趣科技︱从英伟达GPU到谷歌TPU,AI芯片之争难落幕
"TPU 的中心是一个 65536 的 8 位 MAC 矩阵乘法单元,可提供 92 万亿次运算/秒(TOPS)的速度和一个大的(28 MiB)的可用软件管理的片上内存。相对于CPU和GPU的随时间变化的优化方法(高速缓存、无序执行、多线程、多处理、预取……),这种TPU的确定性的执行模型能更好地匹配我们的神经网络应用的 99% 的响应时间需求,因为CPU 和 GPU 更多的是帮助对吞吐量进行平均,而非确保延迟性能。这些特性的缺失有助于解释为什么尽管 TPU 有极大的 MAC 和大内存,但却相对小和低功耗。我们将 TPU 和服务器级的英特尔 Haswell CPU 与现在同样也会在数据中心使用的英伟达 K80 GPU 进行了比较。我们的负载是用高级的 TensorFlow 框架编写的,并是用了生产级的神经网络应用(多层感知器、卷积神经网络和 LSTM),这些应用占到了我们的数据中心的神经网络推理计算需求的 95%。"
关于谷歌TPU,也许如下几张图给出的说明更清晰:
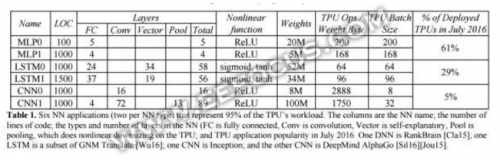
6 种神经网络应用(每种神经网络类型各 2 种)占据了 TPU 负载的 95%。表中的列依次是各种神经网络、代码的行数、神经网络中层的类型和数量(FC 是全连接层、Conv 是卷积层,Vector 是向量层,Pool 是池化层)以及 TPU 在 2016 年 7 月的应用普及程度。RankBrain使用了 DNN,谷歌神经机器翻译中用到了 LSTM,Inception 用到了 CNN,DeepMind AlphaGo也用到了 CNN。
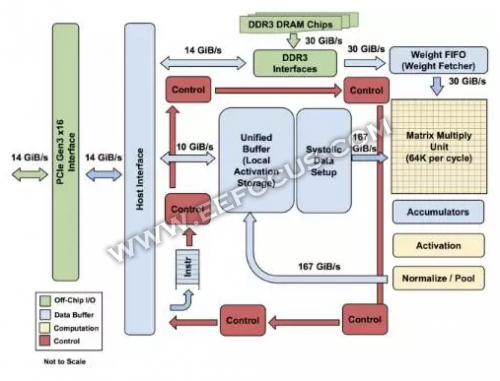
TPU 各模块的框图,主要计算部分是右上方的黄色矩阵乘法单元。其输入是蓝色的「权重 FIFO」和蓝色的统一缓存(Unified Buffer(UB));输出是蓝色的累加器(Accumulators(Acc))。黄色的激活(Activation)单元在Acc中执行流向UB的非线性函数。
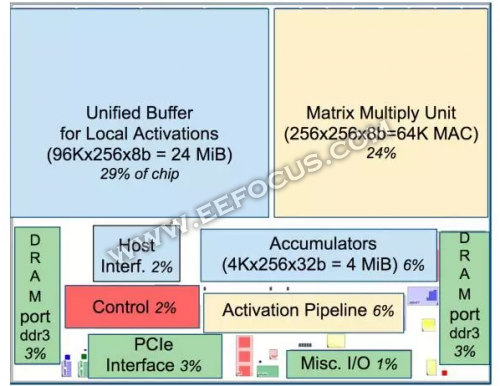
TPU 芯片布局图,蓝色的数据缓存占芯片的 37%。黄色的计算是 30%。绿色的I/O 是 10%。红色的控制只有 2%。CPU 或 GPU 中的控制部分则要大很多(并且非常难以设计)。
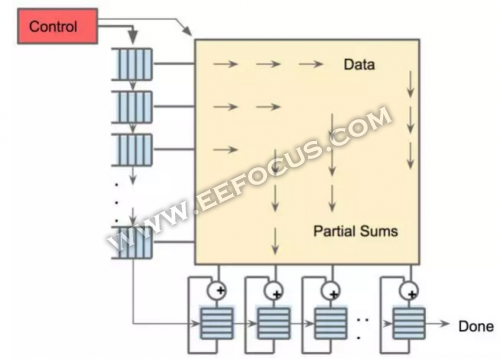
矩阵乘法单元的 systolic 数据流,软件具有每次读取 256B 输入的错觉,同时它们会立即更新 256 个累加器 RAM 中其中每一个的某个位置。
与GPU相比,TPU的优势还体现在:
TPU使用了大规模片上内存
