Board从入门到精通系列(八)
= 0;i<N;i++)
{
data_type sum = 0;
for(j = 0;j<N;j++)
{
sum += AA[i*N+j]*bb[j];
}
cc[i] = sum;
}
}
将TestMatrixMultiply.c内容改为:[cpp]


<p>#include <stdio.h>
typedef int data_type;
#define N 5</p><p>const data_type MatrixA[] = {
#include "A.h"
};
const data_type Vector_b[] = {
#include "b.h"
};
const data_type MatlabResult_c[] = {
#include "c.h"
};</p><p>data_type HLS_Result_c[N] = {0};
void CheckResult(data_type * matlab_result,data_type * your_result);
int main(void)
{
printf("Checking Results:\r\n");
MatrixMultiply(MatrixA,Vector_b,HLS_Result_c);
CheckResult(MatlabResult_c,HLS_Result_c);
return 0;
}
void CheckResult(data_type * matlab_result,data_type * your_result)
{
int i;
for(i = 0;i<N;i++)
{
printf("Idx %d: Error = %d \r\n",i,matlab_result[i]-your_result[i]);
}
}
</p>
首先进行C语言仿真验证,点这个按钮:



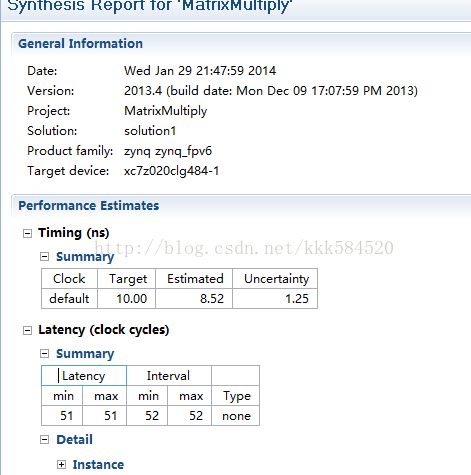
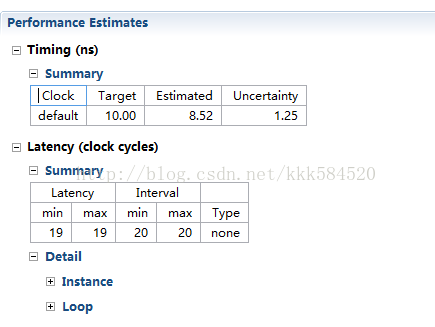

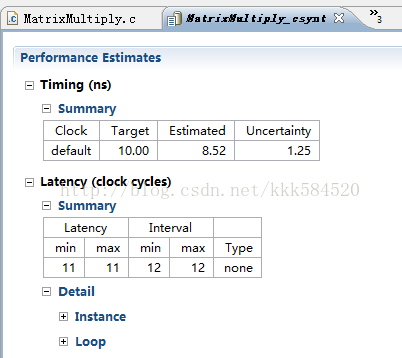 延迟进一步降低,已经降到11个时钟周期了!!!是否已经达到
延迟进一步降低,已经降到11个时钟周期了!!!是否已经达到