据加速目的而制造的专用ASIC芯片无疑在吞吐量、延迟、功耗方面都是最具竞争力的,但是有两个因素使其被数据中心用户拒之门外:一是ASIC的研发和流片成本越来越高,除非有足够的规模,否则经济性上没有优势;二是一旦数据处理任务需求发生变化,功能固化的ASIC就"废"了,而如果使用FPGA则无需担心这个问题,只要重新编程重新定义器件的功能即可,这对用户的投资是很有效地保障。这就是FPGA在灵活性上的优势。
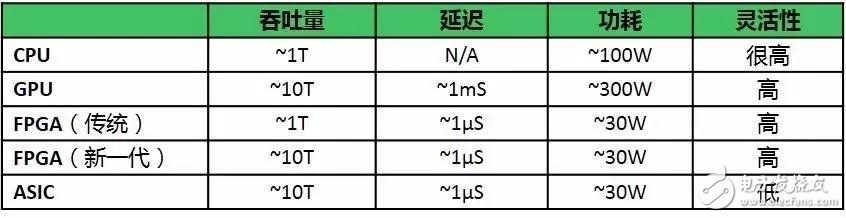
表1,几种数据处理架构在计算密集型任务中的性能比较
可以说,在异构处理架构中,虽然每种技术都各有千秋,但是FPGA各方面的表现最为均衡,可以令用户获得的效益最大化。由此也就不难理解一年前Intel为什么乐于花费巨资收购全球排名第二的FPGA厂商Altera,此举也无疑为FPGA未来在数据中心中的地位做了背书。同时,在FPGA行业头把交椅上的Xilinx近年来的表现也更加活跃和抢眼,横向合作上与AMD、ARM、华为、IBM、Mellanox、高通等共推开放式的数据加速架构,打造生态链;纵向上接连绑定亚马逊、百度等互联网巨头,让FPGA在人工智能、视频处理、 自然语言处理、金融分析、网络安全等未来核心数据应用处理领域,坐实其核心的位置。显而易见,大数据之"火",已经点着了FPGA,谁能抓住机会,谁就能在大数据的热潮中火一把。

图1,Xilinx的FPGA被用于百度数据中心,未来会对百度的无人驾驶汽车提供支撑

图2,腾讯推出的FPGA云服务器,可为用户提供FPGA云租用服务
- 用大电流LDO为FPGA供电需要低噪声、低压差和快速瞬态响应(08-17)
- 基于FPGA 的谐波电压源离散域建模与仿真(01-30)
- 基于FPGA的VRLA蓄电池测试系统设计(06-08)
- 降低从中间总线电压直接为低电压处理器和FPGA供电的风险(10-12)
- FPGA和功能强大的DSP的运动控制卡设计(03-27)
- DE0-Nano-SoC 套件 / Atlas-SoC 套件(10-30)