突破深度学习硬件瓶颈,谷歌TPU创新性在哪?
深度学习在这两年如日中天,使用深度学习来做自动驾驶、金融服务、安全防卫等等业务的公司如雨后春笋般纷纷冒出。Google一向是深度学习的领军者,在四年前就已经意识到了深度学习算法的重要性,早早就把深度学习应用在搜索、广告、垃圾邮件识别、图片人脸识别的业务上,还推出了TensorFlow的机器学习架构,去年更是率AlphaGO战胜世界围棋第一人李世石,成为深度学习人工智能的标志性事件。
除了软件算法领先之外,Google在深度学习的硬件研发上也占了先机。去年年中,Google推出了第一款得到大规模使用的专用深度学习加速芯片Tensor Processing Unit (TPU),据称比GPU领先许多。TPU推出后很久,内部架构一直不为人知,直到昨天Google正式公布了介绍TPU的论文,让我们得以一窥究竟。
深度学习的硬件执行瓶颈
大约五年前,人们在跑机器学习算法时用的主要还是CPU,因为CPU通用性好,编程模型很成熟,对于程序员来说非常友好。然而,当机器学习算法的运算量越来越大时,人们发现CPU执行机器学习的效率并不高。CPU为了满足通用性,芯片面积有很大一部分都用于复杂的控制流,留给运算单元的面积并不多。而且,机器学习算法(尤其是机器视觉卷积神经网络算法)中运算量最大的运算是一种张量(Tensor)运算,而CPU对于矢量运算也只能说是部分支持,更不用说张量运算。这时候,GPU进入了机器学习研究者的视野。GPU原本的目的是图像渲染,因此使用完美支持矢量运算的SIMD(单指令流多数据流,single instruction multiple data)架构,而这个架构正好能用在机器学习算法上。另外,GPU中控制比较简单,绝大部分芯片面积都用在了计算单元上,因此计算能力也比CPU要强一到两个数量级。
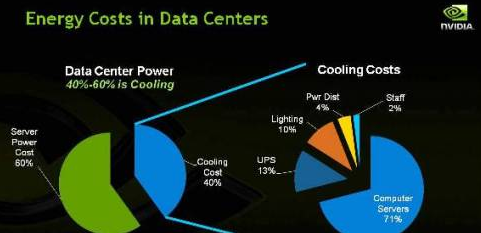
GPU运行机器学习算法比CPU快很多,但是毕竟不是为机器学习而设计的。主要问题就是,GPU使用多线程(SIMT)的架构去遮盖内存访问延迟,因此片上内存容量不大。一方面,深度学习加速硬件的主要能量消耗其实就在于内存访问,因此GPU的SIMT架构虽然能遮盖内存访问实现高吞吐量,但是能效比(即执行完单位运算需要的能量)并不好。但是,目前能效比正在成为越来越重要的指标。对于移动应用,能效比不好意味着电池很快就会被用完,影响人工智能的普及;对于云端数据中心应用,能效比不好则意味着数据中心需要在散热投入许多钱,而目前散热已经成为数据中心最大的开销之一。另一方面,GPU关注的是吞吐量,而非处理延迟,然而在许多应用中,尤其是人工网络做推断运算时,处理延迟事实上比吞吐量更重要。例如,在自动驾驶应用中,几十毫秒的处理延迟就可能意味着是否会出事故。在此类应用中,GPU并非最佳选择。
显然,为深度学习专门开发电路能实现最佳的效率。然而,一般公司很难承担为深度学习开发专门处理器ASIC芯片的成本和风险。首先为了性能必须使用最好的半导体制造工艺,而现在用最新的工艺制造芯片一次性成本就要几百万美元,非常贵。就算有钱,还需要拉一支队伍从头开始设计,设计时间往往要到一年以上,time to market时间太长,风险很大。
大多数公司,例如Amazon,Microsoft等等选择了更灵活的FPGA方案,在FPGA可以快速实现为机器学习算法开发的处理器架构,而且成本较低(一块FPGA开发板大约售价1000美金,比真的制造芯片便宜太多)。但是FPGA为了可配置性,其性能比起ASIC来说要弱不少,所以在架构设计接近的情况下,FPGA的性能会比ASIC差5-10倍。就在大家还在要不要上ASIC的时候,Google闷声不响开始了深度学习加速器芯片的开发,并于去年发布了TPU。昨天,Google更是公开了关于TPU架构设计的论文《In-Datacenter Performance Analysis of a Tensor Processing Unit》。下面让我们具体分析一下论文中到底讲了什么。
TPU的创新性

TPU的架构如上图所示。TPU的架构看上去很简单,主要模块包括片上内存,256x256个矩阵乘法单元,非线性神经元计算单元(activation),以及用于归一化和池化的计算单元。
事实上,TPU的微架构确实也并不复杂。TPU的主旨是让它的256x256个矩阵乘法单元尽可能处于工作状态,减少运算闲置。基于这个简洁的设计哲学,TPU就能实现相当高的计算效率。TPU甚至没有取命令的动作,而是主处理器提供给它当前的指令,而TPU根据目前的指令做相应操作(这与CPU,GPU都完全不同)。从论文里披露的细节来看,TPU的主要创新在于三点,即大规模片上内存,脉动式内存访问以及8位低精度运算。
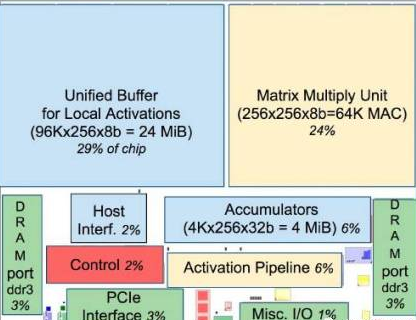
TPU在芯片上使用了高达24MB的局部内存,6MB的累加器内
- 光伏技术“质变期”是否已经到来?(01-11)
- 新能源的崛起,汽车/轮船/飞机迎接纯电时代(10-03)
- 西门子收购Tass,Tass 到底强在哪里?(08-04)
- 这三个创业者为什么能得到联发科的垂青(10-04)
- 要拿下自动驾驶市场的10亿美元订单,英伟达(NVIDIA)好大口气(03-01)
- 在每一个ADAS节点上采用恩智浦的硅芯片,恩智浦展示完整的自动驾驶车辆平台(04-17)