谷歌可能意识到片外内存访问是 GPU 能效比低的罪魁祸首,因此在TPU上放了巨大的内存,高达 24MB 的局部内存、6MB 的累加器内存以及用于与主控处理器进行对接的内存,总共占芯片面积的 37%。这样下成本,可见谷歌是充分做了权衡的。。相比之下,英伟达 K80 只有 8MB 的片上内存,因此需要不断地去访问片外 DRAM。
TPU采用脉动式数据流
对于 GPU,从存储器中取指令与数据将耗费大量的时间。
TPU却不同,TPU 甚至没有取命令的动作,而是主处理器提供给它当前的指令,并根据目前的指令做相应操作,这使得 TPU 能够实现更高的计算效率。TPU 加入了脉动式数据流的支持,每个时钟周期数据移位,并取回一个新数据。这样做可以最大化数据复用,并减小内存访问次数,在降低内存带宽压力的同时也减小了内存访问的能量消耗。
TPU叫板者说了啥?
说的了这么多,TPU真的如谷歌描述的那样,能成为颠覆AI的那个芯片?
早在2016年英伟达的 CEO 黄仁勋就表示,两年前谷歌就意识到 GPU 更适合训练,而不善于做训练后的分析决策。由此可知,谷歌打造 TPU 的动机只是想要一款更适合做分析决策的芯片。这一点在谷歌的官方声明里也可得到印证,Google 资深副总裁Urs Holzle 表示,当前Google TPU、GPU 并用,这种情况仍会维持一段时间,GPU 可执行绘图运算工作,用途多元;TPU 属于ASIC,也就是专为特定用途设计的特殊规格逻辑IC,由于只执行单一工作,速度更快,但缺点是成本较高。

总而言之,TPU 只在特定应用中作为辅助使用,谷歌将继续使用 CPU 和 GPU。
谷歌TPU挑衅GPU,随后英伟达黄仁勋亲自撰文将将TPU 和英伟达最新品 P40 做比较,针尖对麦芒,要"还原"一个真相。我们看看黄仁勋都说了什么:
"英伟达 Tesla P40 在 GoogleNet 推断任务中的性能是 Google TPU 的 2倍。不仅如此,P40 的带宽也是 TPU 的十倍还多。"
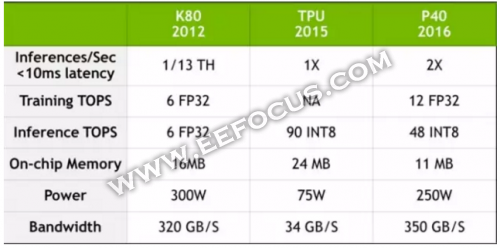
不过这个结果也是被广大明眼的网友无情吐槽:相同情况下,TPU 的能耗是 75W,而 P40 的能耗是 250W;谷歌论文里的是第一代 TPU(2015 年部署在谷歌数据中心),现在肯定已经升级好几代了--黄仁勋用最新 GPU与第一代TPU对比,GPU性能更优也无疑是必然的结果;还有一个很现实的问题摆在面前,这就是价格,P40 24GB版本售价5千多美元,TPU成本估计在几百美元,拿一"贵族"和一个"平民"比品味,这个也有点不合适吧。
不过,黄仁勋在文章
- 趣科技 | OLED/QLED技术争宠上位,苹果为啥翻了Micro LED的牌(01-22)
- 为什么说iPhone 8/iPhone X无线充电很鸡肋,从Qi讲起无线充电的故事(08-13)
- 又是一年Hot Chips,百度、微软的AI大招为何齐瞄准FPGA(07-25)
- 美博客称谷歌摩托移动交易可能成为一场灾难(08-16)
- 谷歌再加码投资可再生能源(10-10)
- 谷歌苹果在美手机市场排前两位(12-31)