趣科技︱从英伟达GPU到谷歌TPU,AI芯片之争难落幕
如今,有一个词听到耳根生茧却有些触不可及,这个词就是"人工智能",曾经它活在科幻小说中,如今它活在新闻标题中,然而降临在我们身边,还是一个未知的时间、未知的地点、未知的场景。
自2016年3月AlphaGo战胜李世石,全世界掀起了一场对人工智能的热恋,一个仍在实验室里的襁褓瞬间就成了国民对象。一场AI军备竞赛也逐渐浮出水面,无论是科技大佬还是初创公司,谁都不愿错过这场即将爆发的AI风暴。
前几天,谷歌又掀起一场AI风波,TPU来袭、剑指GPU,本来就难分胜负的AI芯片之战,更扑朔迷离。
那么本期《趣科技》我们就来讲讲谁是AI时代真正的"硬"角色。

最近我们总听到一种论调"中国人工智能直追美国",而麦肯锡最新研究报告显示,尽管中国在人工智能的论文数量方面超过美国,但是中国AI研究的影响力尚不及美国或者英国。这究竟是为什么?为何一个很鼓舞人心的消息后面总有一个残酷的现实。
在人工智能的赛道上,有三大军团,即算法、计算能力、芯片,而核心阵地显然是在硬件方面。我国与美国的差距也主要是在此方面。
目前,在AI芯片领域,有几大竞争主力:
- GPU,视觉处理器,只有英伟达、AMD两大玩家;
- FPGA,现场可编程门阵列,玩家有赛灵思、Altera(已被英特尔收购)、Lattice、Microsemi;
- ASIC,专用集成电路,美国英特尔、高通、微软,英国Graphcore,中国中科院计算所、地平线机器人等均有布局;
- 类脑芯片,美国IBM、高通,中国中科院计算所、北京大学、中星微等已有不俗的成绩。
显然,在GPU和FPGA上我国缺席,在ASIC与类脑芯片上也只是一个追随者,这就是与美国的差距所在。而说我们紧追美国也不为过,在AI应用层面,在语音识别和定向广告等方面,百度已经走在全球前列。
随着人工智能的大量涌现,AI芯片市场群雄争霸,厂商纷纷推出新的产品,都想领跑智能时代--但问题是,谁会担当这个角色呢?

目前来看,GPU是厚积薄发正当时,在深度学习领域发挥着巨大作用;FPGA被视为AI时代的万能芯片,架构灵活独具特色;ASIC这个后起之秀,被企业视作引发一轮全面的颠覆的杰作。其推动代表之一就是谷歌,2016年宣布将独立开发一种名为TPU的全新的处理系统,而在前几日,这个神秘的TPU现真容。谷歌表示TPU 已经在谷歌数据中心内部使用大约两年,并且TPU 在推理方面的性能要远超过 GPU。
TPU,为深度学习而生的ASIC
TPU 是谷歌专门为加速深层神经网络运算能力而研发的一款芯片,可用来加速神经网络(NN)的推理阶段,其实是一款 ASIC。
我们先来看一下什么是ASIC,ASIC指依照产品需求不同而定制化的特殊规格集成电路,由特定使用者要求和特定电子系统的需要而设计、制造。一般来说,ASIC 在特定功能上进行了专项强化,可以根据需要进行复杂的设计,但相对来说,实现更高处理速度和更低能耗。相对应的,ASIC 的生产成本也非常高。
谷歌为什么要做TPU呢?一方面是有钱任性,毕竟一般公司很难承担为深度学习开发专门处理器 ASIC 芯片的成本和风险;另一方面是自身需求大,庞大的体量比如谷歌图像搜索、谷歌照片、谷歌云视觉 API、谷歌翻译等产品和服务都需要用到深度神经网络,开发一款ASIC可得到广泛的应用。
早在2011年谷歌就意识到他们遇到的问题,开始思考使用深度学习网络了,这些网络运算需求高,令他们的计算资源变得紧张。

CPU能够非常高效地处理各种计算任务,但 CPU 的局限是一次只能处理相对来说很少量的任务;GPU 在执行单个任务时效率较低,而且所能处理的任务范围更小,GPU 是理想的深度学习芯片,但是能耗的问题又非常严重。于是TPU应用而生。
下面我们就来看看谷歌是如何夸自家TPU的:
- 在神经网络层面的操作上,处理速度比当下GPU和CPU快15到30倍;
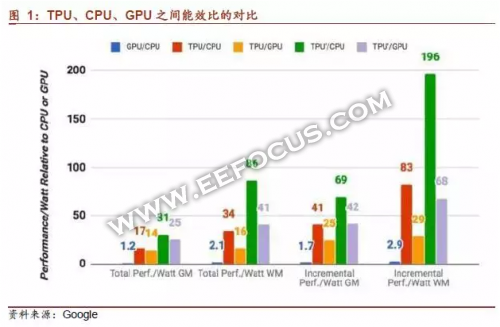
- 在能效比方面,速度/功率比(TOPS/Watt)比GPU和CPU高30到80倍,如果在 TPU 中使用 GPU 的 GDDR5 内存,速度(TOPS)将会翻三倍,速度/功率比(TOPS/Watt)能达到 GPU 的 70 倍以及 CPU 的 200 倍;
- 在代码上也更加简单,100到1500行代码即可以驱动神经网络。
"TPU 的中心是一个 65536 的 8 位 MAC 矩阵乘法单元,可提供 92 万亿次运算/秒(TOPS)的速度和一个大的(28 MiB)的可用软件管理的片上内存。相对于CPU和GPU的随时间变化的优化方法(高速缓存、无序执行、多线程、多处理、预取……),这种TPU的确定性的执行模型能更好地匹配我们的神经网络应用的 99% 的响应时间需求,因为CPU 和 GPU 更多的是帮助对吞吐量进行平
- 趣科技 | OLED/QLED技术争宠上位,苹果为啥翻了Micro LED的牌(01-22)
- 为什么说iPhone 8/iPhone X无线充电很鸡肋,从Qi讲起无线充电的故事(08-13)
- 又是一年Hot Chips,百度、微软的AI大招为何齐瞄准FPGA(07-25)
- 美博客称谷歌摩托移动交易可能成为一场灾难(08-16)
- 谷歌再加码投资可再生能源(10-10)
- 谷歌苹果在美手机市场排前两位(12-31)