对于存储器错误比特修复的优化方法
通常memory随着使用时长增加,会有一定几率有些比特单元会坏掉,从而可能会造成相关功能异常,导致系统崩溃。这种问题是因为软件读出了错误的数据,所以是可以修复的。
通常的memory都会预留备份存储单元区,用于修正制造产生的单元损坏和使用过程中产生的单元损坏,所以当检测到有某一字节有校验和错误时,只需用备份区的单元替换即可。
一般是通过CRC校验发现失效比特的位置,然后对其纠错,将纠错后的数据字节存储到事前在memory中建立好的备份存储单元区中,这样在每次读取错误字节时,用备份区的纠正后的字节替换,这样就完成了修复工作。
但是,即使通常校验工作是用硬件完成的,为了确定错误字节的位置,必须以字节为单位校验,这样是比较费时的。
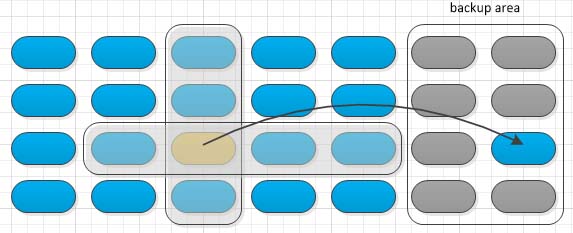
如何加速这个修复过程呢?
可以对一整块存储区划分为横纵坐标,增加校验位宽为原来的4倍,也就是说,横轴为相邻的4字节,纵轴为等间隔n个单位的4字节,进行两组校验,横纵校验的结果形成了一组坐标,用于定位错误的数据字节。虽然,增加了一组校验运算,但是由于位宽增是原来的4倍,所以整体时间是缩短了。
对于纵轴的校验计算时需要硬件支持的,所以CRC校验模块在从存储器读取数据是需要支持地址等间隔的跳跃式读取,但这应该并不难实现。

“优化”如果是correction能力的提高,CRC能力太差,应该用BCH或者更强的LDPC,并且2016的memory summit已经提出更新的算法了。至于这类模式,都是类似RAID,模式上的优化目前可能行不太大
自己并不是在存储控制方面很有经验。这个想法是之前在做SOC时,做Nand Flash里boot code的读写时想到的。只是想在这里分享探讨一下。这也是做公众号的初衷吧。谢谢批评指正!
谢谢楼上的批评指正
转载一些关于RAID的介绍
RAID全称为独立磁盘冗余阵列(Redundant Array of Independent Disks),基本思想就是把多个相对便宜的硬盘组合起来,成为一个硬盘阵列组,使性能达到甚至超过一个价格昂贵、 容量巨大的硬盘。RAID通常被用在服务器电脑上,使用完全相同的硬盘组成一个逻辑扇区,因此操作系统只会把它当做一个硬盘。 RAID分为不同的等级,各个不同的等级均在数据可靠性及读写性能上做了不同的权衡。 在实际应用中,可以依据自己的实际需求选择不同的RAID方案。
标准RAID
RAID 0
RAID0称为条带化(Striping)存储,将数据分段存储于 各个磁盘中,读写均可以并行处理。因此其读写速率为单个磁盘的N倍(N为组成RAID0的磁盘个数),但是却没有数 据冗余,单个磁盘的损坏会导致数据的不可修复。 大多数striping的实现允许管理者通过调节两个关键的参数来定义数据分段及写入磁盘的 方式,这两个参数对RAID0的性能有很重要的影响。
STRIPE WIDTH
stripe width是指可被并行写入的 stripe 的个数,即等于磁盘阵列中磁盘的个数。
STRIPE SIZE
也可称为block size(chunk size,stripe length,granularity),指写入每个磁 盘的数据块大小。以块分段的RAID通常可允许选择的块大小从 2KB 到 512KB不等,也有更 高的,但一定要是2的指数倍。以字节分段的(比如RAID3)一般的stripe size为1字节或者 512字节,并且用户不能调整。 stripe size对性能的影响是很难简单估量的,最好在实际应用中依自己需求多多调整并 观察其影响。通常来说,减少stripe size,文件会被分成更小的块,传输数据会更快,但 是却需要更多的磁盘来保存,增加positioning performance,反之则相反。应该说,没有 一个理论上的最优的值。很多时候,也要考虑磁盘控制器的策略,比如有的磁盘控制器会等 等到一定数据量才开始往磁盘写入。
RAID 1
镜像存储(mirroring),没有数据校验。数据被同等地写入两个或多个磁盘中,可想而知,写入速度会比较 慢,但读取速度会比较快。读取速度可以接近所有磁盘吞吐量的总和,写入速度受限于最慢 的磁盘。 RAID1也是磁盘利用率最低的一个。如果用两个不同大小的磁盘建立RAID1,可以用空间较小 的那一个,较大的磁盘多出来的部分可以作他用,不会浪费。
RAID 2
RAID0的改良版,加入了汉明码(Hanmming Code)错误校验。
汉明码能够检测最多两个同时发生的比特错误,并且能够更正单一比特的错误。汉明码的位 数与数据的位数有一个不等式关系,即:
2^P ≥ P + D +1
1
2^P ≥ P + D +1
P代表汉明码的个数,D代表数据位的个数,比如4位数据需要3位汉明码,7位数据需要4位汉 明码,64位数据时就需要7位汉明码。RAID2是按1bit来分割数据写入的,而P就代表了数据 盘与校验盘的个数。所以如果数据位宽越大,用于校验的盘的比例就越小。由于汉明码能够 纠正单一比特的错误,所以当单个磁盘损坏时,汉明码便能够纠正数据。
RAID 2 因为每次读写都需要全组磁盘联动,所以为了最大化其性能,最好保证每块磁盘主 轴同步,使同一时刻每块磁盘磁头所处的扇区逻辑编号都一致,并存并取,达到最佳性能。 如果不能同步,则会产生等待,影响速度。
与RAID0相比,RAID2的传输率更好。因为RAID0一般stripe size相对于RAID2的1bit来说 实在太大,并不能保证每次都是多磁盘并行。而RAID2每次IO都能保证是多磁盘并行,为了 发挥这个优势,磁盘的寻道时间一定要减少(寻道时间比数据传输时间要大几个数量级),所 以RAID2适合于连续IO,大块IO(比如视频流服务)的情况。
RAID 3
类似于RAID2,数据条带化(stripe)存储于不同的硬盘,数据以字节为单位,只是RAID3使用单块磁盘存储简单的 奇偶校验信息,所以最终磁盘数量为 N+1 。当这N+1个硬盘中的其中一个硬盘出现故障时, 从其它N个硬盘中的数据也可以恢复原始数据,当更换一个新硬盘后,系统可以重新恢复完整 的校验容错信息。
由于在一个硬盘阵列中,多于一个硬盘同时出现故障率的几率很小,所以一般情况下,使用 RAID3,安全性是可以得到保障的。RAID 3会把数据的写入操作分散到多个磁盘上进行,不管是向哪一个数据盘写入数据, 都需要同时重写校验盘中的相关信息。因此,对于那些经常需要执行大量写入操作的应用来 说,校验盘的负载将会很大,无法满足程序的运行速度,从而导致整个RAID系统性能的下降。 鉴于这种原因,RAID 3更加适合应用于那些写入操作较少,读取操作较多的应用环境,例如 数据库和WEB服务器等。