基于AXI4总线接口的MIG(挂DDR3)讨论
于是乎,小弟就开始玩命的干活了(摸的办法,谁让是打工仔呢)。首先,我先搞了一个MIG核进入我的工程,然后我打开了example design进行了研读。我的妈呀,通过参考ug586文档,苦逼的读程序。结果吧,搞出来了一个整体设计方案,其实就是我要把traffic gen 改成自己想要实现的功能就行。不过我面对的接口是AXI4_wrapper文件。这时候,尼玛,搞的有点晕了,遇到了点问题,总结如下:
1.大家搞过ddr条子都知道,比如说我的4G的DDR3,位宽为64,地址位=rank+bank+col+row=29.尼玛,这就是说我的地址宽度如果是29就好了。可是这里我对着axi4总线设置地址宽度时出现了点问题,就是,尼玛选择的是32位宽的。那这两边怎么统一啊。然道mig 偷偷的帮我把活干完了,我直接睡觉就好了?!感觉,不可能啊!所以,求路过的大侠大哥大嫂们指点一二!跪拜ing!
再进一步,发现axi4总线地址算法会根据选择的模式算法有所不同。这样问题出来了:mig它说使用了AIX那个接口了吗?是AXI4,还是AXI-lite,还是axi4-stream?搞不懂,求讨论,求指导!
2,好家伙,搞不懂地址这边,那尼玛数据这边总可以吧。经过小弟的巴拉巴拉的啃代码,发现这里要基于一个原则:ddr3条子的内外位宽一样就行了。比如说我设置的控制:ddr的时钟频率比为:1:4.我条子burst length=8。那就是说(dq_width=64)8*64*1=512bit.那mig 那边也一此要过来512吧。而aix4过来的数据又是32位的宽度,尼玛我又蒙了。感觉我可以设置axi的一次burst发出的数据量也等于512.不知道这么理解行不行,求讨论,拍砖,也可以!
3.example design里的文件axi_wrapper.v真的是axi4总线的描述吗,我怎么觉得惶惶的呢,读了程序,感觉倒是像那么回事。可是,咳,求证实!
小弟发此贴,抛砖引玉,求各位在此讨论一二,大家有机会一起想想,如果能共同进步就更好了!
自己先顶一个!求不沉! 如果嫌表述不!够完整,可以说,必定详细描述
个人见解,axi总线挂ddr3,适合计算机总线架构,就是用处理器来操作,不太适合逻辑自己操作。对于那种高速采集系统,我宁愿自己写更高效的仲裁器,axi如果要做内存地址map,时序开销有点大
你先要搞清楚axi4是什么,是ARM的计算机内部总线,如果不做成SOC的架构(有处理器和复杂总线桥),真看不出axi有什么优势,那种先给地址再给数据的axi_lite,效率完全不如地址数据同时给的intel总线,我是这么认为。
个人见解,axi总线挂ddr3,适合计算机总线架构,就是用处理器来操作,不太适合逻辑自己操作。对于那种高速采集系统,我宁愿自己写更高效的仲裁器,axi如果要做内存地址map,时序开销有点大
谢谢您的回复。我再好好想想!
首先,谢谢大侠的回复。我确实对AXI总线了解不深。在我看资料后的总体感觉是:它是SOC系统中各个ip之间互联的一种总线协议,这样我们今后的设计活动中,只要掌握一种总线就可以了。当然,这些都是虚话。具体到我的fifo设计里,我这样理解的:
1.我其实想使用两个ip 核(mig+axi接口)来连接两个ddr3.一片读,一片写,设计成乒乓操作。因为ddr3在读或者只写的情况下,效率很高。这时候我需要通过axi接口传数据,其中我了解到我可以使用axi-steram总线的方法来提高我的传输能力(因为它只需要给出数据就行,不用地址)。
2.如果可以成功使用了axi总线,那么我们今后的项目可以直接方便的使用axi总线,项目的兼容性和继承性方面可能会更加好;
3.实际上,我个人感觉,老板让我干这个,可能是想尝试一下这个总线到底怎么样!
再次感谢您的回复,我明天将和老板谈一谈,到时候,肯定会有一些疑问,还望大侠多多赐教!
那个大侠,能告诉我,MIG 核上进行customize的时候选择的AXI Interface具体是什么类型的总线?是AXI4,axi4-lite,还是AXI4-steam。偷个懒,明天看完程序,再过来和你们对比下我的分析对不对!
