实时相关算法的FPGA实现
可以设计成pipeline,data可以用两个memory(这里用FIFO说明)串联缓存:计算乘积累加用FIFO_A流水计算,计算完后data写入FIFO_B,得到比较结果后再看是否需要将FIFO_B中的数据写入到RAM,需要就写入不需要就清空。end.
你好harry_hust, 如果用memory进行缓存的话,无法做到一个clk访问所有的缓存数据(L个数据),所以,求出一个product_sum,即使用pipeline的话,也会需要很多周期。而data数据一直在推送,恐怕前后速率上无法达到匹配。
这L个数据也是同时输入FPGA的吗?(我个人认为应该不会是同时给进来的,没有这么多的接口。) 其实实时计算并不是说不能有延迟,或者延迟只有1个cycle,只要满足指标要求都是实时的。
另外,L个数据同时计算也带来很大的功耗,如果码率很大的话还得考虑散热问题。
所以我觉得这个应该还可以进一步优化。
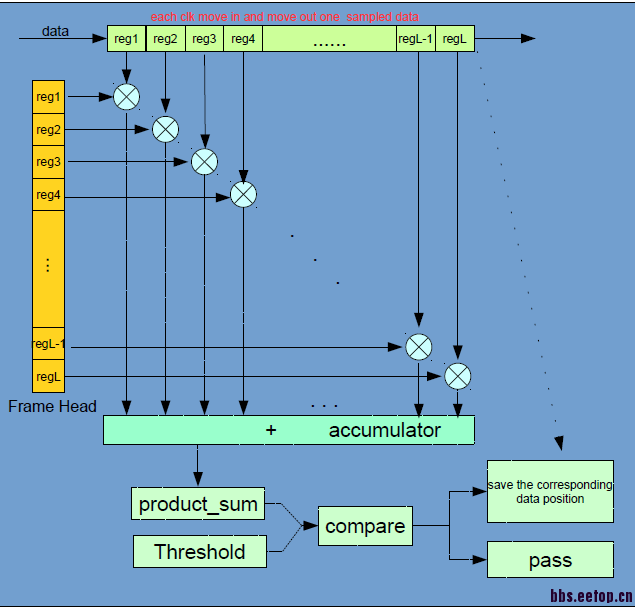
事实上,我上面提到的data数据已经是FPGA内的数据,data数据从前面的一个模块输出到这个相关算法的处理模块。简单的说,这个算法就是要从这个data数据流中找到一个固定长度(L),每一帧数据的帧头(是否找到就是用上面图中提到的方法进行判决)。 这个算法也可以形象的描述为:有一个固定长度的窗(如我上面说的长度为L的寄存器组),而且这个窗是固定的,而data数据是随clk不断流经这个窗的,每走一个clk周期,这个窗里的数据是不断更新的(移位过程)。 因为不知道帧头到底什么时候会出现,那么,就需要在每一次窗里的数据有更新时,都进行判决确认。
还有就是,你提到的实时计算允许有一定的延时,只要满足指标就行。 这我是同意的, 但就这个算法来说,data数据的数据率大概在25MHz/s,之前,我也有考虑按你上面提到的方法进行处理,用memory进行数据缓存,但考虑到memory每个cycle 只能读写一次,而且无法做到我上面提到的数据移位操作, 那么无论用不用pipeline,都会拖慢处理速度(因为我觉得算法的特性在于多数据的同时处理,而memory虽可以用于缓存,但是它使得数据的读写变得串行化,所以感觉有些不匹配。个人见解~)。
关于L个数据同时计算,这是我最先考虑到的实现方式,但正如你所说,同时计算在实现时会带来大功耗问题、散热问题及FPGA布局布线资源大量消耗的问题(因为做个东西不是用于实际的产品,而是带有一定的实验性质的,所以更关注能否实现。),所以,这样做(我暂时想到的寄存器组)的话,最担心的就是布线资源不够用。 从目前程序的综合结果来说,感觉还是有些问题,没有综合出想要的structure。 当然,鉴于水平有限,可能还是有理解不到位的地方。 所以欢迎高手能提出不一样的见解!
照你所说,那L个乘法是不可避免了,累加也不可避免会有(1+2+...+2^(L-1))个加法。 如果资源足够的话,你可以将data寄存N级(N为乘法开始到compare结束的cycle数),这样也可以流水了。
另外,如果仅是实验用的话,可以仅做仿真,而不必到FPGA上跑。
希望这些对你有帮助。
几百个乘法器。,帧头不是固定数,那计算量很多啊
挺复杂,学习一下,多谢了
嗯,计算量是很大。
嗯,正在尝试用流水线去做。 还有就是,这个虽然是实验性质的,还是有具体实物系统的,只是目前主要考虑系统的实现,对成本和功耗不是那么敏感~