请教一个关于srio gen2的问题
1. 这个核中的maintenance port 和I/O port 之间到底有什么关系?
2. 这个程序中发送数据的帧头中都带有地址,这个地址该怎样理解?
希望能够有个简单明了的回答帮我梳理一下思路,谢谢了
求别沉
来个大神指导一下我把
ISE支持7系列的芯片吗?
ISE最高支持到7系列。
maintenance port可单独拿出来,用于进行maintenance read和maintenance write,主要用于读写对方的寄存器。
地址就是表示对方作为一个存储器的地址。FPGA如果向6678用NWrite写数据,这个地址就是6678的存储器地址。
感谢感谢,那这么说的话I/O port和 maintenance port 是两个互相独立的port了。IO port和 maintenance port 中的地址是同样的意思对吗?
那么如果我想进行读写操作,用这两个里面任意的一个都可以实现对吗?
当我用maintenance port 时候就不用 I/O port,用I/O port时候就不用maintenance port。这个理解对吗?
别沉别沉
还望各位大神不吝赐教
帖子别沉啊。关于这个接口,我在论坛里提问了好多,但是没有人解答。我觉得会应用就好了。我自己认为,直接用I/O port就行了,会写简单的NWRITE 或者SWRITE,再加一个MESSAGE就可以了。学的话,个人认为就写一个NWRITE实现通信就好了,之后才会有信心,个人写过这个简单的控制程序,在论坛里,但是显然没有成功,我也不知道原因。我总是想从最简单的应用开始学起,之后再深入,可是example design,恕我直言太复杂了,简直是保罗万象,数据手册也看了,然而还是不懂,总是隔着层什么。总感觉太抽象了,你给个简单的例子不行吗?它成了我心中永远的痛,从此之后我日渐消沉。
所以说,我希望大神留步,具体的讲一讲。下面说一说我的看法,直接例化这个ip核之后,肯定会有一个时钟管理单元,因为是高速接口的原因。所以我们加一个时钟,弄个rst_n之类。我们这里只讨论发送吧,而且只讨论NWRITE格式,按理说,直接在时钟的驱动下,加上符合NWRITE格式的并行数据给这个接口就行了,就发送出去了呀。但是好像不行,接受端也要有这个模块来接收,两者建立起链路才可以。我感觉这个链路是关键,也很神奇,我一直不清楚怎么个建立法,建立后,不发数据,链路还在吗?不发数据二者能建立链路吗?发送接收不是用共同的时钟同步吗?这个机制真是不清楚呢,这是极其关键的内容。
所以请求大神收下我的膝盖,给普及一下链路是怎么建立的,最好是用具体的模块的简单的方式阐述一下NWRITE这一个简单的操作。
致SRIO,我心中永远的痛。
大神,能说说这个message是个什么东西吗?还有就是maintenance port 和 IO port比哪个更好用一些呢?
我也觉得给的列子太复杂,可能自己水平地,我也没看懂
感觉能做成ram那么简单的接口,就好了,有时候就需要一些简单的 NWRITE的tran rec
message
我是在看资料的时候看到的。是一个简单的验证实验。在发送端发送10个NWRITE数据帧(每帧256字节)后,跟随一个MESSAGE帧,在接收端每检测到一个message帧,就连续读特定地址10次,每次256字节。类似于是中断的概念。有时间的话可以再仿真一把,不知道没有license 是否
会影响仿真。就在一片FPGA中,调用两次这个ip核,一个做发送,一个做接收,看看能不能建立起链接。
我想问一下这个地址的问题。在HELLO format下。帧头的后34位都表示地址。这每个地址能保存多少位数据啊。
在例程的仿真中完全没有弄明白这个地址是在怎么变化的。就好比每次写256个数据,那么第一个和第二个帧头处的这个地址应该怎么写呢?还有就是SWRITE和NWRITE之间有什么区别?
关于这个核,我最不明白的就是帧头处所给的地址。每个地址到底能存多大的数据量,还有就是给地址时候有什么规律吗?
别沉别沉
求大家不吝赐教啊
SRIO协议说了,每个端点设备的本地寄存器(协议定义了各层的寄存器,有些设备有扩充,比如交换芯片,或者有些特性没有实现等)是映射到地址空间的,缺省的情况下,高位地址是全1(Xilinx的IP中可以配置)。当然已知具体映射的情况下,可以用普通的NRead读寄存器。如果不知道,或者准备修改映射地址,就要用Maintanance Port来读写。
使用Xilinx的IP的话,有AXI-Lite端口,可以直接读写本地或远端设备的寄存器(主要是设好hop count)。
一片的话,也应该要GTX在外部互联才行吧。
如果使用34位地址,就是对应那么大空间。至于怎么用,用户自己决定,除了寄存器占用了一部分。
谢谢了不过在FPGA向DSP传输数据的时候,发完帧头之后开始发送需要传输的数据,只要DSP那边接到了这些数据不就可以了。在帧头处的这个地址并没有起到什么作用啊。就向调用GTX时候,收端只要rx_data就可以了吧。
是不是说这些地址是在执行读操作时候可以指定要读的存储器地址。那么在写操作时,这个地址的是指定写的地址吗?看程序中给人的感觉是数据直接到了收端啊,按照正常的操作,我在后面接一个FIFO把数据缓存下来不就OK了。不太明白在写操作时帧头的地址起到了一个什么样的作用
别沉啊
求助各路大神
非常感谢,小编的
7777777777777777777
NWRITE 和SWRITE的区别。还真是把人问倒了。
NWRITE: 普通写操作。可以直接往对端内存写数。一个包最大为256bytes,不要求接收端响应。
SWRITE:流写(Stream Write),数据长度必须是8字节的整数倍,不要求接收端响应。
我这里就感觉只有数据量大小的问题。
另外我有问题向你们请教:假设发送数据好了,用hello format,nwrite的方式,首先给s_axis_ireq_tdata引线一个64位的包头,然后开始发送64位的数据,在NWRITE的模式下,我认为,这个64位的数据可以被屏蔽掉一部分,但是要是swrite的话就不能屏蔽。我知道这样理解对不对。
还有所说的地址问题,包头中包含着写地址,接收端就按照地址,后面的接收端我感觉不太清楚。还有就是源地址,和目标地址怎么体现,完整具体的流程谁给讲一讲。
FPGA向DSP发起NRead和NWrite,这个地址是指的DSP的地址。DSP收到NWrite报文,会把数据写入自己的存储器对应地址的地方。NRead类似。
如果一个FPGA作为EP,收到NWrite后,怎么解释这个地址,随便。
好的
万分感谢!
我自己写个简单的发送程序去上板试试
小编。关于链路的链接应该怎样理解。还有就是NWRITE还有SWRITE的区别,只用一个ip核能否做自环测试。
小编,你的实验成功了吗?我想参考一下您的FPGA端使用srio发送数据的代码。我自己尝试写过,但是仿真不出来。邮箱:shijiefei2012@163.com
如果您觉得技术敏感,我希望您给讲一讲思路,用fpga发送数据的思路,需要注意的地方。
期待您的回复。
我写的fpga端的发送程序: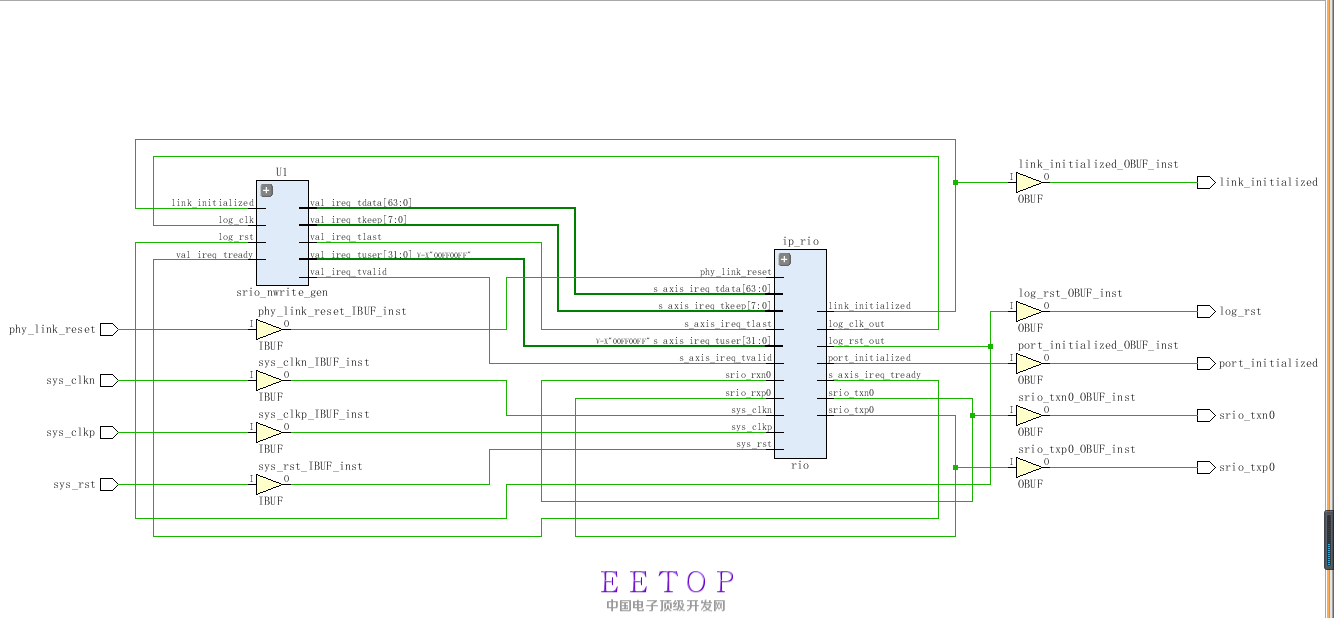
程序如下:很简单,共3个文件,包含了激励文件。我的打算就是用单个ip核,自己发送自己接收,仿真正在进行,非常慢,一会了,还没出现显示波形的界面,希望大家看看,我的思路是否有错,哪里有错大家批评指正,没有人交流太痛苦。
第一个模块:NWRITE数据产生模块
`timescale 1ns / 1ps
//////////////////////////////////////////////////////////////////////////////////
module srio_nwrite_gen(
input log_clk,
input log_rst,
input val_ireq_tready,
input link_initialized,
output reg val_ireq_tvalid,
output reg val_ireq_tlast,
output reg [7:0] val_ireq_tkeep,
output reg [63:0] val_ireq_tdata,
output [31:0] val_ireq_tuser
);
localparam [7:0] src_id=8'hff;
localparam [7:0] dest_id=8'hff;
localparam [3:0] NWRITE=4'd5;
localparam [3:0] TNWR =4'd4;
localparam [64*5-1:0] nwrite_instruction = {
// NWRITEs
{8'h66, NWRITE, TNWR,1'b0,2'b00,1'b0,8'h17,2'b00, 34'h300000000},
{64'h0000000000000000},
{64'h0000000000000001},
{64'h0000000000000002},
{64'h0000000000000003}};
wire [63:0] instruction[0:4];
genvar ii;
generate
for (ii = 0; ii <5; ii = ii + 1) begin : instruction_gen
assign instruction[ii] = nwrite_instruction[(ii+1)*64-1:ii*64];
end
endgenerate
reg [4:0] i;
//reg val_ireq_tlast;
always @(posedge log_clk or posedge log_rst)
if(log_rst)
begin
val_ireq_tvalid<=1'b0;
val_ireq_tdata<=64'd0;
val_ireq_tlast<=1'b0;
i<=4'd0;
end
else
begin
if(val_ireq_tready&&link_initialized)
begin
case(i)
0:
begin
val_ireq_tvalid<=1'b1;
val_ireq_tdata<=instruction[0];
val_ireq_tlast<=1'b0;
val_ireq_tkeep<=8'hff;
i<=i+1'b1;
end
1,2,3:
begin
val_ireq_tvalid<=1'b1;
val_ireq_tdata<=instruction;;
val_ireq_tlast<=1'b0;
i<=i+1'b1;
end
4:
begin
val_ireq_tvalid<=1'b1;
val_ireq_tdata<=instruction;
val_ireq_tkeep<=8'hff;
val_ireq_tlast<=1'b1;
i<=i+1'b1;
end
5:
begin
val_ireq_tlast<=1'b0;
i<=i+1'b1;
end
default:
begin
val_ireq_tvalid<=1'b0;
val_ireq_tdata<=64'd0;
val_ireq_tlast<=1'b0;
end
endcase
end
else
begin
val_ireq_tvalid<=1'b0;
val_ireq_tdata<=64'd0;
val_ireq_tlast<=1'b0;
end
end
assign val_ireq_tuser = {8'h0,src_id,8'h0, dest_id};
endmodule
第二个:第一个模块和ip核的连线
module top(
input sys_rst,
input sys_clkn,
input sys_clkp,
input phy_link_reset,
output link_initialized,
output port_initialized,
output log_rst,
output srio_txn0,
output srio_txp0
);
//wire log_rst;
wire [7:0] val_ireq_tkeep;
wire [31:0] val_ireq_tuser;
wire [63:0] val_ireq_tdata;
wire val_ireq_tvalid;
wire log_clk_out;
wire val_ireq_tready;
wire val_ireq_tlast;
srio_nwrite_gen U1(
.log_clk(log_clk_out),
.log_rst(log_rst),
.link_initialized(link_initialized),
.val_ireq_tlast(val_ireq_tlast),
.val_ireq_tvalid(val_ireq_tvalid),
.val_ireq_tkeep(val_ireq_tkeep),
.val_ireq_tuser(val_ireq_tuser),
.val_ireq_tready(val_ireq_tready),
.val_ireq_tdata(val_ireq_tdata)
);
//wire srio_txn0;
//wire srio_txp0;
rio ip_rio(
.log_clk_out(log_clk_out),
.log_rst_out(log_rst),
.s_axis_ireq_tdata(val_ireq_tdata),
.s_axis_ireq_tkeep(val_ireq_tkeep),
.s_axis_ireq_tvalid(val_ireq_tvalid),
.s_axis_ireq_tuser(val_ireq_tuser),
.s_axis_ireq_tready(val_ireq_tready),