有谁知道AXI4-stream相关的ip核怎么用吗?比如说axi4-stream date mover等等,如果我要拿axi4-stream 来用,它能和mig结合在一起吗(貌似mig上的接口是不是axi4-stream)
这个IP很烦,没有用户读写接口
但是模块化是优势,适合Master读写
不错哦 学习学习 哈哈
我不是大侠哈,也是菜鸟入行2年而已。推一种总线,在某些方面确实有接口继承的好处,但是里面的商业因素也不言而喻。而且xilinx这种强推axi的做法,我也不喜欢,现在它自己的不少大型ip core的axi接口,到了里面都是转了一层自己的接口协议,基本等于挂羊头卖狗肉,比如PCIe这些core,谁都不会觉得它的axis接口有什么好处,但是如果你用它的ARM核Zynq SOC,那axi就显得比较有优势了。FPGA这两年发展不太好,xilinx的产品是不停更新,都没能在民用消费市场有所作为,新花样是一出接一出,反正你做系统按照你自己的逻辑设计做就是了,怎么样设计有优势,就怎么做。
谢谢大侠的回复,今天开始把协议拿出了具体看了下,目前正在分析axi4,axi4-lite,axi4-stream 的区别,以及是否能够把axi4-stream 和mig接口上的axi4连接起来。你说的行业趋势和这个总线的实质我也表示赞同,不过有时候身不由己,必须做出来才能和老板说它到底行不行!我个人目前确实只是了解了点皮毛,正下决心这两天好好啃啃!希望大侠有空指点一下我即将发的学习笔记。
先点个赞! 一起学习! 大家都是身不由己,你为学位,我为钱,哈哈~
经过这两天的学习,目前初步形成了设计方案。大概思路是这样的:我的需求是高速乒乓缓存,那么我对数据带宽的要求肯定很大。因此,mig自带的axi4接口肯定不能满足要求。这时候肯定是要我使用axi4-stream接口的。那么两者之间肯定是需要桥接的。这时候经过分析,觉得axi-dma 是可以满足要求的。为此,我去大概看下axi-dma 的数据手册[img][/img],根据它的给出的关于以太网数据高速缓存的方案,我形成了自己的初步的设计方案。大概是,dma面向axi4-stream部分是可以在端口方面衔接的很好的。不过,因为这个设计方案中dma 的寄存器设置,中断控制都需要的arm处理器。而我的v7里面显然没有这东西。因为好像自己得编写控制器(好像略坑)。此外,lite其实和axi4之间其实是可以兼容的,这种兼容是充分的!目前,还在思考这个方案的可行性!如果大家有什么想法,或者说大家一起使用去其它带有axi4接口的ip 的工程项目时候,可以进来一起指点下!
我前一段时间刚搞过,试着说一下。
1. IP生成的AXI4接口就是memory-mapped类型的接口,包括读操作接口和写操作接口,这个你读一下相关协议就会操作;
2. 生产IP时AXI4接口数据位宽一般会根据你的ddr位宽和选的1:4时钟自动选择,也可以根据需要手动选择;
3. AXI4接口地址位宽一般是32位,ddr地址只有29位的话,只需要用低29位就行,高位填0;
其实用AXI4接口是比较简单的,你只需要自己写ddr读写控制模块,不需要关心读写请求的仲裁处理。
谢谢你的回复,一开始我使用的也是你的思路。不知道你这么做后数据率能达到多少?请告诉我一下行吗?因为我现在项目对数据带宽的要求比较大,所以现在改思路了,准备使用axi4-stream。目前方案还在论证,有了
结果大家再讨论啊!
其实主要就是为了模块化方面。你知道,生成带有axi4接口的mig的时候,理论上,接下来自己按照协议的要求写master部分就可以了。但是在使用example_design 学习的时候发现了个axi4_wrapper程序,它对外提供两个端口,对mig 部分好像提供的axi4协议的接口。我想问问,是不是这个wrapper其实就是axi4协议的实现程序(我大概看了下,并且简单 的分析了下,感觉可以直接拿过来使用,就是不能完全确定)。所以,想请教下大神,example_design下的axi4_wrapper能不能直接用?
