应用两级分类实现车牌字符识别
3 二级分类识别
3.1 细分类特征提取
细分类的特征提取方法应该能够表征字符细节信息,刻画形近字间更细微的差别。结构特征可以很好地反映字符的细节特征。所以本文选取环数、弯曲度、交点数等结构特征作为细分类的特征提取方法。
(1)环数(H):字符中闭合曲线的个数。
(2)弯曲度(R):设字符中光滑曲线段的两个端点为M(Mx,My)和N(Nx,Ny),这两点所构成线段为MN,曲线到线段MN垂直距离最远的点为T,对应的投影点为P,点T到线段MN的距离Dtp和该线段长度Dmn的比值为弯曲度R,则: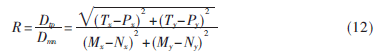
(3)交点数(E):在水平或垂直方向上扫描字符时与字符相交的次数。以左右上下水平垂直的首字母L、R、T、B、L、V与特征的组合表示具体提取的特征,如TR表示上笔画弯曲度。
在二级分类识别中,分类器根据环数、弯曲度和交点数等结构特征的逻辑组合对形近字进行分类识别,得出的决策表如表1所示。例如,字符‘2’和‘Z’的差别在于上面横笔画的弯曲度;字符‘C’和‘G’的差别在于垂直交点数。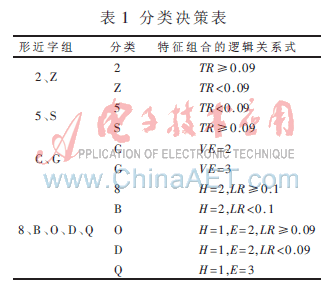
3.2细分类实验和分析
形近字符分为四组,每组选120个样本做测试,形近字符的识别结果如表2所示。
表2中形近字符是否具有较高的识别率,在很大程度上取决于特征的选取。首先将形近字符分成不同的组,然后根据细微的差别提取不同的结构特征,使得同一组中不同字符之间的细微差异能比较稳定地体现出来,这是正确识别形近字的关键。实验表明决策表可以很好地区分形近字符,达到二级细分类识别的要求。
4 实验结果
实验中的测试车牌图像是由重庆易博数字有限公司研制的电子警察在高速公路收费站拍摄的,总共采集了一天中不同时段的几千幅车牌图像,大部分为本市的车辆,所以车牌图像中的汉字均相同。在测试时,从这几千幅车牌图像中,总共选取1 200幅车牌图像,并随机分为3组作为实验中的测试车牌图像,且仅统计英文字母和数字部分的识别率,最终的识别率以车牌牌照为单位进行实验,识别结果如表3所示。
本文算法在P4 2.80 GB、512 MB计算机上,用VC6. 0编程实现,平均识别一个车牌需要0.3 s左右的时间。
本文在分析常用的车牌识别方法和人眼视觉活动特点的基础上,设计了一种由粗到细的二级识别算法,使车牌中易混的形近字符识别率得以提高。在特征提取方面将统计特征和结构特征相结合,并对提取的轮廓特征进行优化,使其有效地克服了字符偏移的影响。引入可信度评判机制,提升了分类识别的灵活性和可靠性。从实验结果可以看出,本文的算法取得了较高的识别正确率,实时性好,可以满足实际应用的需要。
- 基于决策导向非循环图SVM的汽车车型识别(08-29)