Board从入门到精通系列(八)
时间:02-11
来源:网络整理
点击:
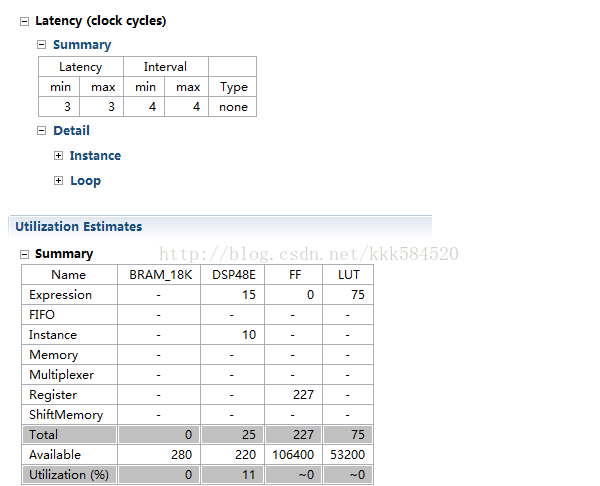
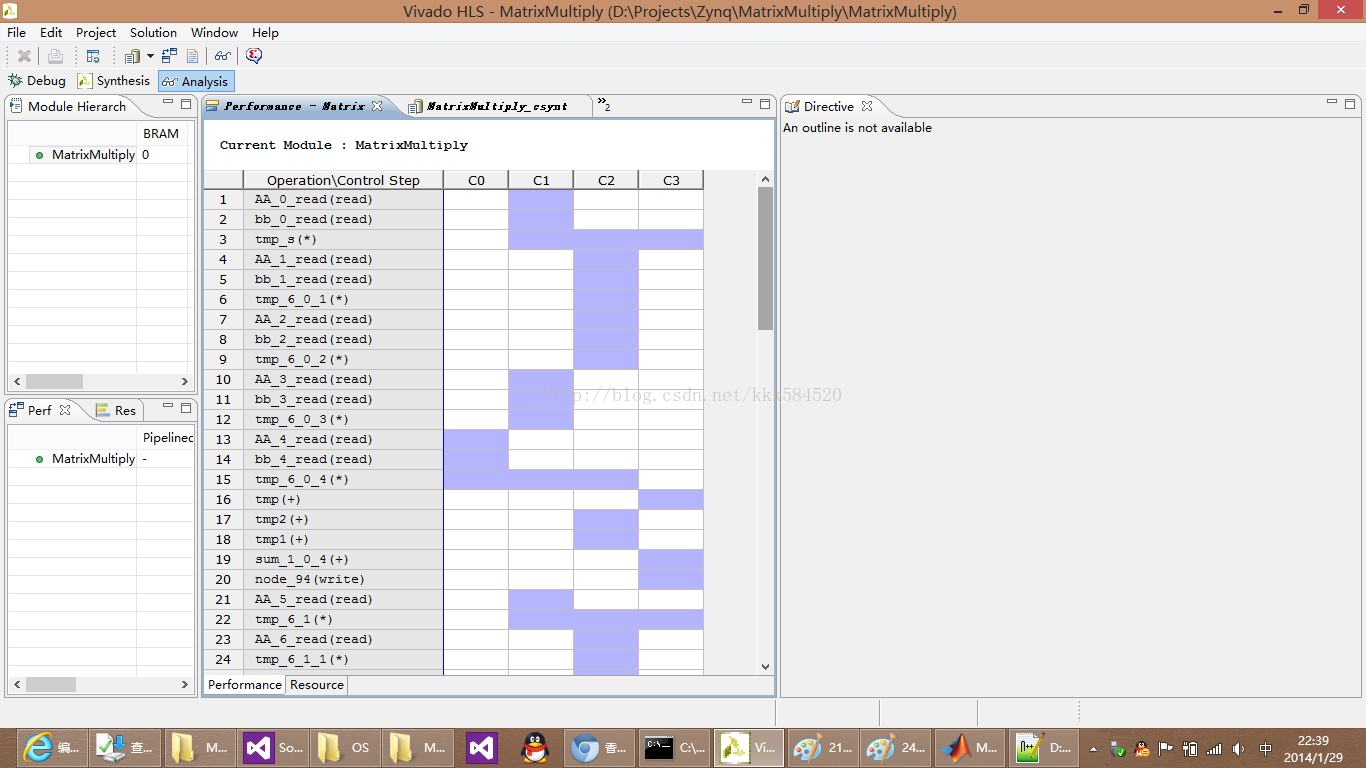
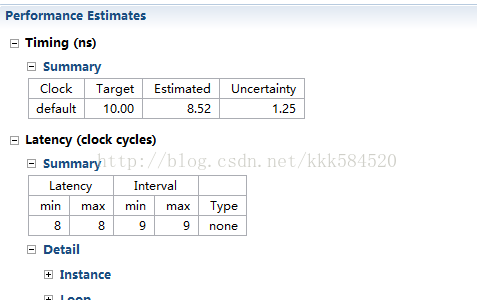
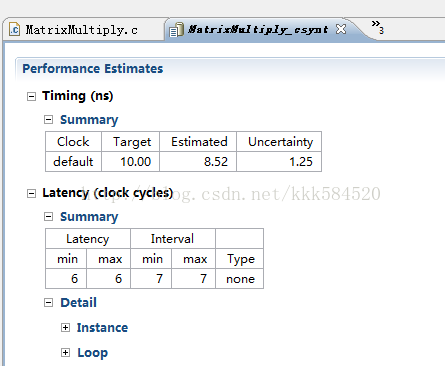
极限了呢???答案是否定的。我们进入Analysis视图,看一下还有哪些地方可以优化的。经过对比发现bb也需要分解,于是按照上面的方法对bb进行资源优化,也用ROM-2P类型,也做全分解,再次综合,结果如下:



#include <ap_cint.h>
typedef uint15 data_type;
由于matlab生成的随机数在1~100以内,乘积范围不会超过10000,于是取15bit就能满足要求。首先验证下结果的正确性,用C Simulation试一下。结果如下: