DC中还有什么办法可以用来优化时序
尝试了几次compile和compile_ultra 找到最佳结果,也用上了useful skew,看了下时序违例路径,也都换成了LVT cell了;size cell试了几次不太理想,应该是工具给做到最优结果了对于size cell;但时序还有有较大的违例,约束设置的也不是很严格;请问还有什么办法在DC中进行优化时序?
path_group , critical_range吧,
找后端也聊聊
这个也用过了,还有compile_ultra中的-retime也用过了;还是修不下去;采用的是dct flow,感觉DC中可以用来优化时序的操作不是很多啊;不知道在DC中该怎么才能使time clean
所以找后端聊聊啊,集思广益么
前后端都我一个人 小编。
小编,对于这种情况,还有什么办法来优化
group_path的用法很灵活,你是怎么设置的?
DCT Flow不是DC到ICC后再到DC的,这样的流程应该时序会变好一些了。
说说具体的,别太笼统,
工艺,频率,目标signoff目标, 具体path发个example
group_path -name reg2reg -weight 10 -critiacal 1.0
我就是这样做的
90nm工艺,周期8ns,signoff setup目标100ps;这是最差路径
****************************************
Report : timing
-path full
-delay max
-input_pins
-nets
-group clk
-max_paths 1
-transition_time
Design : xxxxxx
Version: H-2013.03-SP1
Date: xxxxxxxxxxxxxxx
****************************************
* Some/all delay information is back-annotated.
# A fanout number of 1000 was used for high fanout net computations.
Operating Conditions: WORSTLibrary: xxxxxxxxxxxxxxx
Wire Load Model Mode: Inactive.
Startpoint: cmem0_idata0_2_x0_t0
(rising edge-triggered flip-flop clocked by clk)
Endpoint: p0_iu0/r_reg_X__DATA__0__1_
(rising edge-triggered flip-flop clocked by clk)
Path Group: reg2reg
Path Type: max
PointFanoutTransIncrPath
------------------------------------------------------------------------------------
clock clk (rise edge)0.00000.0000
clock network delay (ideal)0.00000.0000
cmem0_idata0_2_x0_t0/CE (SRAM32x256_1rw)0.30000.0000 #0.0000 r
cmem0_idata0_2_x0_t0/O[25] (SRAM32x256_1rw)0.43997.22807.2280 r
p0_ico_DATA__2__25_ (net)20.00007.2280 r
U7839/IN1 (NAND2X4_LVT)0.43990.0031 *7.2312 r
U7839/QN (NAND2X4_LVT)0.22590.10007.3312 f
n6244 (net)10.00007.3312 f
U10454/IN4 (NAND4X0_LVT)0.22590.0026 *7.3338 f
U10454/QN (NAND4X0_LVT)0.20630.11777.4515 r
n12688 (net)10.00007.4515 r
U12995/INP (NBUFFX2_LVT)0.20630.0000 *7.4515 r
U12995/Z (NBUFFX2_LVT)0.22240.16817.6197 r
n6253 (net)10.00007.6197 r
U6160/IN1 (NOR2X4_LVT)0.22240.0057 *7.6254 r
U6160/QN (NOR2X4_LVT)0.19820.10847.7338 f
p0_ico_DIAGDATA__25_ (net)10.00007.7338 f
U6163/INP (INVX8)0.19820.0064 *7.7401 f
U6163/ZN (INVX8)0.09130.04767.7877 r
n12470 (net)10.00007.7877 r
p0_c0mmu_dcache0/ico_DIAGDATA__25_ (mmu_dcache_dsu1_drepl0_dsets2_dlinesize8_dsetsize1_dsetlock1_dsnoop6_itlbnum8_dtlbnum8_tlb_type2_memtech34_cached0)
0.00007.7877 r
p0_c0mmu_dcache0/ico_DIAGDATA__25_ (net)0.00007.7877 r
p0_c0mmu_dcache0/U3120/IN1 (NAND2X4)0.09130.0015 *7.7892 r
p0_c0mmu_dcache0/U3120/QN (NAND2X4)0.13960.03597.8250 f
