基于FPGA的语音端点检测
。先介绍下Lawrence Rabiner端点检测法,这种方法以过零率ZRC和能量E为特征来检测起止点,具体方法为:
该算法是以基于能量的起止点算法。根据发音刚开始前已知为"静"态的的连续10帧内的数据,计算能量阈值T1(低能量阈值)及T2(高能量阈值)。开始计算前10帧每帧的能量,设其最大值称之为MX,最小值为MN,过零率阈值为ZCT,则有:
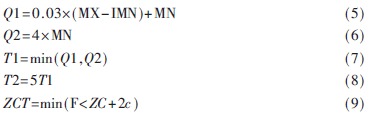
其中,F为固定值,一般为25,ZC和c分别为最初10帧过零率的均值和标准差。先根据T1、T2算得初始起点BN(起点帧号)。方法为:从第11帧开始,逐次比较每帧的平均幅度,BN为能量超过T1的第一帧的帧号。但若后续帧的能量在尚未超过T2之前又降到T1之下,则原BN不作为初始起点,改记下一个能量超过了T1的帧的帧号为BN,依此类推,在找到第一个能量超过T2的帧时停止比较。当BN确定后,从BN帧向(BN-25)帧搜索,依次比较各帧的过零率,若有3帧以上的ZCR>ZCT,则将起点BN定为满足ZCR>ZCT的最前帧的帧号,否则即以BN为起点。这种起点检测法也称双门限前端检测算法。语音结束点EN(结束点帧号)的检测方法与检测起点相同,从后向前搜索,找第一个能量低于T1且其前向帧的能量在超出T2前没有下降到T1以下的帧的帧号,记为EN,随后根据过零率向(EN=25)帧搜索,若有3帧以上的ZCR≥ZCT,则将结束点EN定为满足ZCR≥ZCT的最后帧的帧号,否则即以EN作为结束点。
这种算法硬件实现起来比较复杂,而且速度慢,所以要对算法进行改进。改进后的算法为:超过高门限可以用于确定语音的开始,低门限用于确定语音的终点。超过高门限未必就是语音的开始,有时候噪声的能量也可能相当大从而超过高门限,但是噪声一般持续时间比较短,可以用超过高门限持续时间来决定是噪声还是语音开始。当高门限已经确定语音开始后,再利用低门限来确定语音的结束点。低于低门限未必就是语音的结束,有时候语音信号的能量也可能低于低门限,但是语音信号低于低门限的时间不可能很长,可以用低过低门限的时间来判断语音的结束点。这样起止点的检查,就减少了过零率的判断和前10帧过零率均值和标准差的计算。所以这个算法门限值的选择对语音端点检测的影响比较大,本设计的门限值是根据Lawrence Rabiner端点检测法并通过大量实验得来,计算式如式(10)和式(11)。其中,AE为前14帧的平均能量、T1是低门限、T2是高门限。
T1=1.5AE(10)
T2=2T1(11)
在FPGA设计中,状态机的设计方法是最广泛的设计方法之一,FSM(有限状态机)及其设计技术是实用数字系统设计的重要组成部分,是高效率、高可靠逻辑控制的重要途径。而改进后的算法可以把整个端点判断过程分为三个状态,可以利用状态机来完成FPGA的设计。状态转换图如图1所示。S0、S1、S2是三个状态;E为帧能量;T1、T2分别是低门限和高门限;C1是在状态S1中T2>E≥T1的帧数;C2是在状态S1中T2≤E的帧数;C3是在状态S2中T1>E的帧数。
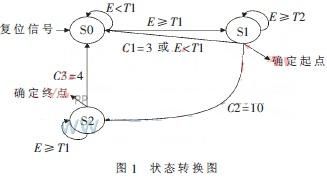
具体判断过程为:(1)在S0状态下,E
2 实验结果
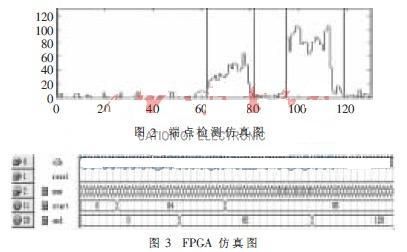
实验时的声音样本采用电脑声卡采集(16 kHz,8 bit)的"wav"文件, 并对常用的词语进行实验。图2是词"长沙"在Matlab上的端点检测仿真结果图,其中横坐标代表帧号、纵坐标代表帧能量。两个字的语音段分别是64~82帧和95~120帧。图3是词"长沙"在QuartusⅡ上仿真的结果图,其中num代表每帧的帧号,start代表语音开始的帧号,end代表语音结束的帧号。从图1、图2可以看出词"长沙"的端点检查仿真结果在Quartus Ⅱ上的和Matlab上是一致的,从图中可以看出改进后的端点检测方法检测效果非常好。
本文在加窗的过程中合理地运用了DSP Builder工具,简化了硬件的设计,同时也加快了处理速度,是一种很值得借鉴的FPGA加窗方法。在端点判断的算法上,用改进的Lawrence Rabiner端点检测法,对算法门限的计算和起止点判断做了改进,并用有限状态机实现了FPGA的设计,实验证明该算法在低信噪比的情况下能准确地找到语音信号的起止点。与其他一些端点检测方法相比,该算法更加简单、稳定,所需的存储空间小,是一种理想的硬件端点检查方法,对语音识别系统的开发和设计有一定的参考价值。
- 远程测控中嵌入式Web服务器的FPGA实现(10-30)
- 基于DSP Builder的DDS设计及其FPGA实现(11-03)
- 基于FPGA的DDS调频信号的研究与实现 (11-04)
- 使用混合信号示波器验证测量混合信号电路(11-05)
- 基于速度匹配软件的网络芯片仿真方法(11-06)
- 利用FPGA实现原型板原理图的验证(11-07)