交通标志识别实现98%准确率,只因使用了深度学习算法?
在论文中,作者根据层类型的不同应用不同概率值进行丢弃。因此,我决定采用类似的方法,定义两个级别的dropout,一个用于卷积层,另一个用于完全连接层:

此外,随着进入到更深层次的网络,作者逐渐开始采用更积极的dropout值。所以我也决定这样:

这样做的原因是,我们把网络看作是一个漏斗,当我们深入到层中时,希望逐渐收紧它:我们不想在开始的时候丢弃太多的信息,因为其中的一些相当有价值。此外,在卷积层中应用MaxPooling的时候,我们已经失去了一些信息。
我们尝试过不同的参数,但最终结果是_p-conv = 0.75_和_p-fc = 0.5_,这使得我们可以使用3x3的模型在归一化灰度图上实现97.55%的测试集准确率。有趣的是,我们在验证集上的准确率达到了98.3%以上:


引入dropout算法后,在灰度归一化图像上的模型性能
上面的图表显示,这个模型更为_平滑_。我们已经在测试集上实现了准确率超过93%这个目标分数。下面,我们将探索一些用于处理每一个点的技术。
直方图均衡化
直方图均衡化是一种计算机视觉技术,用于增强图像的对比度。由于一些图像受到了低对比度(模糊、黑暗)的影响,因此我们将通过应用OpenCV的对比度限制自适应直方图均衡来提高可视性。
我们再次尝试了各种配置,并找到了最好的结果,**测试精度达到了97.75%**,在3x3的模型上使用以下dropout值:_p-conv = 0.6_,_p-fc = 0.5_。

尽管做了直方图均衡化,但有些图像仍然非常模糊,并且有些图像似乎是失真的。在我们的测试集中没有足够的图像示例来改进模型的预测。另外,虽然97.75%的测试准确率已经相当不错,但我们还有另外一个杀手锏:数据增强。
数据增强
我们在早些时候曾经发现,43个种类的数据明显不平衡。然而,它似乎并不是一个棘手的问题,因为即使这样,我们也能够达到非常高的准确度。我们也注意到测试集中有一些图像是失真的。因此,我们将使用数据增强技术来尝试:
扩展数据集,并在不同的照明条件和方向上提供其他图片
提高模型的通用性
提高测试和验证的准确性,特别是对失真的图像
我们使用了一个名为imgaug的库来创建扩展数据。我们主要应用仿射变换来增强图像。代码如下:
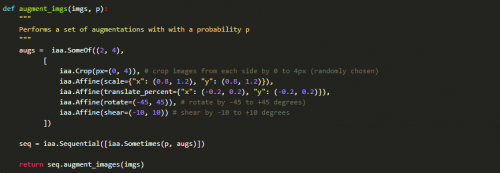
虽然种类数量的不平衡可能会在模型中引入偏差,但我们决定在现阶段不解决这个问题,因为这会导致数据集数量的增加,延长训练时间。相反,我们决定为每个种类增加10%的图像。我们的新数据集如下。

图像的分布当然不会发生显著的变化,但是我们确实对图像应用了灰度化、直方图均衡化,以及归一化等预处理步骤。我们训练2000次,附加dropout算法(_p-conv = 0.6_,_p-fc = 0.5_),并在测试集上达到**97.86%的准确率:**
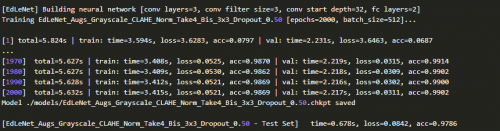
这是迄今为止最好的结果!!!
但是,看看训练集上的损失指标,0.0521,我们很有可能还有一些改进的空间。未来,我们将执行更多的训练次数,我们会报告最新成果的。
结论
本文探讨了如何将深度学习应用于分类交通标志,其中包含了各种预处理和归一化技术,以及尝试了不同的模型架构。我们的模型在测试集上达到了接近98%的准确率,在验证集上达到了99%的准确率。你可以在这里访问代码库。
- 安森美CCD图像传感器增强性能应用于智能交通、监控、医疗成像及工业检测(06-17)
- 物联网要发展,知识产权是关键!(09-08)
- 无传感器,不智能(03-03)
- 这家上了央视的传感器厂商,搞出个地磁传感器号称要大闹智能交通(02-10)
- 见证地磁传感器是如何让长江大桥变“聪明”的(03-12)
- 安森美增添4款高分辨率器件到获奖的PYTHON CMOS图像传感器系列(09-16)