请问如何阐述“并行设计”中的“面积”“时间”“功耗”的tradeoff
刚刚接触“并行化,但是不久就要做个presetation。
请大侠帮我看看,我以下的想法方向对吗?有哪些地方可以引申和扩展的吗?
或者请推荐一些书或者文章。
如下图所示:
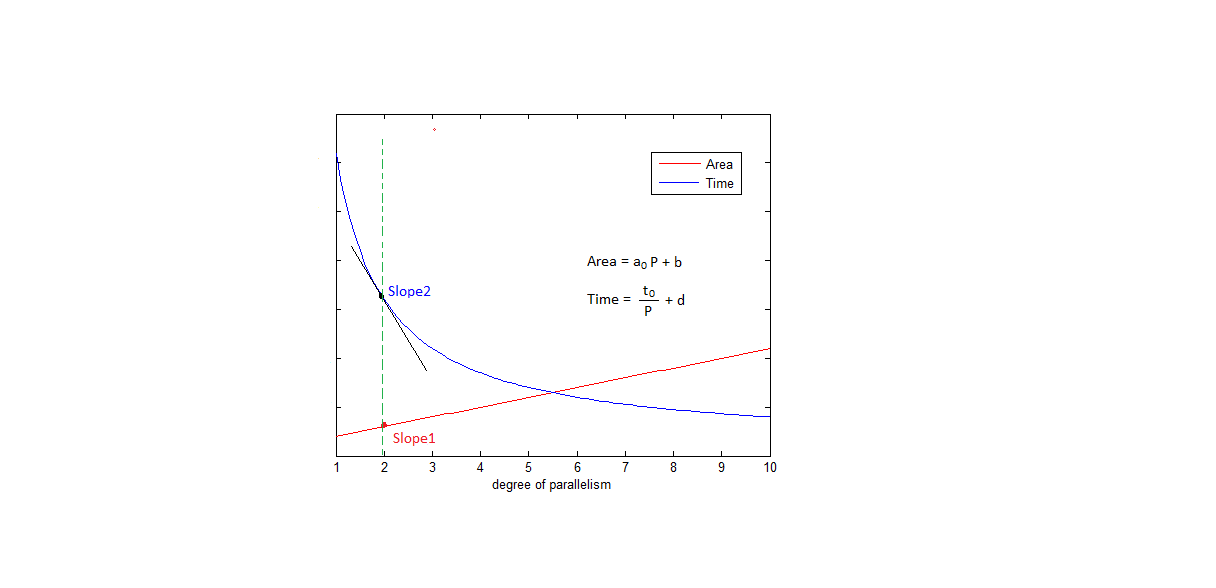
横轴并行功能模块的数量(P),红线表示面积(Area)随着并行度的增加而线性增长(理想化处理,忽略增加的routing);
蓝线表示时间(Time)随着并行度的增加而减小,是个反比例函数。(总的工作量一定)
其中a0是单个功能模块的面积,
t0是单个功能模块处理这么多数据所用的时间。
Slope1 和Slope2分别是两条线的斜率。
我把设计要求定为:|Slope2|的值
大于等于|Slope1|的值的K倍,算是“划算的并行化”,
并在图中找到满足|Slope2|=k|Slope1|的点(P)作为“并行数量”的上限。
流水和单元复制都可以认为是并行化。
吞吐率和延时也都是“时间”方面的度量。
把这四个因素之间的关系考虑清楚,这个问题就解决了。
小弟目前处境:新手,感觉VLSI这一行的术语太多,有的时候大概明白点儿事儿了,却
不知道应该如何学术地表述。
我对parallel的理解,先不提流水线,就是把硬件功能模块增加,用面积来换吞吐量。
我对scalability的理解,就是按照这个设计思路,很容易把更多的硬件模块装进来,
然后吞吐率相同倍数的增加(如果throughput增加,却慢于面积的增加,就是不
scalable)
不知道以上理解对不对。
现在我想描述一个技术,但是不知道用什么术语来说:
比如输入是x1, x2,x3,x4.....xm (m个数),计算任务是先得出一个 m by m的方矩
阵,然后通过这个矩阵来算其他的东西,矩阵的元素是 f(xi,xj)。
所以总的计算量是m的平方(不考虑矩阵的对称性)。
我们可以用一个f(xi,xj)模块,进行2层循环,这样速度最慢,面积最小;
有的文章用 m 个改进的f模块,一次性地把 m 个输入量(x)都处理了,当然,这
种设计就是为了发论文,m 都不敢很大,而且硬件约束只能允许你处理 m 个数(这一
点还不如串行的设计呢)但是这种文章的关键词都是:parallel 和 scalability。
我目前找到的算法就是把x1, x2, x3, x4, x5....分成两组,然后分别用2个F模块
分别独立地计算,然后将计算结果高效合并。相比于刚才讲的parallel我感觉这才算是
真正的divide and conquer呢。
但是我真的不知道要怎么来描述第三种设计,也是parallel和scalable?
我相信我说的这种divide and conquer的方案不是什么新奇的东西,但是我就是不会说
,不知道怎么来学术地阐述这个东西。
学习了
我理解你这里面最基本的问题是这个。
处理矩阵的运算部件的个数。
有两个极端情况。
1个或者m*m个。
其他任何情况,都在这两个端点中间。
或者说,其他任何情况,都是对运算部件个数在总体面积,计算效率上的取舍。
所以你考虑取舍的时候,第一个表的横轴上,应该是运算部件的个数,从1取到m*m。
有了这个横轴后,你可以做。大概2到3套表。
每一套包含三个子图。
第一套这么做:
运算部件按方阵方式增长(1*1,2*2,3*3,...,m*m)。
三个子图的纵轴分别是面积,功耗,时间(可以单独考虑吞吐率,延迟,时钟频率,如果全做,总共可以有5个子图)。
第二套这么做:
运算部件按行增长(1*m,2*m,...,m*m)。还可以稍微细一点,每一行细分成(1/2)m,(1/3)m之类的。
子图和上面一样。
这几套图主要是看你某种配置方式上的变化。
比如你按方阵配置。
这里面“配置方式”最重要,不同的配置方式应该在对数据的计算方式上有较本质的不同。我不知道你到底算什么,怎么算,所以只能说到这。
上面只说了两套,还可以有一套,是运算部分采用比数据采样部分速度更高的时钟。
时钟不可能无限高,根据具体情况,做个2倍到3倍之类的。横轴还可以是部件个数。
至于你说的名词,其实有些名词是可以用在不同场合的。不同场合需要对名词加限定,或者给一个解释。
我不知道你在描述什么,所以没有建议可提供。
只有一条建议,看论文,看书要看国外最顶级的杂志,最顶级的作者的文章和书。
其他的,可以认为是厕所手纸。垃圾论文的作者可能还不如你明白呢。
多看好文章,做研究的前提。
最关键的是把事情描述清楚。
用对名词只是其中一个步骤。