FPGA助力智能化人群监控系统
超出图像平面,就可以分类为可能的恐慌情况。该算法的开发工作使用微软 Visual C++ 配合 OpenCV 库完成。算法的完整演示请参阅本文文末提供的 Web 链接。
FPGA 实现方案
系统设计的第二阶段是该算法的 FPGA 实现过程。 这一步实现工作有它自己的设计难题,例如 FPGA 设计现在要包括视频输入/输出和帧缓存。此外,有限的资源和可用性能可能需要必要的设计优化。
鉴于这些设计特点和其它架构考虑,整个 FPGA 实现方案被分为三个部分。第一部分是在 FPGA 上开发通用的实时视频流水线,用于处理必要的视频输入/输出和帧缓存。第二部分是开发算法专用硬件加速器。最后在设计的第三阶段,我们把它们集成到一起,实现算法控制和数据流。这就完成了整个基于 FPGA 的系统设计。
下面对这个过程的每一阶段进行更详细的介绍。
实时视频流水线
在为 FPGA 平台开发任何视频处理应用时,实时视频流水线都是最重要的构建模块。这个流水线对用户隐藏了视频输入/输出和帧缓存相关的复杂存储器管理工作,而是提供了简单的访问界面以供用户处理视频帧数据。
虽然在这方面目前有几种先进的、商业许可的视频流水线[3],我们选择构建针对这个用途的定制视频流水线。我们基于赛灵思 EDK 构建该流水线,使用定制视频采集/显示端口处理视频输入/输出数据。这个流水线也可以方便地进行配置,从而用于其它赛灵思 FPGA 系列。
视频采集端口负责解码来自视频 ADC 的输入视频流数据并在本地缓存。随后该数据被转发至主存储器,用于创建视频帧。与此类似,视频显示端口负责对本地缓存中存储的视频帧数据进行编码,然后将其转发到视频 DAC 中供显示使用。视频输入输出端口连接到 MicroBlaze 主机处理器的主外设总线,该处理器负责处理与主存储器之间的视频数据流量。
视频端口能够生成中断,以通知 MicroBlaze 处理器在视频输入端口有可用的新数据或视频输入端口需要新数据。两种视频端口采用"往复式"缓存管理方案,这样即使是 MicroBlaze 处理器都无法立即响应视频端口,也不会发生缓存溢出或欠载。图2所示是视频端口与 MicroBlaze 处理器之间的互联。
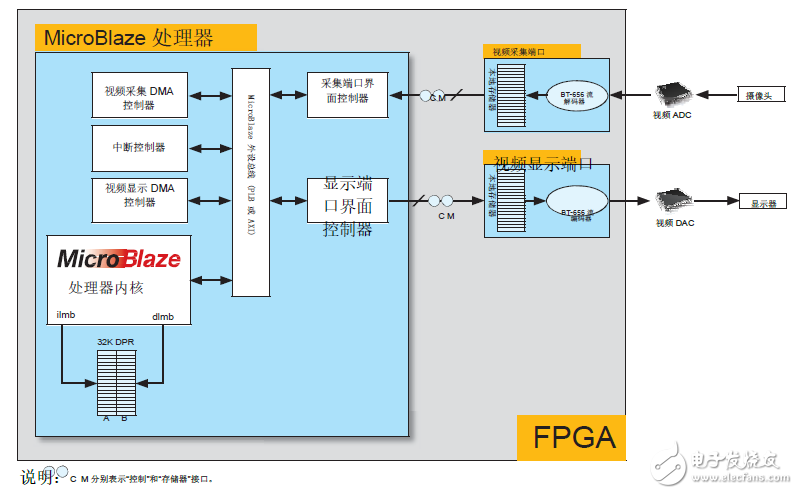
图 2:视频端口及其互联
视频端口设计用于检测和生成视频行数量、场 ID(如果是隔行视频)和视频输入/输出流中的其它控制信息。当有足够数量的视频数据被视频输入端口缓存,或当视频显示端口请求的数据达到足够数量时,该信息就会通过视频端口的中断服务例程 (ISR) 传递给 MicroBlaze 处理器。这些服务例程相应地通过 DMA 完成视频端口本地存储器和主存储器之间的视频数据传输。
除了视频端口 ISR,还有我们称之为"视频帧队列 API"的一套高级视频帧队列管理功能在这些 ISR 和用户层应用之间工作。该 API 负责维持多个采集帧和显示帧的队列,以支持双帧或三帧缓存方案。在MicroBlaze上运行的用户应用能轻松获得视频采集帧,或利用"视频帧队列 API"功能提供视频显示帧。图 3 显示了在层级结构中各级别的相关功能。
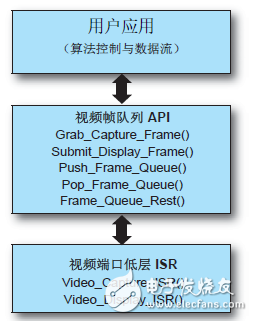
图 3:视频端口 ISR 和视频帧队列 API 功能
将 MicroBlaze 用作主机处理器以连接系统中的各个构建模块能产生众多优势。例如我们可以使用 MicroBlaze 方便地连接各种外部存储器(SRAM、SDRAM 等),加载或存储来自视频端口的视频帧数据。类似地,我们可以使用 EDK 中的 DMA 控制器,在视频端口和主存储器之间传输视频数据。此外,我们还可用 MicroBlaze 处理器以同样方式连接定制硬件加速器。
这些"视频帧队列 API"功能加上视频端口 ISR 和视频输入输出端口让设计中的视频处理流水线的构造更加完善。图 4 所示的是使用 FPGA 上的本视频流水线采集、处理和显示实际的视频帧。它还显示了通过计算出的运动向量缩小视图实现的画中画功能。

图 4:右下被运动向量网格覆盖的、经过 FPGA 处理后的实际帧
基于 Vivado HLS 的硬件加速器
在前文介绍的人群运动分类算法中,最为耗时、计算最密集的工作是计算运动向量。另一项系统工作——进行分类——因不涉及像素级的处理,非常简单而且易于实现。注意到设计的这个方面,我们为计算运动向量构建了一个硬件加速器。我们借助赛灵思 Vivado HLS,用 C/C++ 语言在 RTL 中对该加速器进行了设计、测试和综合。
Vivado 生成的 RTL 代码的关键特征之一是其在很大程度上已经过了精心优化。Vivado HSL 把阵列存取(例如存储在阵列中的像素数据)综合到存储器接口中,通过分析代码自动生成所需的地址。Vivado HSL 还可分析预先计算好的偏
FPGA 相关文章:
- 用大电流LDO为FPGA供电需要低噪声、低压差和快速瞬态响应(08-17)
- 基于FPGA 的谐波电压源离散域建模与仿真(01-30)
- 基于FPGA的VRLA蓄电池测试系统设计(06-08)
- 降低从中间总线电压直接为低电压处理器和FPGA供电的风险(10-12)
- FPGA和功能强大的DSP的运动控制卡设计(03-27)
- DE0-Nano-SoC 套件 / Atlas-SoC 套件(10-30)