.s_axis_ireq_tlast(val_ireq_tlast),
.link_initialized(link_initialized),
.port_initialized(port_initialized),
.phy_link_reset(phy_link_reset),
.srio_txn0(srio_txn0),
.srio_txp0(srio_txp0),
.srio_rxn0(srio_txn0),
.srio_rxp0(srio_txp0),
.sys_clkn(sys_clkn),
.sys_clkp(sys_clkp),
.sys_rst(sys_rst)
);
//rio ip_rio_rx(
// .log_clk_out(log_clk_out),
//// .s_axis_ireq_tdata(val_ireq_tdata),
//// .s_axis_ireq_tkeep(val_ireq_tkeep),
//// .s_axis_ireq_tvalid(val_ireq_tvalid),
//// .s_axis_ireq_tuser(val_ireq_tuser),
//// .s_axis_ireq_tready(val_ireq_tready),
//// .s_axis_ireq_tlast(val_ireq_tlast),
// .link_initialized(link_initialized),
// .port_initialized(port_initialized),
// .phy_link_reset(phy_link_reset),
//// .srio_txn0(srio_txn0),
//// .srio_txp0(srio_txp0),
// .srio_rxn0(srio_txn0),
// .srio_rxp0(srio_txp0),
// .sys_clkn(sys_clkn),
// .sys_clkp(sys_clkp),
// .sys_rst(sys_rst)
//);
endmodule
第三:激励文件
module sim(
input log_rst,
input sys_rst,
input phy_link_reset,
input sys_clkn,
input sys_clkp,
output link_initialized,
output port_initialized,
output srio_txn0,
output srio_txp0
);
top sim_top(
// .log_rst(log_rst),
.sys_rst(sys_rst),
.phy_link_reset(phy_link_reset),
.sys_clkn(sys_clkn),
.sys_clkp(sys_clkp),
.port_initialized(port_initialized),
.link_initialized(link_initialized),
.srio_txn0(srio_txn0),
.srio_txp0(srio_txp0)
);
reg sys_clkp_reg;
initial begin
sys_clkp_reg = 1'b0;
forever #40 sys_clkp_reg = ~sys_clkp_reg;
end
assign sys_clkn = ~sys_clkp_reg;
assign sys_clkp=sys_clkp_reg;
//initial begin
// system_rst_reg=1;b1;
// #2000
// system_rst_reg=1'b0;
//end
// reset generator
reg phy_link_reset_reg;
// reg log_rst_reg;
// initial begin
// log_rst_reg = 1'b1;
////// phy_link_reset_reg=1'b1;
// #1000
// log_rst_reg = 1'b0;
////// phy_link_reset_reg=1'b0;
// end
initial begin
// log_rst_reg = 1'b1;
phy_link_reset_reg=1'b1;
#1000
// log_rst_reg = 1'b0;
phy_link_reset_reg=1'b0;
end
reg sys_rst_reg;
initial begin
sys_rst_reg=1'b1;
#2000
sys_rst_reg=1'b0;
end
// assign log_rst=log_rst_reg;
assign phy_link_reset=phy_link_reset_reg;
assign sys_rst=sys_rst_reg;
endmodule