Turbo编码器提升毫微微蜂窝DSP的效率
最近,小型毫微微蜂窝基站概念在移动应用中越来越受欢迎。与传统宏蜂窝相比,毫微微蜂窝在覆盖范围、兼容性和成本方面都具有优势。
由于成本和性能的制约,毫微微蜂窝设计必须具有与宏蜂窝大致相同的模块化水平和复杂度,并且与个人而非社群的经济承受能力相适应。
但是,为了实现至少与传统宏蜂窝系统相同的信号强度,毫微微蜂窝必须采用支持高达14.4 Mbps比特率的多通道设计。因此,设计人员面临着严峻挑战:利用系统的数字信号处理(DSP)引擎编码多通道比特流,同时为系统的其它关键操作提供足够的计算裕量。
本文介绍如何实现基于Turbo编码的高效算法以支持基于Blackfin的14.4 Mbps 3G毫微微蜂窝设计,该设计仅消耗Blackfin可提供的600 MIPS计算能力中的100 MIPS,从而为系统的其它必要操作留下了充沛的资源。
Turbo码性能卓越,因此自1993年推出以来,便在业界和学术界引起了极大的关注。Turbo码的工作效率几乎达到了香农所确定的信道容量极限,信噪比(SNR)间隔小于或等于0.7dB。
Turbo码最初由Berrou、Glavieux和Thitimajshima提出1,它是利用两个并行级联的卷积编码器构建而成。在Turbo编码方案中,同一信息序列的不同交织版本上产生两个分量码。在解码器端,使用两个最大后验概率(MAP)解码器以迭代方式解码判决结果。MAP解码算法使用接收到的数据和奇偶校验符号(对应于根据真实和交织形式的数据位计算而来的奇偶校验位)及其它解码器软输出(外部)的信息,产生更可靠的判决结果。
关于Turbo码的高效解码,学术界已提出了许多算法和实现技术,但有关如何高效实现Turbo编码器以支持高比特率应用的技术则不多见。在基站等应用中,一次须传输多个数据流。因此,必须高效实现Turbo编码器,使之能以较少的处理能力编码多个比特流。
毫微微蜂窝的服务对象是个体而非群体,因此用户将拥有专属的无线基础设施,能够为其所有移动设备提供良好的信号强度。就数据处理而言,宏蜂窝与毫微微蜂窝的模块和复杂度大致相同。但是,毫微微蜂窝设计的目标用户是个人而非群体,所以应做到价格低廉。因此,在毫微微蜂窝设计中使用多个昂贵的处理器件并不现实。本文并未阐述毫微微蜂窝完整架构的细节,但在讨论用于无线网络纠错功能的3G标准2 Turbo编码时,已特别注意了毫微微蜂窝设计的预算要求。
3G Turbo编码器的实现
Turbo编码器主要包括两个成分编码器,一个交织器将二者隔开。3G Turbo递归系统码(RSC)编码器的原理框图如图1所示。每个RSC编码器均包括一个传递函数为(1+D+D3)的正向通道和一个传递函数为(1+D2+D3)的反馈通道。每个输入的交织地址产生过程参见3GPP的论文2。利用双MAC(乘法累加器)DSP(如Blackfin等)无法即时计算交织地址,除非我们有许多计算单元。
3G Turbo递归系统码[RSC]编码器
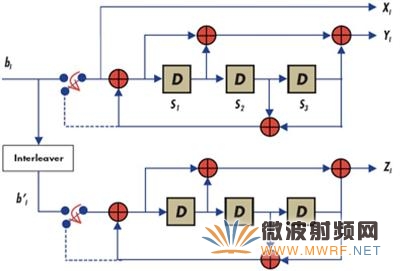
图1.
通常是预先计算交织地址,并将其存储在存储器中。存储的交织地址可以用于Turbo编码和解码。如果码字很大,则预计算的交织地址存储在L3存储器中,否则存储在L1存储器中。对于更大的码字,我们使用窗口方法编码或解码各位,并使用直接存储器访问方法根据需要从L3传输数据(如输入和交织地址等)。
由图1可知,对于每个输入,我们输出一个系统位Xi和两个奇偶校验位Yi和Zi。这里,奇偶校验位Zi并不直接取决于实际输入位bi,而是取决于交织缓冲器中索引为i的位b'i。给定N位的输入消息块B时,我们或者执行地址计算,从块B获得各输入位索引的交织位b'i,或者立即执行整个块B的交织,并存储为交织块B',然后用索引i线性访问b'i。请注意,根据3G标准计算交织位地址并非易事,因此,我们倾向于在开始编码多个消息数据块之前,预先计算所有N位的地址,并将其一次性存储在存储器中。这样,我们就能忽略Turbo编码产生交织地址的复杂性。
简单编码。在简单编码中,我们逐位编码。对于每个输入位,我们输出三位。模拟RSC编码器的一段C代码样例如表1所示。通常,输入数据位以8位字节的形式从存储器存取,因为处理器可以从存储器存取的最小数据为一个字节(或一个8位量)。获得一个字节的数据后,为了逐位进行编码,必须拆包各位,每位需要大约1.125周期(总共9个周期:使用Blackfin rot指令,第一位拆包需要2个周期,其余各位需要1个周期)。然后,编码此位又需要7个周期,因为编码仅涉及到序列化操作。完成编码后,必须将编码位封包,并存储在存储器中,以便进行其它处理和传输。数据封包所需的周期数与拆包相同,即每位1.125周期。因此,编码1位数据并
- 射频模拟前端在毫微微蜂窝基站中的应用(04-01)