又是一年Hot Chips,百度、微软的AI大招为何齐瞄准FPGA
一年一度的行业盛会国际高性能微处理器研讨会(Hot Chips)刚刚落下帷幕,会议期间微软、百度、英特尔等大佬都发布了一系列硬件方面的新信息。今天与非小编就带大家来看看Hot Chips上的"FPGA"亮点。
微软,Project Brainwave
微软推出了一套专用于机器学习模型的系统,代号为脑波计划(Project Brainwave)。这是一个运行在英特尔Stratix 10 FPGA上的GRU模型(一种循环神经网络,属于序列模型),用于云端加速深度学习。
要如何解读这个系统呢?
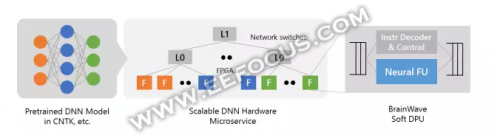
Brainwave使用的是微软多年来一直进行部署的FPGA 架构,这个系统架构可大大降低延迟,并允许较高的吞吐量。高性能 FPGA与数据中心相连接,将作为硬件微服务的DNN映射到远程FPGA池,并被没有软件的服务器所调用。

Brainwave是如何深度挖掘DNN处理单元(DPU)潜力的?
Brainwave结合FPGA上的ASIC数字信号处理模块和可合成的逻辑,以提供一个更大更优化数量的功能单元。而这是通过自定义数据类型与创新整合实现的。因此可以实现超越硬编码DPU芯片的性能。Project Brainwave DPU架构如下图:

除此之外,Brainwave还融合进一个支持多款主流深度学习框架的软件栈,目前Microsoft Cognitive Toolkit(CNTK)、Tensorflow均已兼容,微软计划支持更多框架。
简而言之,Brainwave的"硬"气之处就在于:
- 高性能的分布式系统架构
- 集成在FPGA的硬件DNN引擎
- 可低摩擦部署训练模型的编译器和runtime
因此,Brainwave可实现快速、灵活、友好的特点。
Brainwave可在无批处理的情况下支持每秒39.5万亿次浮点运算。无需批运算意味着硬件可以对请求进行实时处理,让机器学习系统能够真正实现实时性。
微软研究院的高级工程师Doug Burger曾说道:我们将其称为"实时人工智能",因为无论是视频流、对话、还是异常检测,所有需要交互的人工智能,你都希望它能够实时进行。
当然,我们不应该对此感到陌生。因为这已经不是微软第一次提出Brainwave的概念,过去的几年时间里,微软一直探索利用FPGA提升其必应浏览器与Azure的性能与效率。
因此,这个深度学习加速系统应运而生。借助Brainwave,微软能实现的美好愿景是什么呢?
业内人士分析:
微软通过Azure云服务将Brainwave提供给其他公司,当然,能拿下多大的市场还是未知的,毕竟这个领域的竞争很激烈,谷歌、Facebook、百度等等。但早一步布局等于机会更多一些。
百度XPU
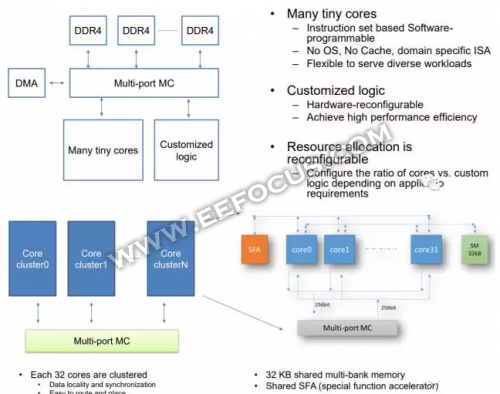
百度的AI大计与微软有着异曲同工之处,百度在Hot Chips大会上发布了XPU,这是一款256核、基于FPGA的云计算加速芯片,采用的是Xilinx平台。

XPU可以带来"飞"一般的体验?
XPU关注计算密集型、基于规则的多样化计算任务,希望提高效率和性能,并带来类似CPU的灵活性。而其目标是实现性能与效率之间的平衡,对多样化的计算任务进行处理。FPGA加速器本身很擅长处理某些计算任务,但随着许多小内核交织在一起,多样性程度将会上升。
关于这款芯片,百度研究员欧阳剑表示:芯片架构突出多样性,着重于计算密集型、基于规则的任务,同时确保效率、性能和灵活性的最大化。
FPGA中XPU的DSP单元提供了并行处理能力,片外DDR4和HBM接口优化了数据传输,而片上SRAM则提供了必要的存储特性。测试显示,对于计算密集型、常规内存访问的计算任务,XPU的效率与x86内核类似。对于数据同步的计算任务,XPU的可扩展性应当可以进一步优化。而对于没有数据同步的计算任务,XPU的可扩展性与核心数量呈线性关系。
当然,万事万物没有十全十全美的。据悉,XPU目前所欠缺的仍是可编程能力,而这也是涉及FPGA时普遍存在的问题。目前为止,XPU尚未提供编译器。
编译实现的办法与流程:
XPU在FPGA上实现,通过订制的逻辑电路提供指令。小核心类似于CPU,只能使用汇编语言,所有的执行都受主机控制。整个流程包括拆分计算任务,编写XPU代码,调用专用的逻辑函数,从而在Linux平台上进行编译和运行。
微软和百度同时将AI目光聚焦于FPGA,说明FPGA的AI地位更上一层,尤其在数据中心领域。
FPGA其实可以看作是半定制的ASIC,既解决了定制电路的不足,又在性能与应用广度上显示出优势,拥有ASIC/GPU无可比拟的灵活性,如今FPGA似乎已成为数据中心加速的主角。
作为FPGA的对手,ASIC与GPU各有优势,也各有弊端。
ASIC,为专门应用而设计,由于面向特定用户的需求,在加速效率上可圈可点。但其设计周期长、成本高、应用范围有限,因此ASIC仅适用于大批量或性能至上对成本不敏感的产品中。
如今的GPU已不再局限于3D图形处理,其在
NVIDIA 趣科技 FPGA Brainwave Hot Chips 相关文章:
- 显卡市场份额之争 AMD逐渐让位NVIDIA(08-04)
- GE Fanuc智能平台引用NVIDIA’s CUDA技术(09-16)
- Q1全球独显出货量暴跌三成,AMD、英伟达一片哀嚎(05-02)
- 台式PC无法满足胃口,Nvidia继续向移动图形处理前行(01-12)
- 清华同方酝酿暑促变局(05-17)
- 图形芯片竞争不断升级 Nvidia市场份额增12%(06-02)