关于RTL中Feedthroughs的问题
A-B-C,如果在一个clock周期内,A直接到C,就是feedthouhs。
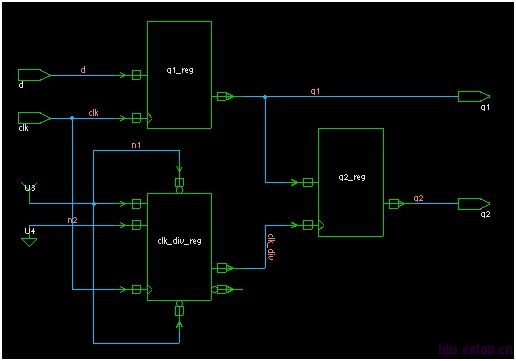
其中,它提到一个例子,
always @(posedge clk)
q1<=d;
always @(posedge clk_div)
q2<=q1;
always @(posedge clk)
clk_div<=~clk_div;
这种情况下,有可能d直接到q2,发生feedthougs现象。如果将clk_div改为阻塞赋值,就不会发生feedthoughs现象。
可是我将这里个代码综合后结果一样,有谁帮我解释下 到底feedthoughs是什么,对RTL设计有什么影响。

没人回答,还是没问清楚
不要轻易地用前一级的输出作为后一级的clock。
实际电路中,clk_div肯定比clk有延迟。
如果做得不好,clk_div到达后一级的延迟有可能比q1到达下一级的延迟要大。
这种情况下,clk上升沿使d传播到q1,并使clk_div产生上升沿。
而由于clk_div的延迟更大,所以刚到达下一级的q1立刻在clk_div的上升沿下被送到了q2端。
我理解这应该就是你说的Feedthroughs问题。
DC综合应该极有可能综合出一样的电路。
但是simulation的话由于非阻塞赋值的原因以及仿真时间队列流,clk_div的上升沿肯定在clk上升沿之后,因此会产生feedthrough。这回产生simulation和综合的mismatch。
有机会可以做个小实验试一试。
仿真了一下,果然会发生所谓的feedthrough啊。
module test1(clk,d,rstn,q2);
input clk,d,rstn;
output q2;
reg q2,q1;
reg clk_div=0;
always @(posedge clk)
q1<=d;
always @(posedge clk_div)
q2<=q1;
//always @(posedge clk)
always @(posedge clk or negedge rstn)
if(~rstn) clk_div<=1'b0;
else clk_div<=~clk_div;
endmodule
`timescale 1ns/1ns
module tb;
reg d,clk,rstn;
wire q2;
test1 u_test1(clk,d,rstn,q2);
initial begin
$fsdbDumpfile("test1.fsdb");
$fsdbDumpvars;
d=1'b0;
rstn=1'b1;
#7 rstn=1'b0;
#10 rstn=1'b1;
#1 d=1'b1;
#20 d=1'b0;
#10 d=1'b1;
#20 d=1'b0;
#20 d=1'b1;
#10 d=1'b0;
#100 $finish;
end
initial begin
clk=0;
forever #5 clk=~clk;
end
endmodule
如果用阻塞赋值写clk_div的话,clk_div先于q1之前更新,然后产生了一个clk_div的上升沿,会触发q2的更新,可能clk和clk_div的上升沿可以认为是同一时间点,这样q1和q2同时更新,所以不会产生feedthrough。
只是猜测。
当使用分频后的子时钟(divide clock)去取样源时钟(source clock)的数据(data),不可避免的会出现馈通现象(feedthrough phenomenon),也可能会出现时序违约(timing violation),除非对某一条路径做延迟处理,加入足够的延迟单元(delay cell)或者缓冲器(buffer)
这个是个好帖子啊,留名观看……
感觉用阻塞赋值是自欺欺人,只是让仿真通过而已,不能解决实际的问题
我有种大胆的想法,用~clk_div做下一级clk, 实际电路就是不会馈通,因为设计时Q1的变化频率肯定低于clk_div,这样实际采样就是在Q1的中间点
通常在写rtl的时候会加一个delta延迟,可以有效的避免各种时序竞争。如果不加目,前的仿真器也能处理这个问题。
而实际情况是,clk_div和clk是同源的,工具会balance时钟树使时钟的有效沿在同一时刻到达每个寄存器。
不管怎么样,在任何情况下,时序语句是一定不能使用阻塞赋值的。
请教:
用的VCS是比较新的版本,应该是2011-03,还是出现了feedthrough问题,是不是恰恰说明,仿真器不能处理这个问题?
即使综合工具去平衡时钟树,还是会因为feedthrough问题产生了综合前后仿mismatch。
最后一句,虽然一般在coding时会采用时序逻辑用非阻塞,但是很多书籍资料都表明只要不产生mismatch,阻塞也可用于时序逻辑。
看你其他的帖子应该是有丰富经验的工程师,请发表一下你的看法吧。
在同源但是分频前后(或门控前后)的时钟域间,做信号穿越时确实会仿真出这种情况。
应该是仿真器无法自动在这二者直接加delay的原因,所以针对仿真根本的解决办法是在写RTL的时候加delay模拟延迟。
在实际布局布线后本身就会有这个延迟,所以一般没有问题,但也要通过后仿来确认。
规则越简单越好,针对小编的情况如果允许使用阻塞赋值,那么就会出现无数种情况也能允许阻塞赋值,这样一来规则会越来越复杂,最终结果就是不允许使用阻塞赋值的这个规则形同虚设。
阻塞赋值和非阻塞赋值的混用的另外一个问题就是会在coding style检查中带来大量的错误信息,而你必须要手工分析那些是那些是合法的哪些是由于笔误造成的。
有一句名言大概意思就是,解决一个问题总会有一种方法是这样的简单有效,结果却是谬之千里。
那要根据不同的reg<= #delay reg_nxt加delay了?
如果同一个delay,q2和clk_div还会有相同的跳变沿。
clk_div就不加delay了,时钟再加delay会造成更多的问题。
我问的问题是,书上的例子说使用非阻塞会出问题,使用阻塞赋值就能解决,但是我综合后结果一样,完全没有解决馈通现象
你怎么保证和综合出来的一致。
还是别讨论了。没啥意思啦。
综合工具会忽略掉所有delay,而且从综合到最终的物理实现,中间差了N个步骤。综合之后的电路本来就不能work!
因为时钟传播也是要花时间的,所以即便是同一个时钟到达不同寄存器的时钟端的时间也是不同的,所以需要工具来balance时钟树,使得时钟到达每个寄存器的时间的最大误差在允许范围内,所有同源时钟被认为属于同一个时钟网络,只不过时许电路会切断network的传播,所有指定分频时钟的时钟源。所以,在你看来无比困扰的feedthrough,在物理实现时根本就不是问题。
所以,不管有没有分频时钟,物理实现的时候都会在时钟树上加buffer,为了满足setup和hold time的要求(以满足hold time为主),数据通路上也会相应的插入大量的buffer。
有些人基本不了解电路知识,不知道什么是物理实现(以为综合之后就是最终电路),所以会在这个问题上不断纠结。前面有很多人都给出了解决办法,相信这个问题已经解释的相当清楚了,如果还是不理解,自己看书!
bingo~
markmark