突破深度学习硬件瓶颈,谷歌TPU创新性在哪?
存以及用于与主控处理器进行对接的内存,总共占芯片面积的37%(图中蓝色部分)。这表示Google充分意识到片外内存访问是GPU能效比低的罪魁祸首,因此不惜成本在芯片上放了巨大的内存。相比之下,Nvidia同时期的K80只有8MB的片上内存,因此需要不断地去访问片外DRAM。
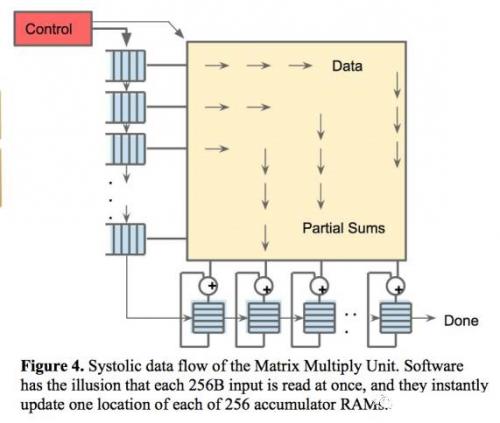
第二个创新是Systolic(脉动式)数据流。在矩阵乘法和卷积运算中,许多数据是可以复用的,同一个数据需要和许多不同的权重相乘并累加以获得最后结果。因此,在不同的时刻,数据输入中往往只有一两个新数据需要从外面取,其他的数据只是上一个时刻数据的移位。在这种情况下,把片上内存的数据全部Flush再去去新的数据无疑是非常低效的。根据这个计算特性,TPU加入了脉动式数据流的支持,每个时钟周期数据移位,并取回一个新数据。这样做可以最大化数据复用,并减小内存访问次数,在降低内存带宽压力的同时也减小了内存访问的能量消耗。
第三个创新是低精度(8-bit)计算。使用低精度而非32位全精度浮点数做计算已经成为深度学习界的共识,研究结果表明低精度运算带来的算法准确率损失很小,但是在硬件实现上却可以带来巨大的便利,包括功耗更低速度更快占芯片面积更小的运算单元,更小的内存带宽需求等。在今年ISSCC的深度学习处理器session中,几乎所有的论文都使用了低精度运算(8-bit甚至4-bit),可见未来硬件使用低精度运算已成趋势,这次Google公布TPU也使用了8-bit也在意料之中。
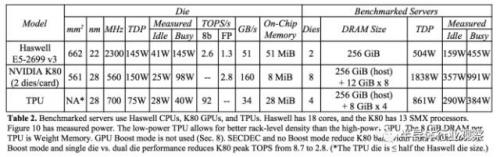
TPU显示出了非常强的深度学习加速能力。TPU的平均性能可以达到CPU和GPU的15到30倍,能效比则有30到80倍的提升。如果使用GPU的DDR5而不是目前的DDR3内存接口,TPU的性能甚至还可以再提升数倍。
深度学习硬件市场预测
在Google公布的TPU设计可谓是给深度学习ASIC打了一针鸡血,之后预计会有众多挑战TPU的ASIC出现,各大公司和初创团队都会把TPU当作自己挑战的目标,深度学习加速硬件也会得到更多关注。Nvidia仍然会坚持GPU架构,但是预计会在GPU中借鉴和融合深度学习加速器的部分设计,以加速深度学习运算。Intel的Xeon+FPGA架构会使用收购得到的Nervana的设计IP,预计也会在深度学习上获得不少加速。这些都是主要针对服务器端的深度学习加速硬件,而在移动端如何设计深度学习加速硬件仍然还没有太多线索,也有许多工程师在探索这个问题。另一个不可小觑的是FPGA,因为在云端服务中心可快速重配置的FPGA可以实现快速服务切换,从而实现云计算中许多实际的服务问题。
更多最新行业资讯,欢迎点击《今日大事要闻》!
- 光伏技术“质变期”是否已经到来?(01-11)
- 新能源的崛起,汽车/轮船/飞机迎接纯电时代(10-03)
- 西门子收购Tass,Tass 到底强在哪里?(08-04)
- 这三个创业者为什么能得到联发科的垂青(10-04)
- 要拿下自动驾驶市场的10亿美元订单,英伟达(NVIDIA)好大口气(03-01)
- 在每一个ADAS节点上采用恩智浦的硅芯片,恩智浦展示完整的自动驾驶车辆平台(04-17)