小编你好,冒昧的说一下,貌似你还没把xilinx的AXI总线搞清哇。MIG里的AXI4接口是xilinx的全功能AXI总线接口,支持突发传输,所以可以将DDR3封装为该总线接口。进行封装的目的就是为了方便挂在总线互联线上供其它IP通过地址访问,而且操作简单的多了,你只需按xilinx的全功能axi4总线规范操作即可,至于地址的映射,读写仲裁什么的内部都已经做好了,完全不用你操心。你也可以封装为axi4-stream流接口,点对点的数据传输方式,所以不需要总线地址,这样的话数据吞吐率比较高,但是要自己封装,稍微麻烦些,因为要自己控制地址的映射和数据的读写,流接口就3个信号,ready、valid和data。
一般不用AXI4-LITE接口,至少我没见到有用的。AXI4-LITE是寄存器操作方式的总线接口,不支持突发传输,也就是说一次握手只能传输一个值,效率极低。xilinx的软核访问DDR3也是通过全功能的axi4总线而不是axi4-lite。仔细研究研究xilinx的axi总线规范
支持,axi lite确实不适合FPGA,因为很多core的时钟也就100多MHz,本来上G的总线,已经被用户时钟+时序开销拖到几十M,你再用axi lite这种2次握手才能传1个数据的接口,总线速率低到吐血了。
谢谢21楼,22楼大侠的意见。axi-lite效率确实很低,根本不适合我的需求。今天又和老板讨论了下,没想到转了一圈又回到了起点。经过分析,我使用的时钟是200MHz,axi4的数据位宽可以是512,甚至1024.如果按照512位来算,200MHz*512*80%(80%的效率是根据时序图大概估计的,也不知道对不对)=10GBps了,是可以达到要求的。这里小编必须批判下自己,也希望论坛各位引以为戒。拿到老板的项目应该进行需求分析,确定初步方案的时候更应该把各项指标算清楚,然后再选择最省力的方案。没想到,老板一句话我就忙着干,结果干了半天,自己只是一味的关注功能实现上,忽略的重要的需求。
之前的方案,在下周继续更新。目前先回到这个方案中:基于带有axi4总线接口的MIG做ddr3的控制器。这里需要我好好学习axi4总线,然后在基于axi4总线编写控制器,完成设计。这里在具体实现时肯定会有很多问题,欢迎各位大侠小侠过来逛逛,指点一二就更好了!
这里17楼的gransport好像做过这个,希望多指教啊!
PS:eetop 里好像有个讨论详细的讲解了axi4的一些方面,有需要一起学习的可以参考:http://bbs.eetop.cn/thread-3990-1-1.html
我是来学习的
没有用过,路过
我就写了一个AXI4全功能的主接口就搞定了,不麻烦,就是单纯的读写。
不知道你外部数据带宽是多少,一般ddr的带宽是ddr时钟 x 2 x ddr位宽,ddr的带宽是外部读写共用的,ddr的带宽利用率不太好估算,一般跟你对ddr存取方式有关,按地址顺序只写或者只读利用率最高,我以前用的同时读写不同地址,效率只有40%左右。
顶一个!
对了,忘了给你介绍个超级简单的方法,虽然axi接口对于DDR3效率不高,但是xilinx为了推行axi接口,还是提供了关于MIG的全套解决方案,以前一个FAE给我说过这个事情,怎么说呢,就是让DDR3操作变傻瓜化了吧。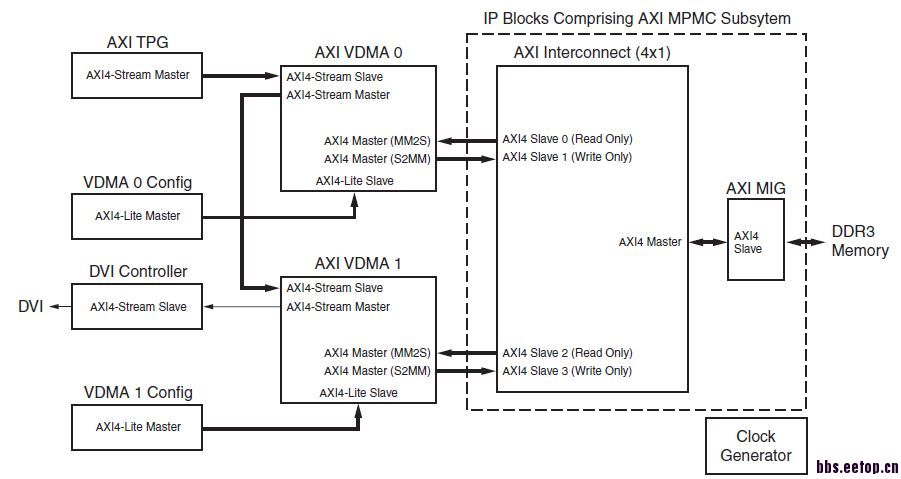
上面是xilinx的一个MIG的解决方案应用案例,如果你硬要用axi解决所有问题,那么这个傻瓜化的方法最适合你了,虚线内部就是你可以借鉴的方案,和你的老师也好解释,反正什么仲裁都被xilinx做了,对你来说,就是多个用户接口,在外部实现你的FIFO功能吧。
确实这一点手册上不好理解