p0_c0mmu_dcache0/n2195 (net)10.00007.8250 f
p0_c0mmu_dcache0/U3795/IN1 (NAND4X0_LVT)0.13960.0000 *7.8251 f
p0_c0mmu_dcache0/U3795/QN (NAND4X0_LVT)0.23300.07517.9001 r
p0_c0mmu_dcache0/n2196 (net)10.00007.9001 r
p0_c0mmu_dcache0/U3796/IN1 (MUX21X2_LVT)0.23300.0000 *7.9002 r
p0_c0mmu_dcache0/U3796/Q (MUX21X2_LVT)0.21360.22228.1224 r
p0_c0mmu_dcache0/dco_DATA__0__25_ (net)20.00008.1224 r
p0_c0mmu_dcache0/dco_DATA__0__25_ (mmu_dcache_dsu1_drepl0_dsets2_dlinesize8_dsetsize1_dsetlock1_dsnoop6_itlbnum8_dtlbnum8_tlb_type2_memtech34_cached0)
0.00008.1224 r
p0_dco_DATA__0__25_ (net)0.00008.1224 r
p0_iu0/dco_DATA__0__25_ (iu3_nwin8_isets4_dsets2_fpu0_v850_cp0_mac0_dsu1_nwp2_pclow2_notag0_index0_lddel1_irfwt0_disas1_tbuf1_pwd2_svt0_rstaddr0_smp3_fabtech34_clk2x0)
0.00008.1224 r
p0_iu0/dco_DATA__0__25_ (net)0.00008.1224 r
p0_iu0/U8838/IN1 (MUX21X1_LVT)0.21360.0022 *8.1246 r
p0_iu0/U8838/Q (MUX21X1_LVT)0.15350.17898.3034 r
p0_iu0/n5156 (net)20.00008.3034 r
p0_iu0/U4733/IN1 (NAND2X2)0.15350.0003 *8.3037 r
p0_iu0/U4733/QN (NAND2X2)0.09570.05198.3556 f
p0_iu0/n5157 (net)10.00008.3556 f
p0_iu0/U482/IN1 (NAND2X2_LVT)0.09570.0000 *8.3556 f
p0_iu0/U482/QN (NAND2X2_LVT)0.09250.04068.3962 r
p0_iu0/n9627 (net)10.00008.3962 r
p0_iu0/U7003/IN2 (NOR2X2_LVT)0.09250.0000 *8.3962 r
p0_iu0/U7003/QN (NOR2X2_LVT)0.09450.05068.4468 f
p0_iu0/n9503 (net)10.00008.4468 f
p0_iu0/U6986/IN1 (NOR2X1_LVT)0.09450.0001 *8.4469 f
p0_iu0/U6986/QN (NOR2X1_LVT)0.08950.04258.4894 r
p0_iu0/n740 (net)10.00008.4894 r
p0_iu0/r_reg_X__DATA__0__1_/D (SDFFX2_LVT)0.08950.0000 *8.4894 r
data arrival time8.4894
clock clk (rise edge)8.00008.0000
clock network delay (ideal)0.00008.0000
clock uncertainty-0.25007.7500
p0_iu0/r_reg_X__DATA__0__1_/CLK (SDFFX2_LVT)0.00007.7500 r
library setup time-0.17937.5707
data required time7.5707
------------------------------------------------------------------------------------
data required time7.5707
data arrival time-8.4894
------------------------------------------------------------------------------------
slack (VIOLATED)-0.9187
1
你就设这么一句,作用是微乎其微的,有没有反效果都不好说。
小编 我把路径贴上上去了,工艺什么的也说了 ,您帮忙看看怎么回事
周期一共才8ns,光一个SRAM就占了7.228ns,似乎DC也不好办啊。要不换个SRAM?
sram出来的path最好修了,在后端useful skew调整下就好了
dc没什么优化的空间了,都是combo cell,连个buffer都没有,

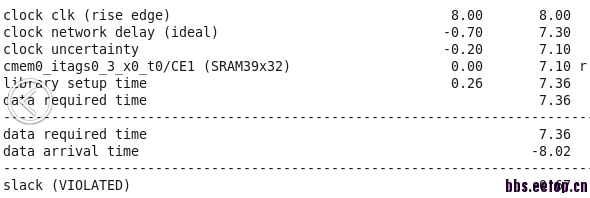
我已经用过useful skew了 小编;而且对于这种 launch cell和capture cell是同一个的sram怎么解决呢
这种path设计有问题吧, sram出来经过logic又回到自己,bist相关么?
贴个全的path看看
时钟8ns,sram占用了7.2 , 如果不降频 ,肯定只能调usifulskew,dc已经没法再给你优化了,如果这些sram不多,还是有希望调好的。
可以通过 group-ungroup -retime timing 等方法,实在不行就用pipeline