基于ADSP-TS101S的多芯片数字信号处理系统的实现方案
摘 要:本文是基于ADSP-TS101S的多芯片数字信号处理系统的实现方案。该系统应用于某雷达的信号处理机。文中首先介绍了多片TIgerSHARC DSP芯片构成的信号处理系统组成;其次估计系统的运算量,所需计算时间;最后具体说明了CPLD产生复位信号及并-串转换功能实现的方法。
引言
随着人们对实时信号处理要求的不断提高和大规模集成电路的迅速发展,作为数字信号处理的核心和标志的DSP得到了快速的发展和应用。本文基于ADI公司的一款DSP —— TIgerSHARC,比较详细地介绍了在信号处理系统中的一套具体实现方案。

图1 信号处理机结构框图
系统设计及各部分功能简介
本系统是某雷达的信号处理机,通过ADC读入中频数据,DSP1、DSP2完成数据的脉冲压缩和旁瓣抑制,DSP3、DSP4完成数据的积累和求模,DSP5实现视频数据的归一化、通过DAC输出视频数据和发送并行数据。系统结构如图1所示。
本系统中,ADC采用具有12位有效数据位、25MSPS转换速率的AD9225,将I、Q两路模拟信号以某一采样率转换为数字信号,高10位送至DSP。
本系统采用TIgerSHARC DSP,该芯片最高运行速度300MHz,内核指令周期3.3ns,每周期能够执行多达4条指令,24个16-bit定点运算和6个浮点运算,并包含6MB的片内SRAM,具有很高的存储和运算性能,在信号处理领域应用价值很高。为了简化系统硬件,减少DSP片间连线,系统的5个DSP以松耦合的链路方式进行连接。DSP1通过外部DMA方式读入中频解调后的I、Q路数据,DSP1对读入的部分数据进行脉冲压缩(匹配滤波),并将处理后的数据及未处理数据通过链路口2发送给DSP2。DSP2对剩余的数据进行脉冲压缩。DSP2将所有处理完的数据送至DSP3。由于要进行几十帧的积累,数据量很大,DSP3和DSP4分别承担一半数据的积累、求模运算。DSP4把求模结果发到DSP5。DSP5将数据归一化生成视频数据,视频数据以DMA方式通过外部口送出。在不同工作模式下还要发送并行数据到CPLD。
程序加载:本系统采用EPROM程序引导方式。利用TIgerSHARC DSP的链路口进行数据传送时,每次发送字长必须设置4字,发送字数必须为4的倍数,且数据起始地址必须每4字对齐。故发送方DSP必须每次从EPROM读入4个32位字,通过加载链路发送。
DAC采用具有10位有效数据位、125MSPS转换速率的高速器件AD9750,将视频数据以某固定速率转换为模拟信号。
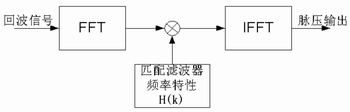
图2脉冲压缩滤波器算法框图
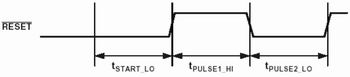
图3 TigerSHARC DSP的上电复位波形
CPLD完成数据锁存、DSP的复位信号产生和将并行数据转换为某波特率的串行数据输出(串行输出满足RS-232标准)等功能。
时钟:DSP内部均采用板内40MHz晶振产生的时钟。A/D取样时钟应与系统时钟锁相,故将10MHz系统时钟经ICS 601M锁相为40MHz,经40ME脚输入CPLD,分频后产生A/D采样时钟信号,D/A采样的工作时钟也由它产生。单板调试时只能全部利用板内时钟工作,故40ME要用跳线器选择。
电源:TigerSHARC DSP有三个电源,数字3.3V,用于I/O供电;数字1.2V,用于DSP内核供电;模拟1.2V,用于内部锁相环和倍频电路供电。TigerSHARC DSP要求数字3.3V和1.2V应同时上电。若无法严格同步,应保证内核电源1.2V先上电,I/O电源3.3V后上电。本系统在数字3.3V输入端并上大电容,数字1.2V输入端并上小电容,使得3.3V充电时间大于1.2V充电时间,很好地解决了电源的供电先后问题。各片DSP的数字1.2 V电源各由一片MAX1951将+5V转换成1.2V供给。所有DSP的模拟1.2V电源统一由一片REG1117A将模拟+5V转换成1.2V供给。5片DSP的I/O 3.3V电源由一片REG1117将数字+5V转换成3.3V统一供给。
系统运算量分析及
计算时间估计
根据信号雷达处理的任务,下面具体分析系统各组成部分运算量,估计所需计算时间。(信号处理每帧应小于1ms)
脉冲压缩
采用FFT技术实现脉冲压缩滤波,算法如图2所示。根据运算需要,要做512、1024和4096点复数FFT。复数FFT完成后,它必须和预先存储好的匹配滤波器系数H(k)相乘,需要做512、1024和4096个复数乘法,相乘结果还需做512、1024和4096点复数IFFT以获得脉压结果。TS101做1024点复数FFT(IFFT)在本系统的实际应用中大约需要50ms(工作在200MHz)。可以充分利用TS101双运算块,单指令多数据(SIMD)的特点,同时进行两个距离单元的复数乘法,完成1024个复数乘法仅需15ms。这样完成512、1024和4096点的脉冲压缩,分别需要60ms、120ms和460ms。由于DSP1要采用DMA方式对每帧数据分段读数,没有充足时间进行4096点脉冲压缩,因此将其放在DSP2中完成。
旁瓣抑制
采用时域综合法对二相码进行旁瓣抑制,在脉冲压缩的匹配滤波系数中综合旁瓣抑制系数,从而达到抑制旁瓣的效果。该算法是在脉冲压缩的基础上实现的,对DSP的运算量和时间不产生附加影响。
积累
积累采用滑窗积累法,计算量较少,TS101实现有较大时间富余。实际要求至少35帧积累,每个周期I、Q两路共2×3200点,需约2×3200×35=224K字节的存储空间。因此分别在DSP3、DSP4完成积累运算。
- 基于视觉的ADAS解决方案,近在咫尺!(05-07)
- 精通信号处理设计小Tips(5):三个应用广泛的数学概念(11-20)
- 精通信号处理设计小Tips(6):卷积是怎么得到的?(11-24)
- 精通信号处理设计小Tips(2):数学的作用(11-03)
- 精通信号处理设计小Tips(3):必须掌握的三大基石(11-09)
- 精通信号处理设计小Tips(7):应用极其广泛的相关(12-01)