关于多位的数据选择器
小弟我最近分别用连续赋值和过程块写了2个很简单的数据选择器,选择端是2bit的,综合出来的RTL Viewer不一样,但我看时序分析完全一样。这2种写法综合出来的电路是不是一样的呀?只是RTL Viewer看到的不一样?
- module temp_2(
- input [1:0]sel,
- input a, b, c,
- output out
- );
- assign out = (sel == 2'b00) ? a :
- (sel == 2'b01) ? b :
- (sel == 2'b10) ? c : 0;
- endmodule
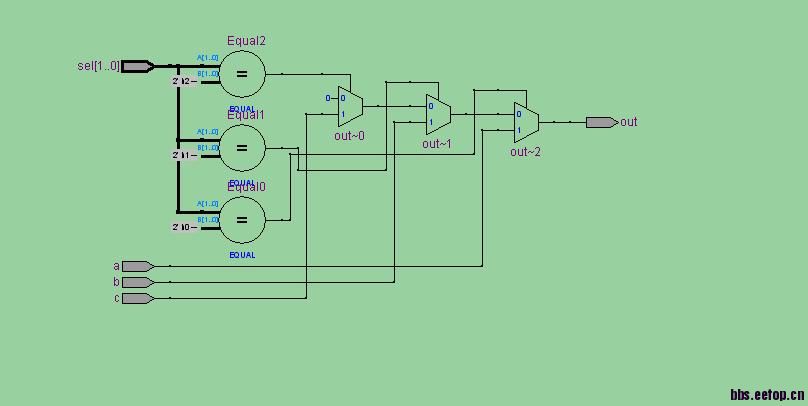
RTL Viewer图如下
另一种是用过程块写的:
- module temp(
- input [1:0]sel,
- input a, b, c,
- output reg out
- );
- always @(*) begin
- case (sel)
- 2'b00 : out <= a;
- 2'b01 : out <= b;
- 2'b10 : out <= c;
- default : out <= 0;
- endcase
- end
- endmodule
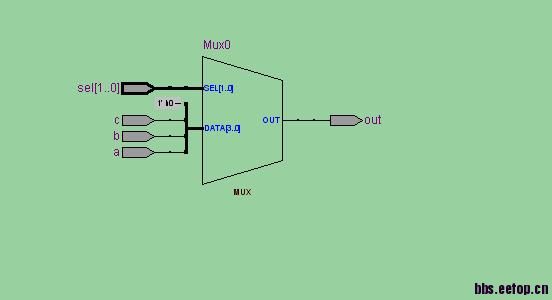
RTL Viewer图如下:
[attach]377857[/attach]
把第二个方法中的非阻塞赋值改为阻塞赋值应该就一样了
这个电路时组合电路,没必要用非阻塞
这个问题很经典。
正是经常用的一个考题,verilog里面用if else写出来的代码和case写出来的同样逻辑功能的代码,综合出来有什么不一样。
第一种写法相当于if else的方式,具有优先级,所以和case写出来的不同,RTL图正好对应。
仔细看一下RTL视图,第一个RTL视图里面是有优先级的,第二个RTL视图里面没有是并行的,没有优化级的概念。
正好和if-else,case语句对应
谢谢你的回复!
我把非阻塞改成阻塞之后综合出来的效果还是一样的呀。并没有什么改变。
另外,如果我对组合电路用非阻塞的话会出现什么问题吗?我觉得对于组合电路阻塞和非阻塞应该是一样的。不知我的想法对不?
谢谢你的回复!
if-else-确实是由很多级二选一的数据选择器起来的,但我查过case的语法,夏宇闻的那本书上说执行完case分项后的语句之后,跳出该case语句结构,终止case语句的执行。相当于也是变形的if-else语句,也就是说,我把case语句块里面的任意2行交换的话,优先级就不同了。
另外,我对比过2种写法的综合效果,综合出来的pin-to-pin的延迟完全一样,毫无差别。所以我猜想是不是2种写法生成的硬件结构是一样的呢?
谢谢你的回复哈!
那这个问题的答案是啥?不一样?不过虽然表面上电路结构不一样,但我综合出来的pin-to-pin延迟却完全一摸一样,具体情况还请看我9楼的回复。不知我说的对不对?
谢谢你的回复!
这位高手也请你看我9楼的回复,不知我说的对不对?
1. if-else条件写全后和full-case应该是等价的,现在的综合器都会自动选择,是使用有优先级的(延迟大资源少)还是使用无优先级的(延迟小资源大)。
2.在RTL VIEW里面,是看不到最终FPGA的映射结果,只是纯粹的HDL到RTL图的映射。实际如果用ASIC实现,既有可能综合成前一个,也有可能综合成后一个。
3.在FPGA内,无论前一个还是后一个,都是用LUT表实现的,所以pin2pin的延迟一样。
the difference between 'if else' and ' case'
你这个是应用于FPGA的。就这个流程来说,我的分析如下(不一定完全正确,仅供参考)
1. 这两种写法都是完全合法的,实际上综合结果很明显会不一样的,这个是肯定的。if else的结构延迟会大一些的,毕竟是优先级编码。
2. 最后你看到的pin-to-pin延迟一样。很可能是因为FPGA综合后的优化动作,现在综合的工具也不是傻子,很智能的,它会根据你写的时序约束要求,优化你写的代码。将map之后的网表(你可以参考technical view,虽然不完全准确)优化到你时序约束的样子。所以,你看到的延迟是优化之后的。也许综合器(如quartus)帮你做了综合优化。
最后,需要强调的是,为了尽量减少综合器优化的代价,还是利用case来降低系统延迟,提高设计性能。这个是比较好的设计习惯。
综合器优化的代价有:
1. 综合和后端时间比较长,特别是时序约束比较紧(速度快)。
2. 综合器优化有些就事论事,或者说,比较笨,它只会根据自己的规则来做。而不会具体的设计具体分析。
谢谢你的回复哈!现在大概明白了!
谢谢你的回复哈!现在大概明白了!